






pdf:概率密度函数
语音识别中隐变量是音素,观测变量是MFCC特征
GMM
GMM:聚类,提前知道k的类别个数,总和为1,可指定GMM分布中高斯函数个数(5),rnk:样本指示点样本对应的标签值
| EM | |
|---|---|
| E | 根据指示值,计算根据定义的样本均值(数值)协方差矩阵(39维),求出周围样本属于该标准样本的概率 |
| M | 根据当前样本帧分布情况,求出样本区域中的均值和协方差矩阵和Πk |
EM:参数空间理解EM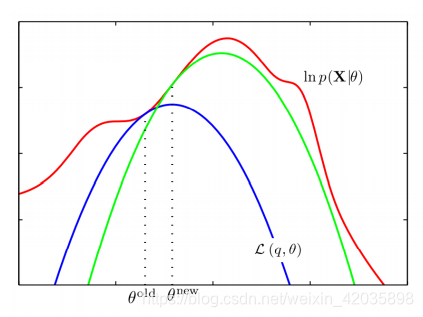
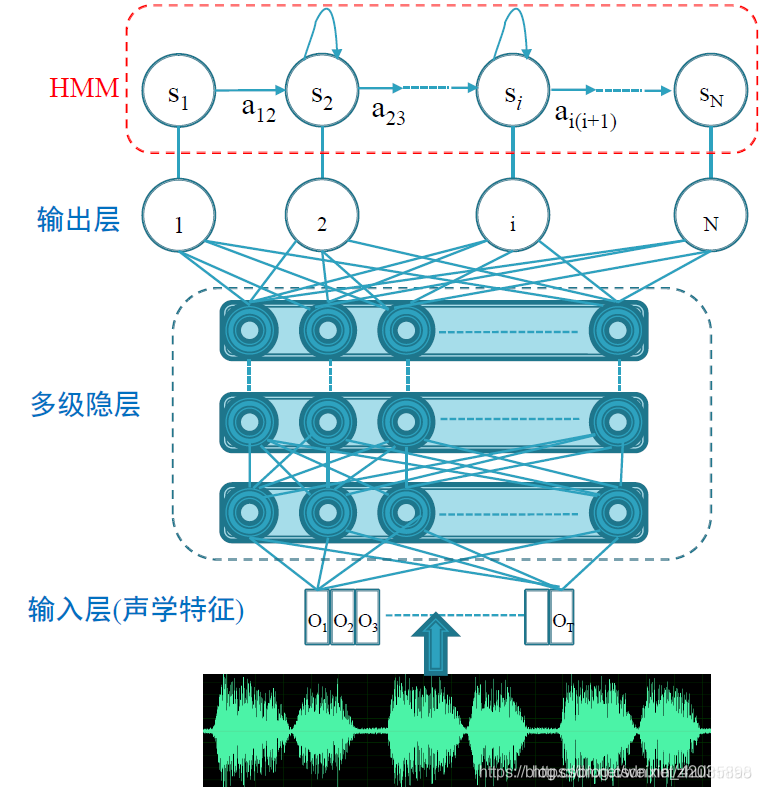
GMM + HMM
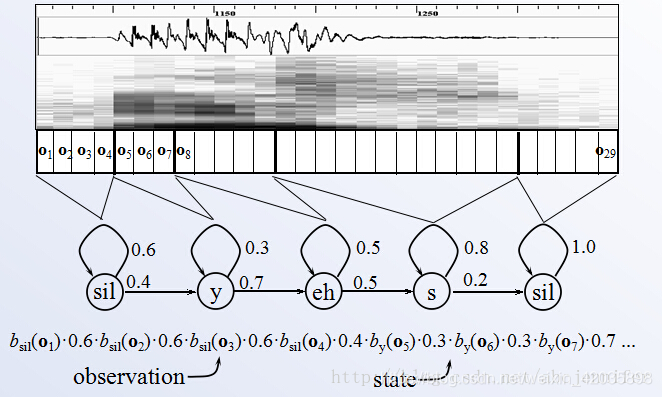
一段帧对应一个因素的过程
