




 本文详述了如何在阿里云环境中安装Scala和Spark,配置环境,搭建Spark集群,以及执行Wordcount实验的过程。从下载安装包到启动集群,再到解决版本冲突问题,每个步骤都有清晰说明。
本文详述了如何在阿里云环境中安装Scala和Spark,配置环境,搭建Spark集群,以及执行Wordcount实验的过程。从下载安装包到启动集群,再到解决版本冲突问题,每个步骤都有清晰说明。
一、安装Scala
1.到官网下载Scala安装压缩包,本次试验下载的为2.12.8版本。
2.h1用户下新建Scala文件夹,并将下载好的压缩包解压缩到Scala文件夹中。
3.配置 /etc/profile文件
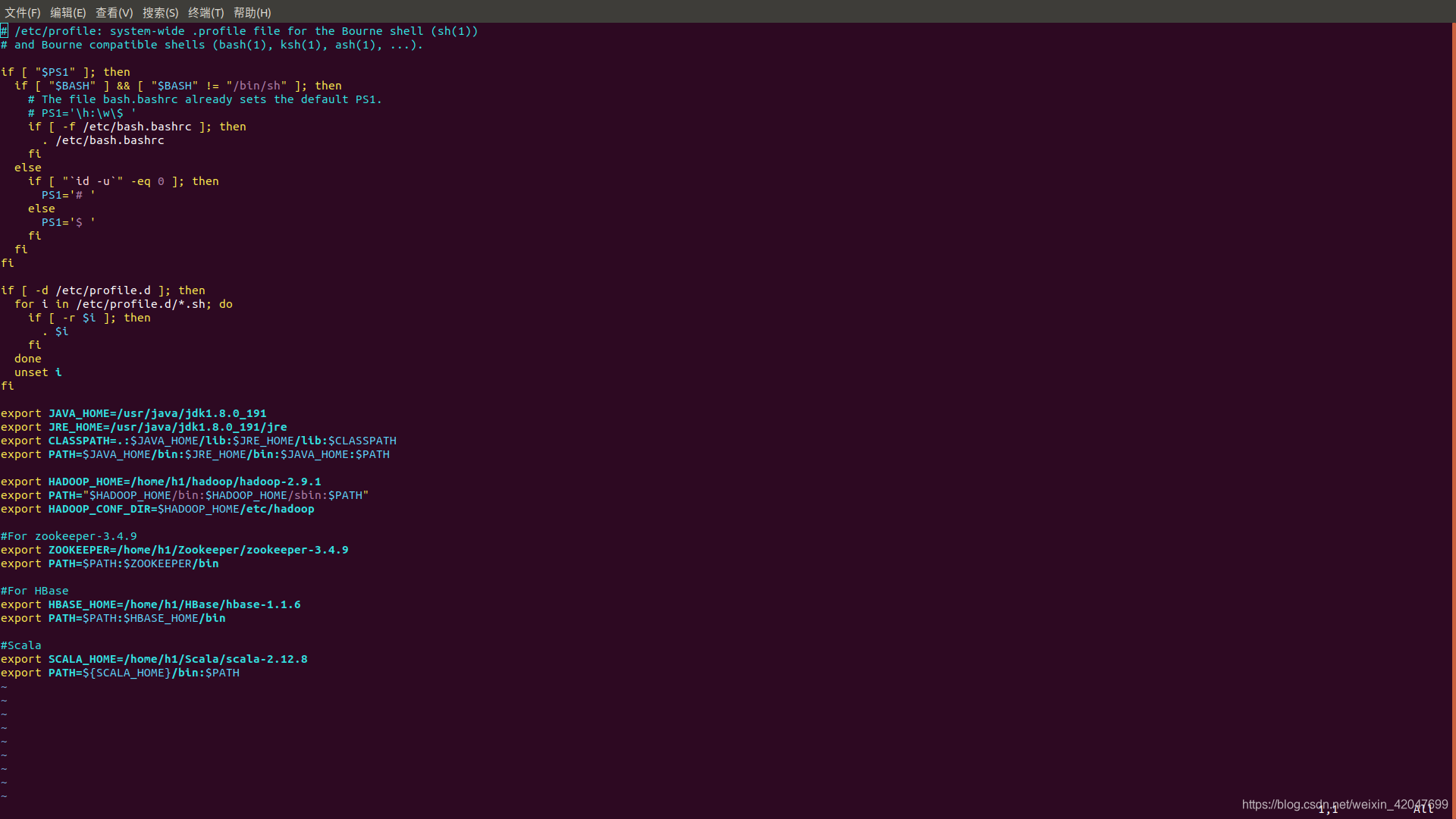
4.source /etc/profile使环境变量配置生效。
二、安装Spark
1.到官网下载Spark安装压缩包,本次试验下载的为2.4.0版本。
2.在h1用户下新建Spark文件夹,并将下载好的压缩包解压到Spark文件夹中。
3.进入 /con文件夹中对Spark进行配置:
4.配置spark-env.sh文件:
export SCALA_HOME=/home/h1/Scala/scala-2.12.8
export JAVA_HOME=/usr/java/jdk1.8.0_191
export SPARK_WORKER_MEMORY=1g
export SPARK_MASTER_IP=master
export MASTER=spark://master:7077
5.修改conf/slaves文件
在slaves文件中添加slave1
6.使用scp命令将master上的scala及spark文件拷到slave1机器上,并修改环境变量使其生效。
三、启动集群
1.start-all.sh启动hadoop集群。
2.然后切到spark安装目录下的sbin文件夹中使用./start-all.sh启动spark。
3.使用jps可以查看到相应进程
四、WordCount实验
1.安装sbt
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
sudo a 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









