




Lucene全文检索,它是apache公司研发,用于开发全文检索引擎的工具包。
Lucene开发要使用JDK1.7,高版本要使用1.8。
步骤
1、到官网下载jar包
下载地址:http://archive.apache.org/dist/lucene/java/ 可以找到所有版本
2、导入jar包
Lucene包,可以在版本包中找到
在Lucene开发中会用到文件操作,所以导入了相关依赖包

3、Lucene开发
代码部分不过多讲解,粘贴一段代码自己领悟
package com.lucene;
import java.io.File;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
public class LuceneManager {
/**
* 以下代码为创建索引并将索引和文档信息写入索引库
* @author BL
*/
@Test
public void addIndex() throws Exception{
//1、指定索引库的存放位置Directory对象
Directory directory = FSDirectory.open(new File("E:\\lucene-temp\\index").toPath());
//2、指定分析器,对文档内容进行分析
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//3、创建IndexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//4、获取目录文档并循环处理
File files = new File("E:\\lucene-temp\\files");
File[] listFiles = files.listFiles();
for (File file : listFiles) {
//5、创建Document对象
Document document = new Document();
//6、创建Field对象
//创建“文件名称”Field对象(TextField设置为分析、索引、保存)
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
//创建“文件大小”Field对象(StoredField设置为不分析、不索引、仅保存)
String file_size = FileUtils.sizeOf(file) + "";
Field fileSizeField = new StoredField("fileSize", file_size);
//创建“文件路径”Field对象(StoredField设置为不分析、不索引、仅保存)
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
//创建“文件内容”Field对象(TextField设置为分析、索引、保存)
String file_context = FileUtils.readFileToString(file);
Field fileContextField = new TextField("fileContext", file_context, Store.YES);
//7、将Field对象添加到Document对象中
