



 本文深入浅出地介绍了Java的基础知识,涵盖了数据类型、类与对象、异常处理、集合框架、多线程、I/O操作等内容,并对核心概念进行了详细解释。
本文深入浅出地介绍了Java的基础知识,涵盖了数据类型、类与对象、异常处理、集合框架、多线程、I/O操作等内容,并对核心概念进行了详细解释。
JAVA基础
┌───────────────────────────┐
│Java EE │
│ ┌────────────────────┐ │
│ │Java SE │ │
│ │ ┌─────────────┐ │ │
│ │ │ Java ME │ │ │
│ │ └─────────────┘ │ │
│ └────────────────────┘ │
└───────────────────────────┘
┌─ ┌──────────────────────────────────┐
│ │ Compiler, debugger, etc. │
│ └──────────────────────────────────┘
JDK ┌─ ┌──────────────────────────────────┐
│ │ │ │
│ JRE │ JVM + Runtime Library │
│ │ │ │
└─ └─ └──────────────────────────────────┘
┌───────┐┌───────┐┌───────┐┌───────┐
│Windows││ Linux ││ macOS ││others │
└───────┘└───────┘└───────┘└───────┘
基本数据类型
| 数据类型 | 长度(单位:字节) | 范围 |
|---|---|---|
| byte | 1 | -128~127 |
| short | 2 | -32768~32767 |
| int | 4 | -2147483648~2147483647 |
| long | 8 | -9223372036854775808 ~ 9223372036854775807 |
| float | 4 | 3.4x10^38 |
| double | 8 | 1.79x10^308 |
| char | 2 | ∞ |
| boolean | 理论上:1;通常4 | true或false |
引用类型
除了基本数据类型都是引用类型,典型比如String,引用类型可以指向一个空值NULL
常量
在定义变量时候加上final就会变成常量,常量名全部大写
var关键字
省略变量类型用,例如:
int Number = 4;
//等价于
var Number = 4;
变量作用域
定义变量时,要遵循作用域最小化原则,尽量将变量定义在尽可能小的作用域,并且,不要重复使用变量名。
运算
在运算过程中,如果参与运算的两个数类型不一致,那么计算结果为较大类型的整型。例如,short和int计算,结果总是int,原因是short首先自动被转型为int
也可以将结果强制转型,即将大范围的整数转型为小范围的整数。强制转型使用(类型),例如,将int强制转型为short,强制转型的结果很可能是错的
IO
输出
一般输出:
- print()
- println()
格式化输出:printf(“n=%d, hex=%08x”, n, n)
| 占位符 | 说明 |
|---|---|
| %d | 格式化输出整数 |
| %x | 格式化输出十六进制整数 |
| %f | 格式化输出浮点数 |
| %e | 格式化输出科学计数法表示的浮点数 |
| %s | 格式化字符串 |
输入
一般输入:
- import:import java.util.Scanner
- Scanner.nextLine()
- scanner.nextInt()
BIO、NIO、AIO原理及应用场景
BIO,同步阻塞IO,适用于连接数目小且固定,一个连接一个线程
NIO,同步非阻塞IO,适用于连接数目多且连接比较短,一个请求一个线程
AIO,异步非阻塞IO,适用于连接数目多且连接比较长,一个有效请求一个线程
数组排序
使用JDK自带的Arrays.sort()
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
Arrays.sort(ns);//默认是升序
Arrays.sort(scores,Collections.reverseOrder());//降序
多维数组
打印二维数组可以使用JDK的Arrays.deepToString()
System.out.println(Arrays.deepToString(ns));
命令行参数
//以下实现-version参数,打印程序版本号
public class Main {
public static void main(String[] args) {
for (String arg : args) {
if ("-version".equals(arg)) {
System.out.println("v 1.0");
break;
}
}
}
}
java序列化
序列化是把JAVA对象转换为字节序列,反序列化是把字节序列恢复为原先的JAVA对象
方法是在定义类时实现一个serializable接口,实际上是一个标记的作用,用于高速代码只要是实现了serializable就可以被序列化
serialversionUID是序列化前后的唯一标识符,默认如果没有人为定义则会被编译器自动声明
static或transient修饰的是不会序列化的
面向对象
面向对象基础
方法参数
可变参数,使用类型…定义,相当于数组类型,可以避免输入时自己构造数组的麻烦过程。
class Group {
private String[] names;
public void setNames(String... names) {
this.names = names;
}
}
参数绑定
基本类型参数的传递,是调用方值的复制。双方各自的后续修改,互不影响。
引用类型参数的传递,调用方的变量,和接收方的参数变量,指向的是同一个对象。双方任意一方对这个对象的修改,都会影响对方。
方法重载
方法名相同,但各自的参数不同,称为方法重载(Overload)。方法重载的目的是,功能类似的方法使用同一名字,更容易记住,因此,调用起来更简单。
class Hello {
public void hello() {
System.out.println("Hello, world!");
}
public void hello(String name) {
System.out.println("Hello, " + name + "!");
}
public void hello(String name, int age) {
if (age < 18) {
System.out.println("Hi, " + name + "!");
} else {
System.out.println("Hello, " + name + "!");
}
}
}
继承
Java使用extends关键字来实现继承,子类自动获得了父类的所有字段,严禁定义与父类重名的字段!
