一、MySQL数据库总结
MySQL学习思维图
我们在接触任何技术时,首先要先明白其技术点是干什么,主要是解决一个什么样的问题,如何去使用和优化等,再会去结合真是业务场景中出现的问题“ 对症下药“,才能够去真正的解决问题,那对应MySQL专题,我们也是结合这种体系来总结学习,如下图示:
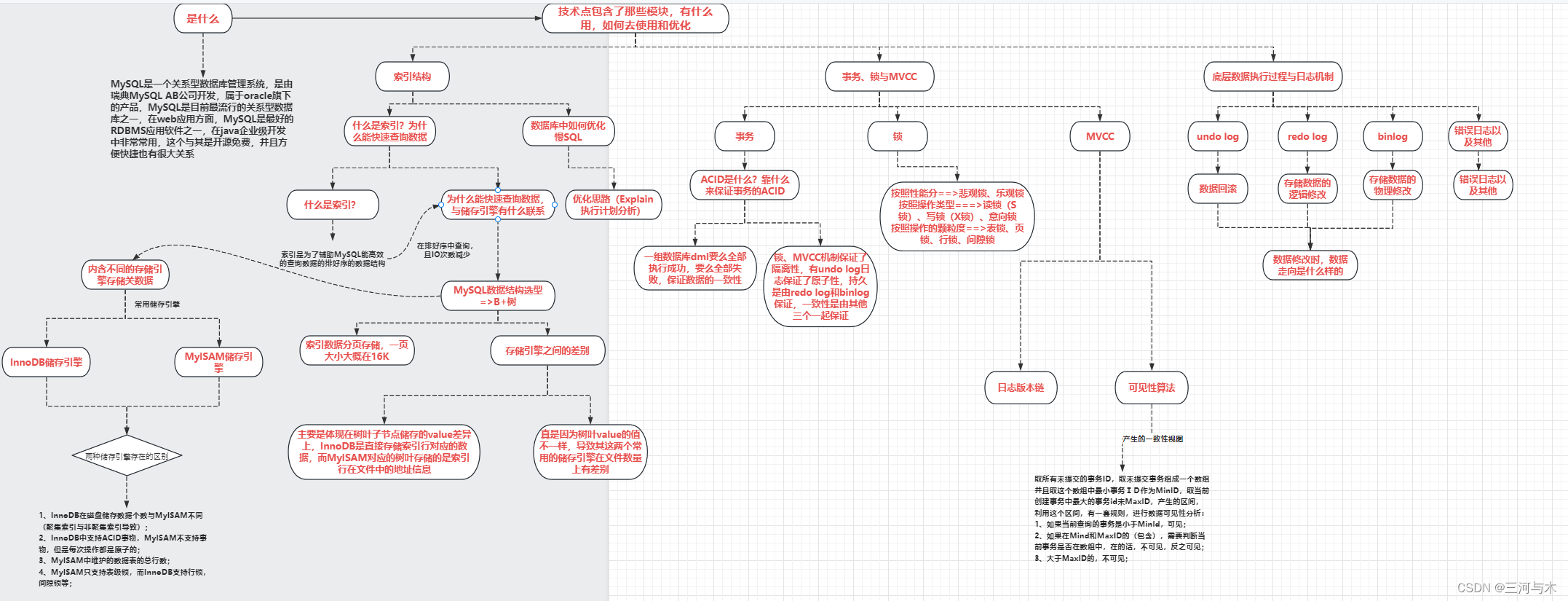
在上图中,关键模块主要是从:索引、锁、事务、MVCC、日志机制,来对MySQL展开学习与优化,例如索引(SQL)优化模块,并没有展开说明,因为在实际的业务中,都会遇到不同的问题,并且MySQL内部也有自己的优化器,但是,我们可以掌握其优化的思路,例如:我们可以先考虑SQL是否load了其他无用字段,整体SQL结构,其次再利用explain执行计划查看相关字段(type等字段信息),查看命中索引情况,最后如果是SQL优化到达瓶颈,我们可以考虑下数据量是否过于庞大,是否要进行分库分表以及集群搭建等操作;还有MVCC中的可见性算法和日志版本链,可见性生成的一致性视图是如何生成的,查询数据时,为什么不同的隔离级别会查到不同的数据、可见性算法的规则是什么等等,以此类推的结合实际问题深挖,终究会将问题一层层剖开并得于解决
二、MySQL数据库常见的面试题合集
2.1、MySQL的ACID是靠什么保证的?