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContextField);
//8、将Document对象添加到IndexWriter对象中并创建索引,然后将索引和Document对象写入索引库。
indexWriter.addDocument(document);
}
//9、关闭IndexWriter对象
indexWriter.close();
}
/**
* 索引库查询索引
* @author BL
*/
@Test
public void getIndex() throws Exception{
//1、创建Directory对象,就是索引库的存放位置
Directory directory = FSDirectory.open(new File("E:\\lucene-temp\\index").toPath());
//2、创建IndexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
//3、创建indexSearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4、创建TermQuery对象,指定查询的域和查询的关键字
Query query = new TermQuery(new Term("fileName","txt"));
//5、执行查询,需要指定Query对象和要查询的条数
TopDocs topDocs = indexSearcher.search(query, 2);
//6、返回查询结果,遍历查询结果并输出
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
//根据文档ID获取到Document对象
Document doc = indexSearcher.doc(docID);
System.out.println(doc.get("fileName"));
System.out.println(doc.get("fileSize"));
System.out.println(doc.get("filePath"));
System.out.println(doc.get("fileContext"));
}
//7、关闭IndexReader对象
indexReader.close();
}
}
4、执行Lucene代码
执行Lucene代码后,会在指定索引库的存放位置中生成一些索引文件,见下图。
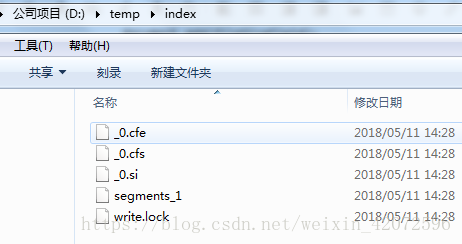
5、使用Luke工具查看
Luke工具是查看Lucene索引的可视化工具
选择指定索引库的存放位置,如下图;
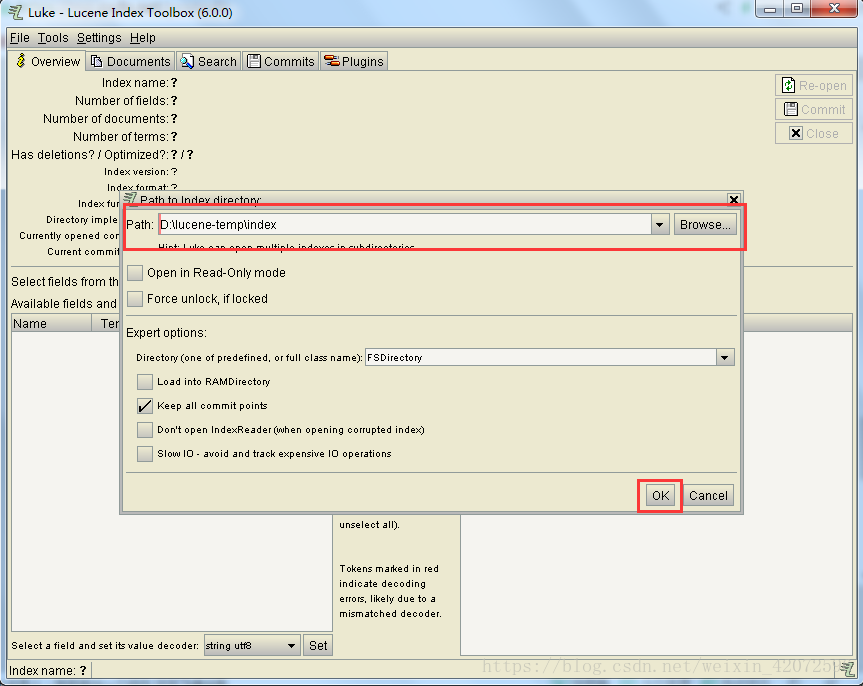
进入主页面,可查看索引信息。
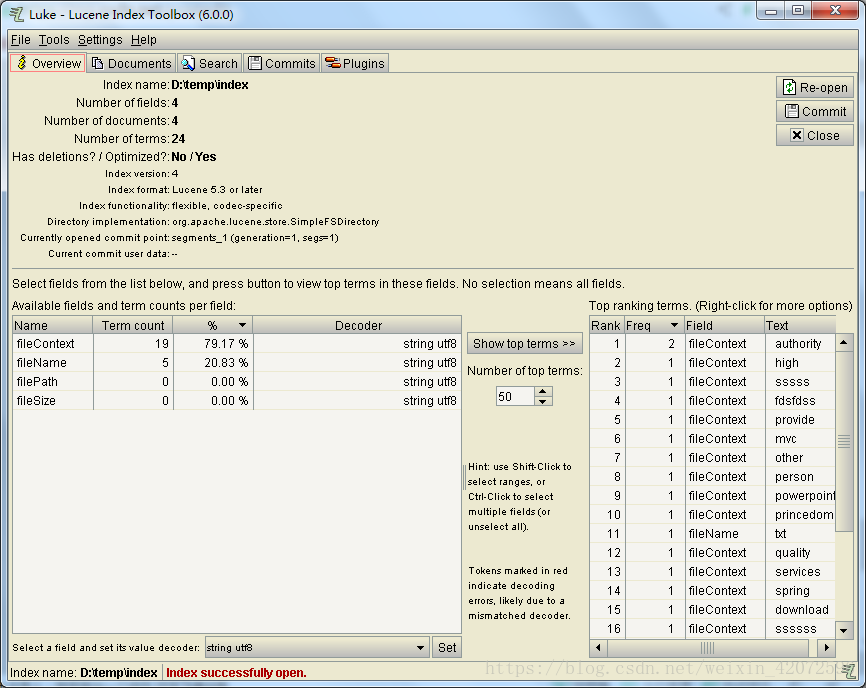
到这里Lucene的整体开发流程就已完成。
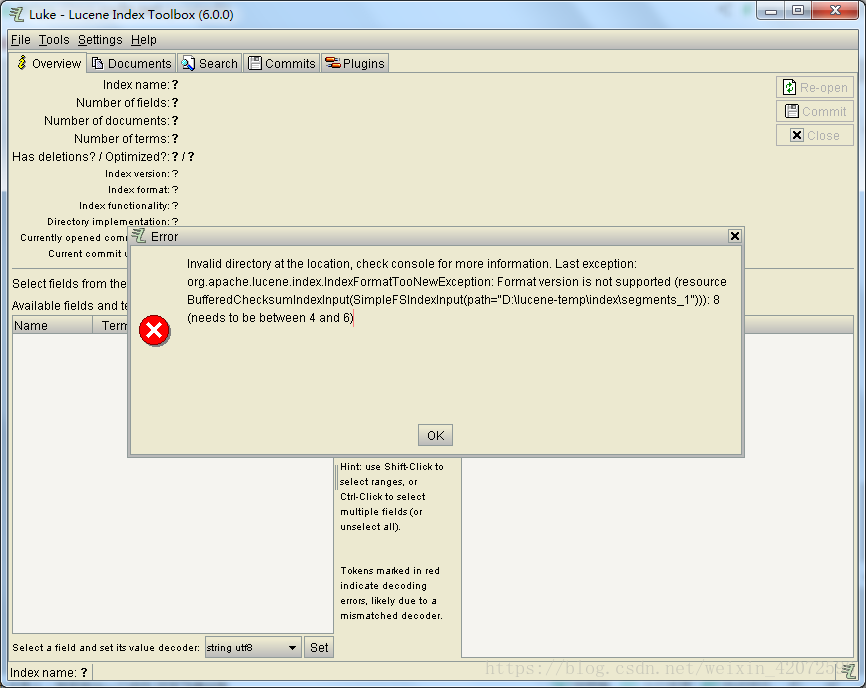
注意:Luke版本和Lucene版本必须要一致,不然打开Luke工具时会报错,错误如下图。

















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