子类无法访问父类的private字段或者private方法,为了让子类可以访问父类的字段,需要把private改为protected。用protected修饰的字段可以被子类访问
super表示父类,任何class的构造方法,第一行语句必须是调用父类的构造方法
class Student extends Person {
protected int score;
public Student(String name, int age, int score) {
super(name, age); // 调用父类的构造方法Person(String, int)
this.score = score;
}
}
接口类
所谓interface,就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。因为接口定义的所有方法默认都是public abstract的,所以这两个修饰符不需要写出来
因为interface是一个纯抽象类,所以它不能定义实例字段。但是,interface是可以有静态字段的,并且静态字段必须为final类型
interface Person {
public static final int MALE = 1;
public static final int FEMALE = 2;
void run();
String getName();
}
//当一个具体的`class`去实现一个`interface`时,需要使用`implements`关键字
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(this.name + " run");
}
@Override
public String getName() {
return this.name;
}
}
包
类似于.NET里的namespace,用来放类以解决名字冲突
package ming; // 申明包名ming
public class Person {
// 包作用域:
void hello() {
System.out.println("Hello!");
}
}
public class Main {
public static void main(String[] args) {
Person p = new Person();
p.hello(); // 可以调用,因为Main和Person在同一个包
}
}
使用方法:
// 导入完整类名:
import mr.jun.Arrays;
/**或者*/
// 导入System类的所有静态字段和静态方法:
import static java.lang.System.*;
final关键字
作用:
- 用
final修饰class可以阻止被继承 - 用
final修饰method可以阻止被子类覆写 - 用
final修饰field可以阻止被重新赋值 - 用
final修饰局部变量可以阻止被重新赋值
JAVA核心类
String
字符串比较时必须使用equals()方法而不能用==。
字符串提供了formatted()方法和format()静态方法,可以传入其他参数,替换占位符,然后生成新的字符串:如果不确定用啥占位符,那就始终用%s,因为%s可以显示任何数据类型。
StringBuilder
为了能高效拼接字符串,Java标准库提供了StringBuilder,它是一个可变对象,可以预分配缓冲区,这样,往StringBuilder中新增字符时,不会创建新的临时对象
StringBuilder sb = new StringBuilder(1024);
for (int i = 0; i < 1000; i++) {
sb.append(',');
sb.append(i);
}
String s = sb.toString();
实际上append方法类似于“+”运算符所进行的操作。
StringBuffer,这是Java早期的一个StringBuilder的线程安全版本,它通过同步来保证多个线程操作StringBuffer也是安全的,但是同步会带来执行速度的下降。
StringBuilder和StringBuffer接口完全相同,现在完全没有必要使用StringBuffer。
StringJoiner与String.join()
用分隔符拼接数组的需求很常见,所以Java标准库还提供了一个StringJoiner来干这个事。String还提供了一个静态方法join(),这个方法在内部使用了StringJoiner来拼接字符串,在不需要指定“开头”和“结尾”的时候,用String.join()更方便。
public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
var sj = new StringJoiner(", ", "Hello ", "!");//Hello为开头,!为结尾
var sj = new StringJoiner(", ", "Hello ", "!");//无开头结尾写法
var sj = String.join(", ", names);//等效于无开头结尾写法
for (String name : names) {
sj.add(name);
}
System.out.println(sj.toString());//Hello Bob, Alice, Grace!
}
}
包装类型
引用类型可以赋值为null,表示空,但基本类型不能赋值为null,想要把int基本类型变成一个引用类型,可以定义一个Integer类,它只包含一个实例字段int,这样,Integer类就可以视为int的包装类(Wrapper Class)。
Java核心库为每种基本类型都提供了对应的包装类型:
| 基本类型 | 对应的引用类型 |
|---|---|
| boolean | java.lang.Boolean |
| byte | java.lang.Byte |
| short | java.lang.Short |
| int | java.lang.Integer |
| long | java.lang.Long |
| float | java.lang.Float |
| double | java.lang.Double |
| char | java.lang.Character |
JavaBean
符合以下规范的,称为JavaBean
// 读方法:
public Type getXyz()
// 写方法:
public void setXyz(Type value)
将对应的读方法和写方法称为属性。
//其实感觉Java这里太麻烦,C#中的{get; set;}表达更简洁
要枚举一个JavaBean的所有属性,可以直接使用Java核心库提供的Introspector
BeanInfo info = Introspector.getBeanInfo(Person.class);
for (PropertyDescriptor pd : info.getPropertyDescriptors()) {
System.out.println(pd.getName());
System.out.println(" " + pd.getReadMethod());
System.out.println(" " + pd.getWriteMethod());
}
枚举类
为了让编译器能自动检查某个值在枚举的集合内,并且,不同用途的枚举需要不同的类型来标记,不能混用,可以使用enum来定义枚举类
enum Weekday {
SUN, MON, TUE, WED, THU, FRI, SAT;
}
记录类(java14以后)
使用record关键字,可以一行写出一个不变类
假设Point类的x、y不允许负数,就得给Point的构造方法加上检查逻辑:
public record Point(int x, int y) {
public Point {
if (x < 0 || y < 0) {
throw new IllegalArgumentException();
}
}
}
BigInteger
BigInteger用于表示任意大小的整数;
BigInteger是不变类,并且继承自Number;
将BigInteger转换成基本类型时可使用longValueExact()等方法保证结果准确。
BigDecimal
BigDecimal用于表示精确的小数,常用于财务计算;
比较BigDecimal的值是否相等,必须使用compareTo()而不能使用equals()。
常用工具类
Java提供的常用工具类有:
- Math:数学计算
- Random:生成伪随机数
- SecureRandom:生成安全的随机数
异常处理
异常的继承关系及使用规则
┌───────────┐
│ Object │
└───────────┘
▲
│
┌───────────┐
│ Throwable │
└───────────┘
▲
┌─────────┴─────────┐
│ │
┌───────────┐ ┌───────────┐
│ Error │ │ Exception │
└───────────┘ └───────────┘
▲ ▲
┌───────┘ ┌────┴──────────┐
│ │ │
┌─────────────────┐ ┌─────────────────┐┌───────────┐
│OutOfMemoryError │... │RuntimeException ││IOException│...
└─────────────────┘ └─────────────────┘└───────────┘
▲
┌───────────┴─────────────┐
│ │
┌─────────────────────┐ ┌─────────────────────────┐
│NullPointerException │ │IllegalArgumentException │...