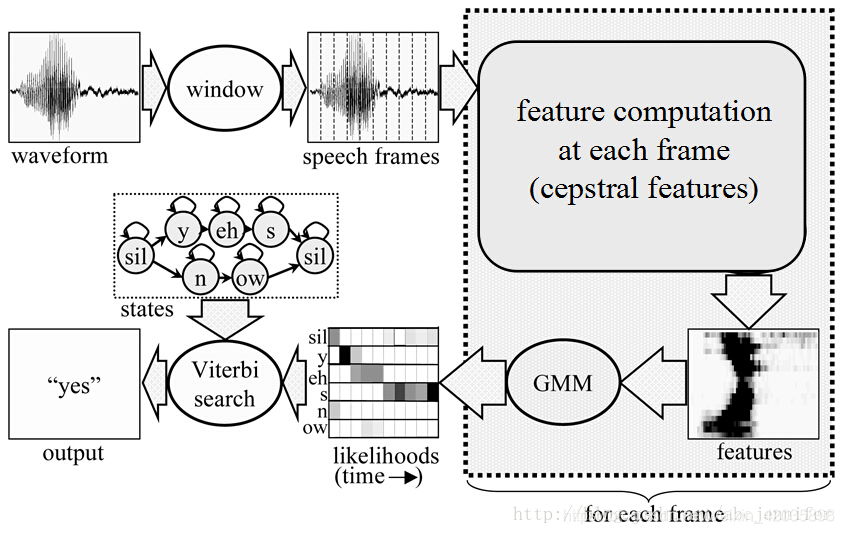
语音到词的流程
HMM 三参数 (Π, A, B) 训练就是训练因素转移概率A和B的过程
Π:因素中状态的可能取值(几十)n
A:音素间的转移概率,n*n 初始化1/2,1/2
B:音素对应对特征值的高斯分布(μ均值 和 E协方差)
【pdf-id】 :GMM 的 ID, hmm-state到帧特征(观察值)的发射概率通过一个GMM生成模型 pdf-id生成得到
【pdf-id是绑定到hmm-state上的发射概率函数】
【transition-id是各hmm-state之间跳转的转移概率的唯一id】=>【HMM中的转移矩阵】
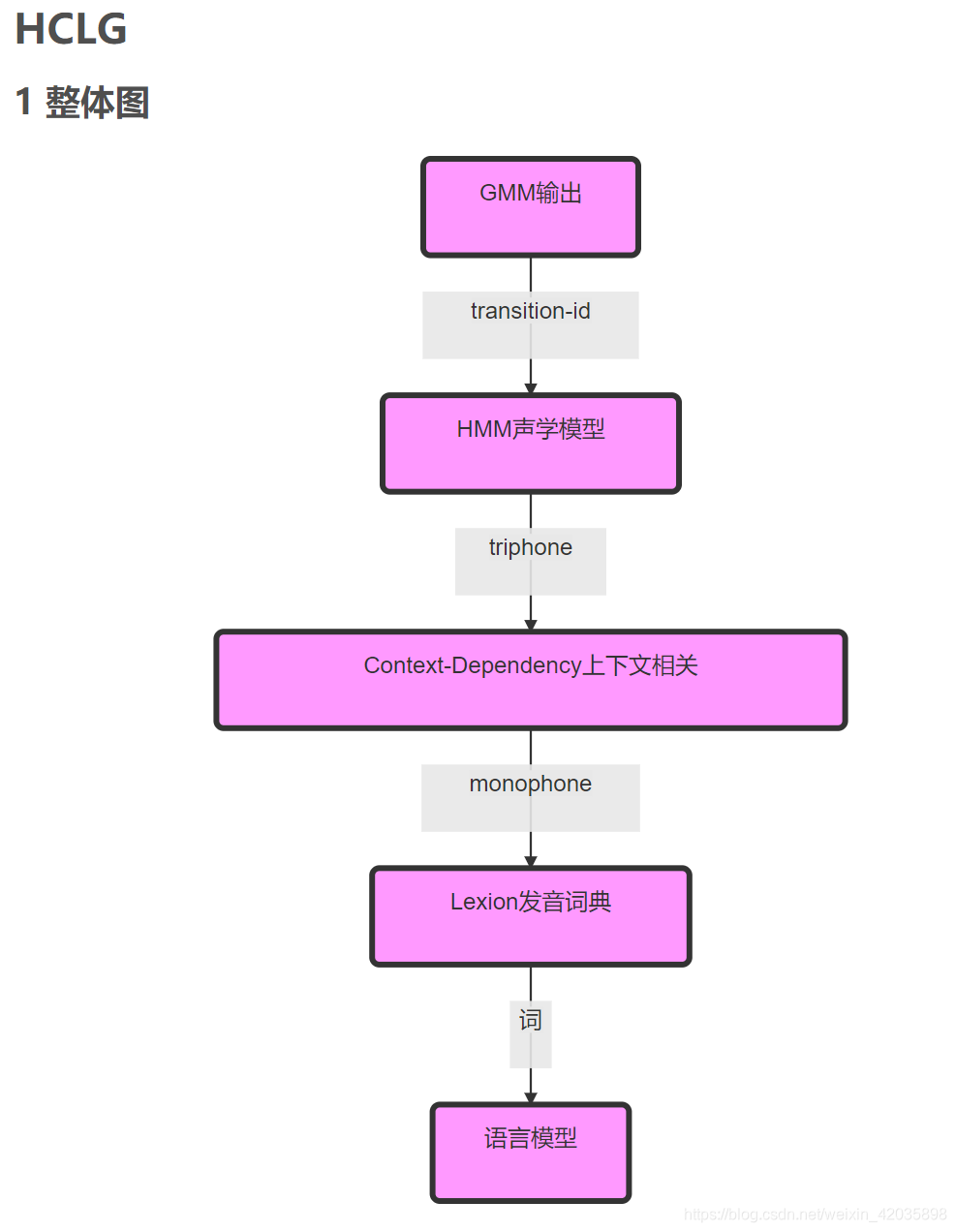
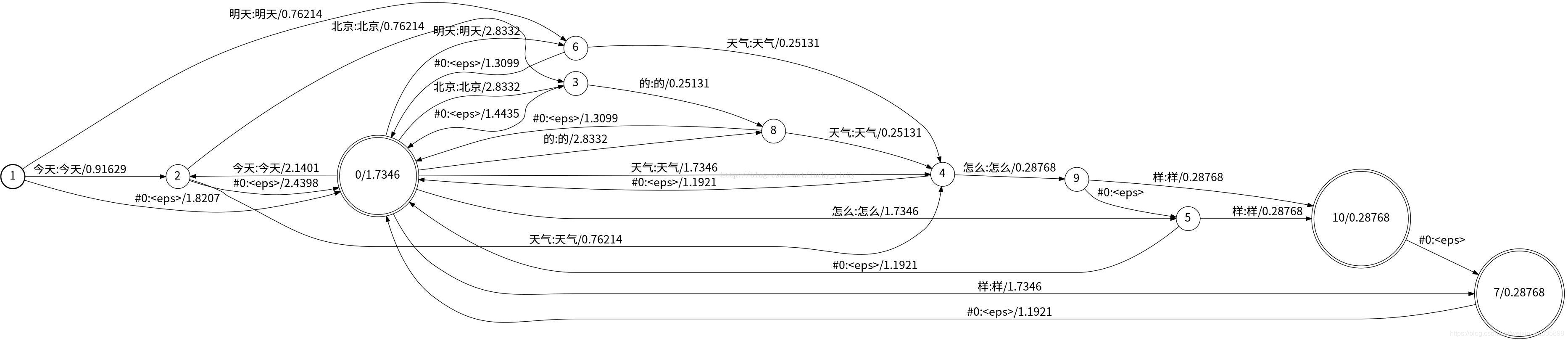