参考答案:在MySQL中,事务的ACID分别表示:原子性、一致性、隔离性、持久性;但是保证各个特性的机制是不一样的,他们分别为: 1、原则性:保证原子性是靠MySQL内部的undo log日志来保证的,我们在对数据库数据修改前,底层在加载数据到buffer pool后会备份一份原始数据到undo log中;
2、一致性:数据最终一致性,最终的目的,这个是靠三个特性共同保证的
3、隔离性:由MySQL中锁(间隙所、临键锁等)与MVCC来保证的(MVCC中有日志版本链与可见性算法)
4、持久性:是由MySQL数据库底层的redo log(逻辑修改数据)与binlog(物理修改数据)日志来保证的
2.2、B+树和B树的区别,为什么MySQL要使用B+树?
参考答案:B+树中,所有的data数据都保存到也在节点上,而且叶子页与页之间通过双向指针互连的(目的是为了提高范围查询的效率),非叶子节点是属于冗余索引,是为了构建索引树而存在,B树中,每页中的每个元素的data是没有分开的,而且非叶子节点的数据不是冗余索引,叶子页之间是没有指针互指的,之所以选择B+树,是因为B+树中非叶子节点不存data数据,能存更多的索引数据,因为每页的大小是有限的,16K左右,而且B+树增加了叶子页指针互指,在跨页范围查询时,就不用再回到树根了,直接通过指针的互指,极大的提高了查询效率
2.3、Explain语句结果中各个字段分别表示什么?
参考答案:Explain主要是用来分析SQL的执行计划的,其中包含的列以及每列的说明如下:
1、id:表示执行的SQL唯一标识,有几个id就代表有几个执行的SQL,id的值越大==>优先级越高
2、selec_type:查询类型,例如,简单查询、复杂查询、衍生查询等等
3、table:表示差当前查询的表是哪个表,当from后有子查询时,其table列的值为:derivedN,其中N表示当前查询依赖于id为N的查询、若是查询语句中union,那union result中的table列的值为:unionN,M,其中的N和M表示合并select的id
4、type:这是优化时我们需要重点关注的,其值由性能依次分为:system>const>eq_ref>ref>rang>index>all
5、possible_key:可能会命中的索引,但不一定走,需要看MySQL的内部优化器对执行成本cost的估值,还选择一个成本cost较低的方案执行SQL
6、key:执行SQL使用到的索引情况
7、key_len:这个字段主要是针对联合索引,用到索引长度情况,通过长度值,我们可以看出SQL走了那些字段的索引信息
8、ref:这个字段是条件中的类型是常量还是变量
9、rows:MySQL估算的扫描行数,但不一定准确,可参考
10、Extra:其他信息,例如排序是否是文件排序等
2.4、InnoDB是如何实现事务的?
参考答案:InnoDB中实现事务是通过日志版本链和MVCC,以及MySQL的redo log和binlog日志机制共同实现
2.5、MySQL的索引结构是什么样的?
参考答案:MySQL索引选择的数据结构为:B+树,索引的data数据是存在树的叶子页节点上,其他非叶子节点上的索引都是冗余索引,目的是为了构建一颗B+树,叶子页与页之间有指针互指的,目的是为了在跨页范围查询时,不用回树根重新查找;
2.6、MySQL的锁有哪些,如何理解?