└─────────────────────┘ └─────────────────────────┘
Java标准库定义的常用异常包括:
Exception
│
├─ RuntimeException
│ │
│ ├─ NullPointerException
│ │
│ ├─ IndexOutOfBoundsException
│ │
│ ├─ SecurityException
│ │
│ └─ IllegalArgumentException
│ │
│ └─ NumberFormatException
│
├─ IOException
│ │
│ ├─ UnsupportedCharsetException
│ │
│ ├─ FileNotFoundException
│ │
│ └─ SocketException
│
├─ ParseException
│
├─ GeneralSecurityException
│
├─ SQLException
│
└─ TimeoutException
Java规定:
- 必须捕获的异常,包括除了
RuntimeException及其子类的Exception及其子类。 - 不需要捕获的异常,包括
Error及其子类,RuntimeException及其子类(Checked Exception)。
捕获异常
使用try … catch
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println(e);
} catch (NumberFormatException e) {
System.out.println(e);
}
}
抛出异常
如何抛出异常?参考Integer.parseInt()方法,抛出异常分两步:
- 创建某个
Exception的实例; - 用
throw语句抛出。
通过printStackTrace()可以打印出方法的调用栈,类似:
java.lang.NumberFormatException: null
at java.base/java.lang.Integer.parseInt(Integer.java:614)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.process2(Main.java:16)
at Main.process1(Main.java:12)
at Main.main(Main.java:5)
throw和throws的区别
throw放在方法体中,用来抛出一个具体的异常类型
throws跟在方法声明后面,能抛出多个异常对象,异常由方法的调用者处理
使用JDK Logging
JDK自带,但实际上不太好用,一般使用Log4J等第三方log模块
// logging
import java.util.logging.Level;
import java.util.logging.Logger;
public class Hello {
public static void main(String[] args) {
Logger logger = Logger.getGlobal();
logger.info("start process...");
logger.warning("memory is running out...");
logger.fine("ignored.");
logger.severe("process will be terminated...");
}
}
使用Log4j
Log4j是一个组件化设计的日志系统,它的架构大致如下:
log.info("User signed in.");
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ Console │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ File │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
└──>│ Appender │───>│ Filter │───>│ Layout │───>│ Socket │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
当使用Log4j输出一条日志时,Log4j自动通过不同的Appender把同一条日志输出到不同的目的地。例如:
- console:输出到屏幕;
- file:输出到文件;
- socket:通过网络输出到远程计算机;
- jdbc:输出到数据库
通过Filter来过滤哪些log需要被输出,通过Layout来格式化日志信息
使用log4j2.xml文件放在classpath下配置log4j
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Properties>
<!-- 定义日志格式 -->
<Property name="log.pattern">%d{MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}%n%msg%n%n</Property>
<!-- 定义文件名变量 -->
<Property name="file.err.filename">log/err.log</Property>
<Property name="file.err.pattern">log/err.%i.log.gz</Property>
</Properties>
<!-- 定义Appender,即目的地 -->
<Appenders>
<!-- 定义输出到屏幕 -->
<Console name="console" target="SYSTEM_OUT">
<!-- 日志格式引用上面定义的log.pattern -->
<PatternLayout pattern="${log.pattern}" />
</Console>
<!-- 定义输出到文件,文件名引用上面定义的file.err.filename -->
<RollingFile name="err" bufferedIO="true" fileName="${file.err.filename}" filePattern="${file.err.pattern}">
<PatternLayout pattern="${log.pattern}" />
<Policies>
<!-- 根据文件大小自动切割日志 -->
<SizeBasedTriggeringPolicy size="1 MB" />
</Policies>
<!-- 保留最近10份 -->
<DefaultRolloverStrategy max="10" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<!-- 对info级别的日志,输出到console -->
<AppenderRef ref="console" level="info" />
<!-- 对error级别的日志,输出到err,即上面定义的RollingFile -->
<AppenderRef ref="err" level="error" />
</Root>
</Loggers>
</Configuration>
同时需要把以下三个包放在classpath中
- log4j-api-2.x.jar
- log4j-core-2.x.jar
- log4j-jcl-2.x.jar
Log log = LogFactory.getLog(Main.class);
log.info("start...");
log.warn("end.");
注解
注解是一种用作标注的“元数据”
Java使用@interface定义注解:
可定义多个参数和默认值,核心参数使用value名称;
必须设置@Target来指定Annotation可以应用的范围;
应当设置@Retention(RetentionPolicy.RUNTIME)便于运行期读取该Annotation。
可以在运行期通过反射读取RUNTIME类型的注解,注意千万不要漏写@Retention(RetentionPolicy.RUNTIME),否则运行期无法读取到该注解
反射
Class类
由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,就可以通过这个Class实例获取到该实例对应的class的所有信息。
这种通过Class实例获取class信息的方法称为反射(Reflection)。
一个Class实例包含了该class的所有完整信息:
┌───────────────────────────┐
│ Class Instance │──────> String
├───────────────────────────┤
│name = "java.lang.String" │
├───────────────────────────┤
│package = "java.lang" │
├───────────────────────────┤
│super = "java.lang.Object" │
├───────────────────────────┤
│interface = CharSequence...│