HCLG.fst
| HCLG过程 | |
|---|---|
| G | 语言模型WFST,输入输出符号相同,实际是一个WFSA(acceptor接受机),为了方便与其它三个WFST进行操作,将其视为一个输入输出相同的WFST。 |
| L | 发音词典WFST,输入符号:monophone,输出符号:词; |
| C | 上下文相关WFST,输入符号:triphone(上下文相关),输出符号:monophnoe; |
| H | HMM声学模型WFST,输入符号:HMM transitions-ids,输出符号:triphone。 |
G.fst
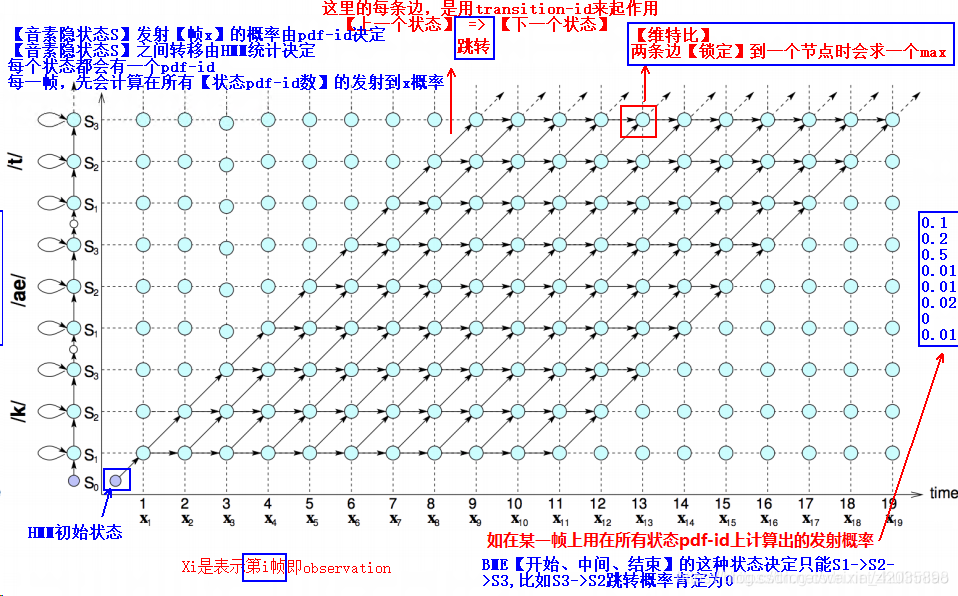
【1】一开始,用【所有音素状态对应的GMM(pdf-id)】对所有的音频每一帧,计算出【每一音频帧】在【所有音素状态】上的【发射概率(是一个向量,维度是音素状态数量)】