参考答案:MySQL中的锁,根据不同的维度可分为:
1、按照性能分:分为悲观锁和乐观锁,悲观锁主要适合写多读少的场景,悲观锁适合读多写少的场景
2、按照操作类型分为:读锁(S锁)=>读读不互斥,读写互斥、写锁(X锁)=>读写互斥,写写互斥、意向锁=>加锁的标记
3、按照操作的颗粒度分为:表锁、页锁、行锁、间隙锁、临键锁
2.7、MySQL集群如何搭建?
参考答案:MySQL的集群,我们一般是通过配置主库中的my.cnf文件=>主要是启用binlog日志,同样在从MySQL中设置relay log日志,通过从库开启的IO线程到主库中拉取binlog数据,从库中指定:MASTER_LOG_FILE='主库中的binlog文件',MASTER_LOG_POS=同步到的偏移量,那主库在写数据时,从库就会将数据拉取一份到自己库中,以及后续我们可以结合应用层面,让读和写操作不同的数据库以及配置这个主从同步的方式(半同步方式)来提高MySQL的并发量
2.8、MySQL聚簇和非聚簇索引的区别?
参考答案:聚簇索引索引值对应的行数据存储在data上,不用重新回表查询,而非聚簇索引,索引值对的行数据是存储在磁盘文件中,索引值对应的data是存储当前行数据在磁盘中的位置
2.9、MySQL的慢SQL如何优化?
参考答案:慢SQL分析时,我们要结合具体的业务来进行分析,思路是这样子的,我们首先先查看其SQL结构,是否load一些无用字段,如果有,可以适当去除,其次,我们可以在SQL前加入explain查看SQL执行计划,观察type列,以及select_type、rows、Extra、key、possible_key等,综合查看SQL执行时,命中索引情况
2.10、MySQL主从同步原理?
参考答案:主从同步的原则是这样子的,在主节点,我们需要在my.cnf文件中配置binlog处于开启状态,在从节点开启relay log,从库中指定:MASTER_LOG_FILE='主库中的binlog文件',MASTER_LOG_POS=同步到的偏移量,那主库在修改数据时,从库会开启一个IO线程读取binlog文件,将数据写到relay log中,再有SQL线程来执行,replay当前数据的改变操作
2.12、MySQL在什么情况下设置了索引但无法使用?
参考答案:MySQL有时虽然对过滤的条件设置了索引,但是真正执行时,没走索引,其原因主要有以下情况:
1、没有满足最左前缀原则
2、SQL结构为范围查询时,范围过大,MySQL有自己的优化器,估算扫描数据成本值,会选择较为合适的方案执行SQL
3、条件中使用了is null、is not null、!=null或者对索引字段进行函数操作时,也会导致索引失效
2.13、存储拆分后如何解决唯一主键问题?
参考答案:分库分表之后,主键生成的方案主要有以下几种:
1、我们可以在配置文件中配置生成算法为雪花算法,但是这种算法有一个缺陷,就是在分布式环境下,如果不指定workID,会有主键冲突问题,解决方案就是指定workID,指定方式有多种,例如用当前服务IP取余方式、或者是直接配置在配置文件中等
2、其次就是在配置文件中配置生成算法为UUID
3、还有就是维护一张专门生产主键的表,每次需要生成时,就往这张表插入记录,并将id返回,就可以使用返回的id作为主键
2.14、在海量数据中,如何快速查找一条记录?
参考答案:我们可以对数据添加索引,除此之外,我们还可以在数据存储时,将数据类似大数据分布式存储系统一样,将数据分表或者分区进行储存,在查数据时的效率在一定程度上也会得到提高
2.15、简述InnoDB与MyISAM的区别?
参考答案:其两个储存引擎的主要区别如下:
1、磁盘文件数量不同,InnoDB有两个(一个数据表结构,一个是数据+索引数据文件),MyISAM有三个(数据、表结构、索引)
2、MyISAM内部维护了总行数,而InnoDB中没有
3、MyISAM中不支持事务,InnoDB中支持ACID特性事务
4、MyISAM中只有表级锁,而InnoDB中支持行级锁、间隙锁、临键锁等
2.16、MySQL中索引类型及对数据库性能的影响?