├───────────────────────────┤
│field = value[],hash,... │
├───────────────────────────┤
│method = indexOf()... │
└───────────────────────────┘
获取方法:
-
通过静态变量class获取
Class cls = String.class; -
通过实例变量提供的getClass())方法获取
String s = "Hello"; Class cls = s.getClass(); -
通过静态方法Class.forName()获取
Class cls = Class.forName("java.lang.String");可以用
instanceof判断数据类型
访问字段
通过Class实例的方法可以获取Field实例:getField(),getFields(),getDeclaredField(),getDeclaredFields();
通过Field实例可以获取字段信息:getName(),getType(),getModifiers();
通过Field实例可以读取或设置某个对象的字段,如果存在访问限制,要首先调用setAccessible(true)来访问非public字段。
通过反射读写字段是一种非常规方法,它会破坏对象
- Field getField(name):根据字段名获取某个public的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getFields():获取所有public的field(包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
Class stdClass = Student.class;
// 获取public字段"score":
System.out.println(stdClass.getField("score"));
// 获取继承的public字段"name":
System.out.println(stdClass.getField("name"));
// 获取private字段"grade":
System.out.println(stdClass.getDeclaredField("grade"));
调用方法
通过Class实例的方法可以获取Method实例:getMethod(),getMethods(),getDeclaredMethod(),getDeclaredMethods();
通过Method实例可以获取方法信息:getName(),getReturnType(),getParameterTypes(),getModifiers();
通过Method实例可以调用某个对象的方法:Object invoke(Object instance, Object... parameters);
通过设置setAccessible(true)来访问非public方法;
Class类提供了以下几个方法来获取Method:
Method getMethod(name, Class...):获取某个public的Method(包括父类)Method getDeclaredMethod(name, Class...):获取当前类的某个Method(不包括父类)Method[] getMethods():获取所有public的Method(包括父类)Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
Class stdClass = Student.class;
// 获取public方法getScore,参数为String:
System.out.println(stdClass.getMethod("getScore", String.class));
// 获取继承的public方法getName,无参数:
System.out.println(stdClass.getMethod("getName"));
// 获取private方法getGrade,参数为int:
System.out.println(stdClass.getDeclaredMethod("getGrade", int.class));
获取继承关系
通过Class对象可以获取继承关系:
Class getSuperclass():获取父类类型;Class[] getInterfaces():获取当前类实现的所有接口。
通过Class对象的isAssignableFrom()方法可以判断一个向上转型是否可以实现。
泛型
泛型就是定义一种模板,例如ArrayList<T>,然后在代码中为用到的类创建对应的ArrayList<类型>:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
//String类型的ArrayList
ArrayList<String> strList = new ArrayList<String>();
//Integer类型的ArrayList
ArrayList<Integer> strList = new ArrayList<Integer>();
//Float类型的ArrayList
ArrayList<Float> strList = new ArrayList<Float>();
擦拭法(Type Erasure)
实现泛型的方式,擦拭法是指,虚拟机对泛型其实一无所知,所有的工作都是编译器做的。
局限:
局限一:<T>不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型
局限二:无法取得带泛型的Class。观察以下代码
局限三:无法判断带泛型的类型
局限四:不能实例化T类型,需要实例化时要借助Class<T>参数并通过反射来实例化T类型
集合
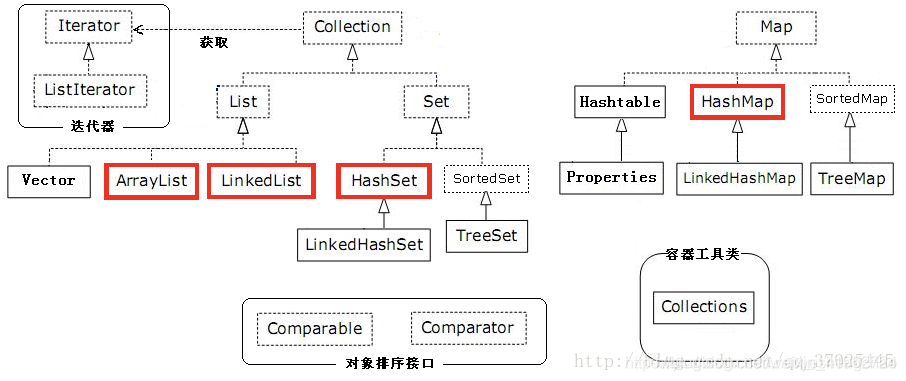
Collection
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
使用Properties
读取配置文件
用Properties读取配置文件非常简单。Java默认配置文件以.properties为扩展名,每行以key=value表示,以#课开头的是注释。以下是一个典型的配置文件:
# setting.properties
last_open_file=/data/hello.txt
auto_save_interval=60
可以从文件系统读取这个.properties文件:
String f = "setting.properties";
Properties props = new Properties();
props.load(new java.io.FileInputStream(f));
String filepath = props.getProperty("last_open_file");
String interval = props.getProperty("auto_save_interval", "120");
可见,用Properties读取配置文件,一共有三步:
- 创建
Properties实例; - 调用
load()读取文件; - 调用
getProperty()获取配置。
使用Set
只需要存储不重复的key,并不需要存储映射的value,那么就可以使用Set。
Set用于存储不重复的元素集合,它主要提供以下几个方法:
- 将元素添加进
Set<E>:boolean add(E e) - 将元素从
Set<E>删除:boolean remove(Object e) - 判断是否包含元素:
boolean contains(Object e)
Set实际上相当于只存储key、不存储value的Map
使用Queue
队列Queue实现了一个先进先出(FIFO)的数据结构:
- 通过
add()/offer()方法将元素添加到队尾; - 通过
remove()/poll()从队首获取元素并删除; - 通过
element()/peek()从队首获取元素但不删除。
要避免把null添加到队列。
使用Deque(此接口也可实现栈)
| Queue | Deque | |
|---|---|---|
| 添加元素到队尾 | add(E e) / offer(E e) | addLast(E e) / offerLast(E e) |
| 取队首元素并删除 | E remove() / E poll() | E removeFirst() / E pollFirst() |
| 取队首元素但不删除 | E element() / E peek() | E getFirst() / E peekFirst() |
| 添加元素到队首 | 无 | addFirst(E e) / offerFirst(E e) |
| 取队尾元素并删除 | 无 | E removeLast() / E pollLast() |
| 取队尾元素但不删除 | 无 | E getLast() / E peekLast() |
双端队列
Deque实现了一个双端队列(Double Ended Queue),它可以:
- 将元素添加到队尾或队首:
addLast()/offerLast()/addFirst()/offerFirst(); - 从队首/队尾获取元素并删除:
removeFirst()/pollFirst()/removeLast()/pollLast(); - 从队首/队尾获取元素但不删除:
getFirst()/peekFirst()/getLast()/peekLast(); - 总是调用
xxxFirst()/xxxLast()以便与Queue的方法区分开; - 避免把
null添加到队列。
Deque实现栈
- 把元素压栈:
push(E); - 把栈顶的元素“弹出”:
pop(E); - 取栈顶元素但不弹出:
peek(E)。
ArrayList和LinkedList区别
arraylist基于数组,访问快,插入/删除开销大
linkedlist基于双链表,可作为双向队列、栈和list集合使用,访问慢,插入/删除开销小
hashmap和hashtable的区别
继承的父类不同,都实现了map接口
hashmap线程不安全,hashtable线程安全
hashmap可以有空值,hashtable不能
计算hash值不同,hashmap效率高
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
HashMap扩容时是当前容量翻倍即:capacity2,Hashtable扩容时是容量翻倍+1即:capacity2+1
concurrent hashmap和hashtable的区别
hashtable在大小增加后性能会下降,所以前者同是线程安全的,但效率更好
StringBuilder 和 StringBuffer的区别
stringbuilder效率更高,但不是线程安全
stringbuffer线程安全,但效率略差
Hashmap的底层实现
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null 建和null值,因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。
HashMap扩容缩容机制扩容是put后如果超过阈值则使得容量和阈值都翻倍,但是负载因子不变
HashMap存储结构
JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树
HashMap rehash实现方法
IO
IO流是一种流式的数据输入/输出模型:
- 二进制数据以
byte为最小单位在InputStream/OutputStream中单向流动; - 字符数据以
char为最小单位在Reader/Writer中单向流动。
Java标准库的java.io包提供了同步IO功能:
- 字节流接口:
InputStream/OutputStream; - 字符流接口:
Reader/Writer。
File对象
Java标准库的java.io.File对象表示一个文件或者目录:
- 创建
File对象本身不涉及IO操作;
File f = new File("C:\\Windows\\notepad.exe");
- 可以获取路径/绝对路径/规范路径:
getPath()/getAbsolutePath()/getCanonicalPath(); - 可以获取目录的文件和子目录:
list()/listFiles(); - 可以创建或删除文件和目录。
InputStream
Java标准库的java.io.InputStream定义了所有输入流的超类:
FileInputStream实现了文件流输入;ByteArrayInputStream在内存中模拟一个字节流输入。
总是使用try(resource)来保证InputStream正确关闭。
OutputStream
Java标准库的java.io.OutputStream定义了所有输出流的超类:
FileOutputStream实现了文件流输出;ByteArrayOutputStream在内存中模拟一个字节流输出。
某些情况下需要手动调用OutputStream的flush()方法来强制输出缓冲区。
总是使用try(resource)来保证OutputStream正确关闭。
多线程
创建新线程
run和start
start是新建一个线程,同时如果从thread派生一个类并且重写run则可以实现多线程
或者创建的时候新建类继承runnable接口,在实例化thread时传入
Java语言内置了多线程支持。当Java程序启动的时候,实际上是启动了一个JVM进程,然后,JVM启动主线程来执行main()方法。在main()方法中,又可以启动其他线程。
要创建一个新线程非常容易,实例化一个Thread实例,然后调用它的start()方法:
// 多线程
public class Main {
public static void main(String[] args) {
Thread t = new Thread();
t.start(); // 启动新线程
}
}
但是在需要执行时,要用如下方式:
-
从
Thread派生一个自定义类,然后覆写run()方法:public class Main { public static void main(String[] args) { Thread t = new MyThread(); t.start(); // 启动新线程 } } class MyThread extends Thread { @Override public void run() { System.out.println("start new thread!"); } } -
创建
Thread实例时,传入一个Runnable实例:
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 启动新线程
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
或者用Java8引入的lambda语法进一步简写为:
public class Main {
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("start new thread!");
});
t.start(); // 启动新线程
}
}
线程的优先级
可以对线程设定优先级,设定优先级的方法是:
Thread.setPriority(int n) // 1~10, 默认值5
线程生命周期
Java线程对象Thread的状态包括:New、Runnable、Blocked、Waiting、Timed Waiting和Terminated;
使用线程池
线程池的四种创建方式
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
线程池核心参数:
corePoolSize 线程池核心线程大小
maximumPoolSize 线程池最大线程数量
keepAliveTime 空闲线程存活时间
unit 空闲线程存活时间单位
workQueue 工作队列//根据线程池类型对应不同的队列
threadFactory 线程工厂
handler 拒绝策略
线程池拒绝策略:
CallerRunsPolicy 该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
AbortPolicy 该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
DiscardPolicy 该策略下,直接丢弃任务,什么都不做。
DiscardOldestPolicy 该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
线程同步
线程安全
同步代码块:多线程同时读写共享变量时,会造成逻辑错误,因此需要通过synchronized同步
同步方法:用synchronized修饰方法可以把整个方法变为同步代码块,synchronized方法加锁对象是this
Lock锁:Java的synchronized锁是可重入锁;死锁产生的条件是多线程各自持有不同的锁,并互相试图获取对方已持有的锁,导致无限等待;避免死锁的方法是多线程获取锁的顺序要一致
同步方法
synchronized和lock的区别
synchronized:在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
lock:需要显示指定起始位置和终止位置。一般使用ReentrantLock类做为锁,在加锁和解锁处需要通过lock()和unlock()显示指出,一般会在finally块中写unlock()以防死锁。
voliate关键字
使变量在线程间可见,解决并发三大问题的可见性问题
原子类
synchronized关键字可以保证可见性和有序性却无法保证原子性,而这个AtomicInteger的作用就是为了保证原子性
CAS
上文提到的原子类就是CAS的机制,实际上使用了三个基本操作数,内存地址V、旧的预期值A、要修改的新值B
只有当A和V相同时才会将V对应的值修改为B,也就是版本检测
AQS原理
AQS即Abstract Queued Synchronizer,是一个用于构建锁和同步器的框架
AQS支持独占锁(exclusive)和共享锁(share)两种模式。
独占锁:只能被一个线程获取到
共享锁:可以被多个线程同时获取