【2】考虑到时所有音频帧,所以整段音频帧的发射概率矩阵=(音频帧数, 音素状态数)
【3】图中的网格中的点(如下是2个点),可以理解为是(GMM(pdf-id)水平方向音素状态, 音频帧)的发射概率
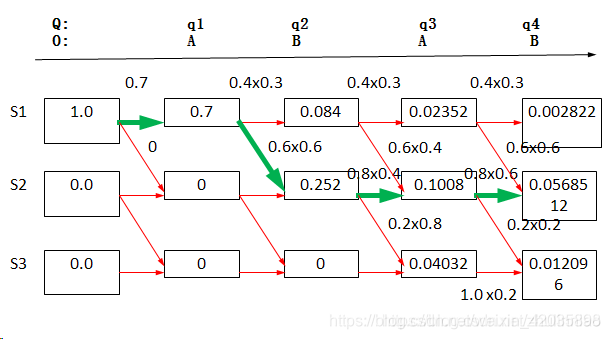
viterbe的解码过程
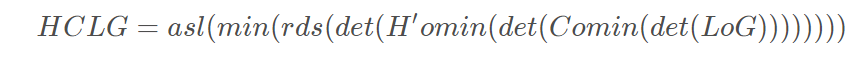
上面的o表示组合,det表示确定化,min表示最小化,rds表示去除消岐符号,asl表示增加自环。
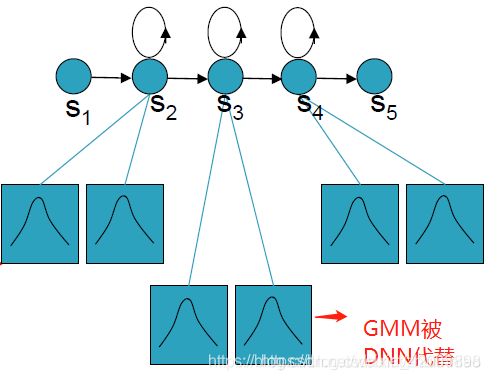
用DNN代替GMM过程

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