参考答案:
普通索引:允许被索引的数据列包含重复的值
唯一索引:可以保证数据记录的唯一性
主键索引:是一种特殊的唯一索引,在一张表里只能定义一个主键索引,主键用于唯一标识一条记录,使用关键字PRIMARY KEY来创建。
联合索引:索引可以覆盖多个数据列,如像INDEX(column A, column B)索引。
全文索引:通过建立倒排索引,可以极大的提升检索效率,解决判断字段是否包含的问题,是目前搜索引擎使用的一种关键技术。
2.17、如何实现分库分表?
参考答案:可以在数据访问层上面做分表的逻辑,用代码逻辑控制访问数据库信息,除此之外,也可以借助第三方框架,例如:shardingJDBC
2.18、什么是MVCC?
参考答案:MVCC是MySQL数据库的多版本控制,其底层是由redo log日志版本链以及可见性算法指定的规则来支持的,可解决MySQL中事务的不同隔离级别的具体实现,提高了读写同时的并发量
2.19、什么是脏读、幻读、不可重复读?
参考答案:1、脏读:就是当前事务读取到其他事务修改但未提交事务的数据,这个数据有可能会提交,也有可能会回滚,如果当前事务读取到的数据参与业务逻辑运算,这种运算的结果是不确定的;
2、幻读:当前事务在不同时间段,同一条SQL读取到了其他事务新增的数据(数量上的不一致)
3、不可重复读:当前事务执行的SQL在不同时间段读取到数据结果是不一致的,主要是读取到其他事务修改或删除之后最新的数据
2.20、事务的基本特性与隔离级别?
参考答案:事务的基本特性为ACID,分别为:
1、原子性:当前的操作,要么是全部都执行成功,要么全部执行失败
2、一致性:数据最终一致性,事务的最终目的,是由其他特性共同保证的
2.21、索引的基本原理?
参考答案:索引主要是在于是有序的数据结构,而且存储索引的数据结构选择的是B+树,那在查找索引时,如果是二分查找,相比其他没有索引的数据,查找效率较高,找到数据后与磁盘进行IO的次数也少;
2.22、索引设计的基本原则?
参考答案:设计索引时,我们应该遵循:
1、代码先行,索引后上:也就是说可以将主业务代码确定下来之后,我们可以将代码中涉及的SQL单独拿出来分析,再建立合适的索引
2、索引字段不应选择基数较小列:也就是说选择索引时,不能选择哪种不同的值很少的列,例如:性别
3、改动频繁的列:改动频繁的列以及重复值较多的列不适合用作索引
4、如果选择的索引列太长,我们可以选择字段前缀作为索引值
5、建立的索引都需要大部分覆盖条件
2.23、覆盖索引是什么?
参考答案:索引覆盖主要是针对联合索引的,就是说,查询的列,在联合索引树中就可以拿到,不用回表重新load字段值信息,我们称为覆盖索引,在优化时,我们可以在适当的业务场景中引入覆盖索引,也会极大的提高查询的效率
2.24、最左前缀原则是什么?
参考答案:最左前缀也是针对联合索引来说的,也就是在建立联合索引时,联合索引中第一个字段到最后一个字段,在查询条件中,必须保持有序或者都需要体现出(MySQL内部优化器会优化顺序),这样子联合索引才会生效,反之,跳过某个联合索引字段的,会导致索引失效





 本文详细解析了MySQL数据库的核心概念,包括ACID特性、索引结构、锁机制、事务处理、索引优化、主从同步、聚簇与非聚簇索引、慢SQL优化、分库分表等,并列举了常见面试题和注意事项。
本文详细解析了MySQL数据库的核心概念,包括ACID特性、索引结构、锁机制、事务处理、索引优化、主从同步、聚簇与非聚簇索引、慢SQL优化、分库分表等,并列举了常见面试题和注意事项。

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