synchronized实现原理(结合JVM 连带讲锁升级)
每个对象都关联一个Monitor,通过它来尝试获取锁
无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态(级别从低到高)
死锁
两个线程各自持有不同的锁,然后各自试图获取对方手里的锁,造成了双方无限等待下去,这就是死锁,一旦发生是没办法解决的,只能重启进程
乐观锁/悲观锁
悲观锁是利用了数据库锁的机制实现的,具有独占性和排他性,分为读锁和写锁,即都能读但只有一个能获取到写的权限
乐观锁通过CAS实现,多个线程尝试使用CAS同时更新变量时,先根据版本进行冲突检测,只有一个能成功,其他的都会失败并获取失败信息且可以再次尝试
模拟通信
TCP通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端(Client)与服务端(Server)。Java提供了两个类用于TCP通信程序
1、客户端:java.new.Socket类。创建Socket对象,向服务器发出连接请求,服务器端响应请求,两者建立连接开始通信
2、服务器端:java.net.ServiceSocket。创建ServiceSocket对象,相当于开一个服务,并等待客户端的连接
JVM
JVM原理
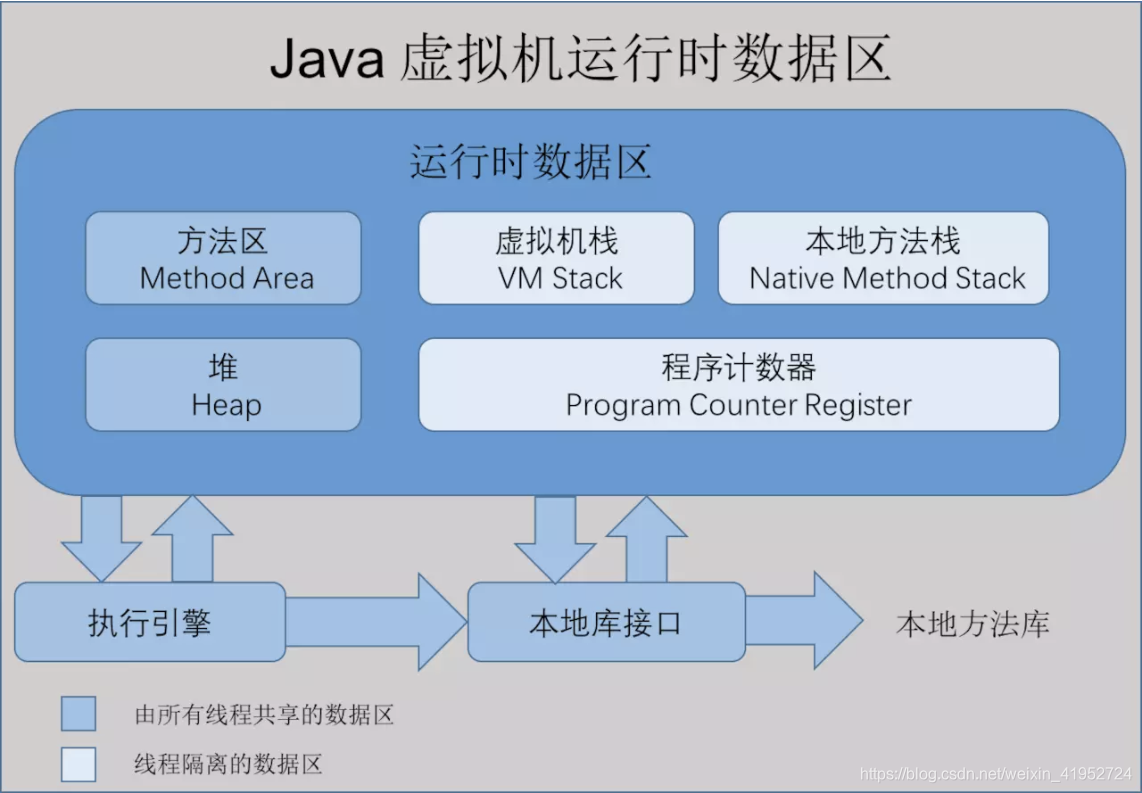
jvm类加载机制
加载 获取二进制字节流、转化为运行时数据结构、生成class对象
验证 文件格式、元数据、字节码、符号引用的验证
准备 分配内存并设置初始值,分配在方法区
解析 将符号引用转化为直接引用
初始化 调用构造函数
jvm双亲委派机制
JVM中提供了三层的ClassLoader:
Bootstrap classLoader:主要负责加载核心的类库(java.lang.*等),构造ExtClassLoader和APPClassLoader。
ExtClassLoader:主要负责加载jre/lib/ext目录下的一些扩展的jar。
AppClassLoader:主要负责加载应用程序的主函数类
如果类已经在三个类加载器中加载过,则在加载时的验证中无法通过,就不会被加载了,抛出ClassNotFoundException异常。
jvm内存分配与回收策略
对象优先在Eden分配
大对象直接进入老年代
长期存活的对象进入老年代
动态对象年龄判定
如何判断对象是否可被回收
堆中不存在该类的任何实例
加载该类的classloader已经被回收
该类的java.lang.Class对象没有在任何地方被引用,也就是说无法通过反射再带访问该类的信息
四种引用
强引用 永远不会被回收,使用强引用的对象就算内存泄漏也不会回收,默认就是强引用
软引用 对应实体类SoftReference 发生oom前才会回收
弱引用 对应实体类WeakReference 如果所引用的对象为null,则不论内存是否充足都会被回收,否则不会被回收
虚引用 对应实体类PhantonReference 不论所引用的对象是不是null,不论内存空间是否充足,都会被垃圾回收器回收
jvm有垃圾回收机制为什么还会oom
在堆中
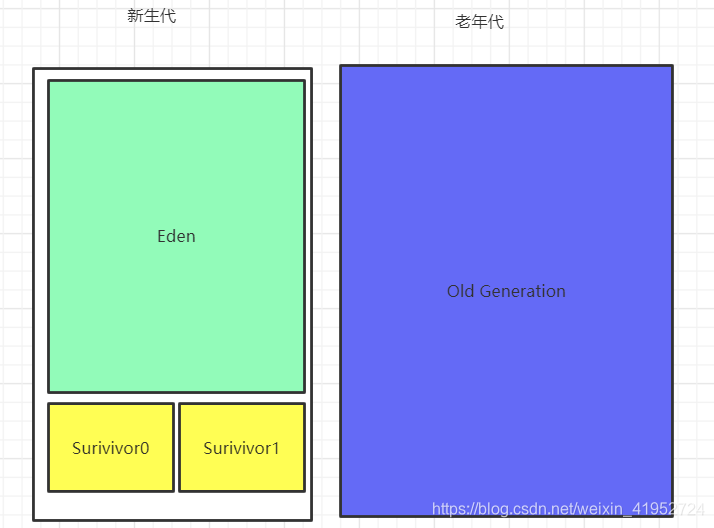
新生代与老年代

老年代中都是老对象、大对象,一般很少产生FGC,如果产生是YGC的十倍时耗,如果老年代也满了就会报OOM
垃圾回收
1、新建的对象,大部分存储在Eden中
2、当Eden内存不够,就进行Minor GC释放掉不活跃对象;然后将部分活跃对象复制到Survivor中(如Survivor1),同时清空Eden区
3、当Eden区再次满了,将Survivor1中不能清空的对象存放到另一个Survivor中(如Survivor2),同时将Eden区中的不能清空的对象,复制到Survivor1,同时清空Eden区
4、重复多次(默认15次):Survivor中没有被清理的对象就会复制到老年区(Old)
5、当Old达到一定比例,则会触发Major GC释放老年代
6、当Old区满了,则触发一个一次完整的垃圾回收(Full GC)
7、如果内存还是不够,JVM会抛出内存不足,发生oom,内存泄漏。
回收方法
1)标记—清除算法,例如CMS收集器
两个阶段:标记,清除;
不足:效率问题;空间问题(会产生大量不连续的内存碎片)
2)复制算法
将可用内存按容量分为大小相等的两块,每次都只使用其中一块;
不足:将内存缩小为了原来的一半
新生代
3)标记—整理算法
标记,清除(让存活的对象都向一端移动)
老年代
1.8中的新特性
default关键字
lambda表达式
函数式接口
方法与构造函数通过::引用
局部变量限制
DateAPI更新
流
多重注解
Maven
简介
java包管理和构建工具
一个使用Maven管理的普通的Java项目,它的目录结构默认如下:
a-maven-project
├── pom.xml
├── src
│ ├── main
│ │ ├── java
│ │ └── resources
│ └── test
│ ├── java
│ └── resources
└── target
pom.xml是maven的项目描述文件
<project ...>
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>hello</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
...
</properties>
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
</project>
依赖管理
依赖关系
Maven定义了几种依赖关系,分别是compile、test、runtime和provided:
| scope | 说明 | 示例 |
|---|---|---|
| compile | 编译时需要用到该jar包(默认) | commons-logging |
| test | 编译Test时需要用到该jar包 | junit |
| runtime | 编译时不需要,但运行时需要用到 | mysql |
| provided | 编译时需要用到,但运行时由JDK或某个服务器提供 | servlet-api |
其中,默认的compile是最常用的,Maven会把这种类型的依赖直接放入classpath。
test依赖表示仅在测试时使用,正常运行时并不需要。最常用的test依赖就是JUnit:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.3.2</version>
<scope>test</scope>
</dependency>
runtime依赖表示编译时不需要,但运行时需要。最典型的runtime依赖是JDBC驱动,例如MySQL驱动:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
<scope>runtime</scope>
</dependency>
provided依赖表示编译时需要,但运行时不需要。最典型的provided依赖是Servlet API,编译的时候需要,但是运行时,Servlet服务器内置了相关的jar,所以运行期不需要:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.0</version>
<scope>provided</scope>
</dependency>
Maven并不会每次都从中央仓库下载jar包。一个jar包一旦被下载过,就会被Maven自动缓存在本地目录(用户主目录的.m2目录),所以,除了第一次编译时因为下载需要时间会比较慢,后续过程因为有本地缓存,并不会重复下载相同的jar包。
唯一ID
对于某个依赖,Maven只需要3个变量即可唯一确定某个jar包:
- groupId:属于组织的名称,类似Java的包名;
- artifactId:该jar包自身的名称,类似Java的类名;
- version:该jar包的版本。
通过上述3个变量,即可唯一确定某个jar包。Maven通过对jar包进行PGP签名确保任何一个jar包一经发布就无法修改。修改已发布jar包的唯一方法是发布一个新版本。
构建流程
在实际开发过程中,经常使用的命令有:
mvn clean:清理所有生成的class和jar;
mvn clean compile:先清理,再执行到compile;
mvn clean test:先清理,再执行到test,因为执行test前必须执行compile,所以这里不必指定compile;
mvn clean package:先清理,再执行到package。
大多数phase在执行过程中,因为通常没有在pom.xml中配置相关的设置,所以这些phase什么事情都不做。
经常用到的phase其实只有几个:
- clean:清理
- compile:编译
- test:运行测试
- package:打包
依赖冲突
最短路径优先->路径相同->最先声明优先
移除依赖(exclusions)
使用插件
如果标准插件无法满足需求,还可以使用自定义插件。使用自定义插件的时候,需要声明。例如,使用maven-shade-plugin可以创建一个可执行的jar,要使用这个插件,需要在pom.xml中声明它:
<project>
...
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
...
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
自定义插件往往需要一些配置,例如,maven-shade-plugin需要指定Java程序的入口,它的配置是:
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.itranswarp.learnjava.Main</mainClass>
</transformer>
</transformers>
</configuration>
注意,Maven自带的标准插件例如compiler是无需声明的,只有引入其它的插件才需要声明。
模块管理
对于Maven工程来说,原来是一个大项目:
single-project
├── pom.xml
└── src
可以看出来,模块A和模块B的pom.xml高度相似,因此,可以提取出共同部分作为parent:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>parent</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
注意到parent的<packaging>是pom而不是jar,因为parent本身不含任何Java代码。编写parent的pom.xml只是为了在各个模块中减少重复的配置。现在的整个工程结构如下:
multiple-project
├── pom.xml
├── parent
│ └── pom.xml
├── module-a
│ ├── pom.xml
│ └── src
├── module-b
│ ├── pom.xml
│ └── src
└── module-c
├── pom.xml
└── src
这样模块A就可以简化为:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<relativePath>../parent/pom.xml</relativePath>
</parent>
<artifactId>module-a</artifactId>
<packaging>jar</packaging>
<name>module-a</name>
</project>
模块B、模块C都可以直接从parent继承,大幅简化了pom.xml的编写。
如果模块A依赖模块B,则模块A需要模块B的jar包才能正常编译,需要在模块A中引入模块B:
...
<dependencies>
<dependency>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-b</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
最后,在编译的时候,需要在根目录创建一个pom.xml统一编译:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>build</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>build</name>
<modules>
<module>parent</module>
<module>module-a</module>
<module>module-b</module>
<module>module-c</module>
</modules>
</project>
这样,在根目录执行mvn clean package时,Maven根据根目录的pom.xml找到包括parent在内的共4个<module>,一次性全部编译。
网络编程
TCP编程&Socket
使用Java进行TCP编程时,需要使用Socket模型:
- 服务器端用
ServerSocket监听指定端口; - 客户端使用
Socket(InetAddress, port)连接服务器; - 服务器端用
accept()接收连接并返回Socket; - 双方通过
Socket打开InputStream/OutputStream读写数据; - 服务器端通常使用多线程同时处理多个客户端连接,利用线程池可大幅提升效率;
flush()用于强制输出缓冲区到网络。
UDP编程
UDP没有创建连接,数据包也是一次收发一个,所以没有流的概念
使用UDP协议通信时,服务器和客户端双方无需建立连接:
- 服务器端用
DatagramSocket(port)监听端口; - 客户端使用
DatagramSocket.connect()指定远程地址和端口; - 双方通过
receive()和send()读写数据; DatagramSocket没有IO流接口,数据被直接写入byte[]缓冲区。
HTTP编程
完整HTTP请求
GET / HTTP/1.1
Host: www.sina.com.cn
User-Agent: Mozilla/5 MSIE
Accept: */* ┌────────┐
┌─────────┐ Accept-Language: zh-CN,en │░░░░░░░░│
│O ░░░░░░░│───────────────────────────>├────────┤
├─────────┤<───────────────────────────│░░░░░░░░│
│ │ HTTP/1.1 200 OK ├────────┤
│ │ Content-Type: text/html │░░░░░░░░│
└─────────┘ Content-Length: 133251 └────────┘
Browser <!DOCTYPE html> Server
<html><body>
<h1>Hello</h1>
...
HTTP请求
HTTP请求的格式是固定的,它由HTTP Header和HTTP Body两部分构成,如果是GET请求,是没有Body的。一个典型的带Body的HTTP请求如下:
POST /login HTTP/1.1
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 30
username=hello&password=123456
POST请求通常要设置Content-Type表示Body的类型,Content-Length表示Body的长度,这样服务器就可以根据请求的Header和Body做出正确的响应。常见的发送JSON的POST请求如下:
POST /login HTTP/1.1
Content-Type: application/json
Content-Length: 38
{"username":"bob","password":"123456"}
HTTP响应
HTTP响应也是由Header和Body两部分组成,一个典型的HTTP响应如下:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 133251
<!DOCTYPE html>
<html><body>
<h1>Hello</h1>
...
JAVA发送HTTP请求
Java提供了HttpClient作为新的HTTP客户端编程接口用于取代老的HttpURLConnection接口;
HttpClient使用链式调用并通过内置的BodyPublishers和BodyHandlers来更方便地处理数据。
import java.net.URI;
import java.net.http.*;
import java.net.http.HttpClient.Version;
import java.time.Duration;
import java.util.*;
//发送一个GET请求
public class Main {
// 全局HttpClient:
static HttpClient httpClient = HttpClient.newBuilder().build();
public static void main(String[] args) throws Exception {
String url = "https://www.sina.com.cn/";
HttpRequest request = HttpRequest.newBuilder(new URI(url))
// 设置Header:
.header("User-Agent", "Java HttpClient").header("Accept", "*/*")
// 设置超时:
.timeout(Duration.ofSeconds(5))
// 设置版本:
.version(Version.HTTP_2).build();
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// HTTP允许重复的Header,因此一个Header可对应多个Value:
Map<String, List<String>> headers = response.headers().map();
for (String header : headers.keySet()) {
System.out.println(header + ": " + headers.get(header).get(0));
}
System.out.println(response.body().substring(0, 1024) + "...");
}
}
//发送一个POST请求
String url = "http://www.example.com/login";
String body = "username=bob&password=123456";
HttpRequest request = HttpRequest.newBuilder(new URI(url))
// 设置Header:
.header("Accept", "*/*")
.header("Content-Type", "application/x-www-form-urlencoded")
// 设置超时:
.timeout(Duration.ofSeconds(5))
// 设置版本:
.version(Version.HTTP_2)
// 使用POST并设置Body:
.POST(BodyPublishers.ofString(body, StandardCharsets.UTF_8)).build();
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
String s = response.body();
XML与JSON
使用DOM解析XML
示例文档结构
Document: #document
Element: book
Text: #text =
Element: name
Text: #text = Java核心技术
Text: #text =
Element: author
Text: #text = Cay S. Horstmann
Text: #text =
...
使用DOM API解析一个XML文档的代码如下:
InputStream input = Main.class.getResourceAsStream("/book.xml");
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(input);
//遍历以便读取指定元素的值
void printNode(Node n, int indent) {
for (int i = 0; i < indent; i++) {
System.out.print(' ');
}
switch (n.getNodeType()) {
case Node.DOCUMENT_NODE: // Document节点
System.out.println("Document: " + n.getNodeName());
break;
case Node.ELEMENT_NODE: // 元素节点
System.out.println("Element: " + n.getNodeName());
break;
case Node.TEXT_NODE: // 文本
System.out.println("Text: " + n.getNodeName() + " = " + n.getNodeValue());
break;
case Node.ATTRIBUTE_NODE: // 属性
System.out.println("Attr: " + n.getNodeName() + " = " + n.getNodeValue());
break;
default: // 其他
System.out.println("NodeType: " + n.getNodeType() + ", NodeName: " + n.getNodeName());
}
for (Node child = n.getFirstChild(); child != null; child = child.getNextSibling()) {
printNode(child, indent + 1);
}
}
使用Jackson解析XML
可以直接将XML文档解析成JavaBean
在Maven里添加依赖
com.fasterxml.jackson.dataformat:jackson-dataformat-xml:2.10.1
org.codehaus.woodstox:woodstox-core-asl:4.4.1
源文档
<?xml version="1.0" encoding="UTF-8" ?>
<book id="1">
<name>Java核心技术</name>
<author>Cay S. Horstmann</author>
<isbn lang="CN">1234567</isbn>
<tags>
<tag>Java</tag>
<tag>Network</tag>
</tags>
<pubDate/>
</book>
解析成JavaBean
//定义一个javabean
public class Book {
public long id;
public String name;
public String author;
public String isbn;
public List<String> tags;
public String pubDate;
}
//解析
InputStream input = Main.class.getResourceAsStream("/book.xml");
JacksonXmlModule module = new JacksonXmlModule();
XmlMapper mapper = new XmlMapper(module);
Book book = mapper.readValue(input, Book.class);
JSON
使用JACKSON也可以解析JSON,引入以下Maven依赖:
- com.fasterxml.jackson.core:jackson-databind:2.10.0
就可以使用下面的代码解析一个JSON文件:
//定义一个javabean
public class Book {
public long id;
public String name;
public String author;
public String isbn;
public List<String> tags;
public String pubDate;
}
//解析
InputStream input = Main.class.getResourceAsStream("/book.json");
ObjectMapper mapper = new ObjectMapper();
// 反序列化时忽略不存在的JavaBean属性:
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
Book book = mapper.readValue(input, Book.class);
JDBC编程
结构
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
│ ┌───────────────┐ │
│ Java App │
│ └───────────────┘ │
│
│ ▼ │
┌───────────────┐
│ │JDBC Interface │<─┼─── JDK
└───────────────┘
│ │ │
▼
│ ┌───────────────┐ │
│ JDBC Driver │<───── Vendor
│ └───────────────┘ │
│
└ ─ ─ ─ ─ ─│─ ─ ─ ─ ─ ┘
▼
┌───────────────┐
│ Database │
└───────────────┘
Java程序本身只需要引入一个MySQL驱动的jar包就可以正常访问MySQL服务器:
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
┌───────────────┐
│ │ App.class │ │
└───────────────┘
│ │ │
▼
│ ┌───────────────┐ │
│ java.sql.* │
│ └───────────────┘ │
│
│ ▼ │
┌───────────────┐ TCP ┌───────────────┐
│ │ mysql-xxx.jar │──┼────────>│ MySQL │
└───────────────┘ └───────────────┘
└ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
JVM
JDBC连接
要获取数据库连接,使用如下代码:
// JDBC连接的URL, 不同数据库有不同的格式:
String JDBC_URL = "jdbc:mysql://localhost:3306/test";
String JDBC_USER = "root";
String JDBC_PASSWORD = "password";
// 获取连接:
Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD);
// TODO: 访问数据库...
// 关闭连接:
conn.close();
JDBC CRUD
C
通过JDBC进行插入,本质上也是用PreparedStatement执行一条SQL语句,不过最后执行的不是executeQuery(),而是executeUpdate()。示例代码如下:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement(
"INSERT INTO students (id, grade, name, gender) VALUES (?,?,?,?)")) {
ps.setObject(1, 999); // 注意:索引从1开始
ps.setObject(2, 1); // grade
ps.setObject(3, "Bob"); // name
ps.setObject(4, "M"); // gender
int n = ps.executeUpdate(); // 1
}
}
R
第一步,通过Connection提供的createStatement()方法创建一个Statement对象,用于执行一个查询;
第二步,执行Statement对象提供的executeQuery("SELECT * FROM students")并传入SQL语句,执行查询并获得返回的结果集,使用ResultSet来引用这个结果集;
第三步,反复调用ResultSet的next()方法并读取每一行结果。
完整查询代码如下:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (Statement stmt = conn.createStatement()) {
try (ResultSet rs = stmt.executeQuery("SELECT id, grade, name, gender FROM students WHERE gender=1")) {
while (rs.next()) {
long id = rs.getLong(1); // 注意:索引从1开始
long grade = rs.getLong(2);
String name = rs.getString(3);
int gender = rs.getInt(4);
}
}
}
}
为了解决SQL注入的问题,使用PreparedStatement进行查询
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("SELECT id, grade, name, gender FROM students WHERE gender=? AND grade=?")) {
ps.setObject(1, "M"); // 注意:索引从1开始
ps.setObject(2, 3);
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
long id = rs.getLong("id");
long grade = rs.getLong("grade");
String name = rs.getString("name");
String gender = rs.getString("gender");
}
}
}
}
U
更新操作是UPDATE语句,它可以一次更新若干列的记录。更新操作和插入操作在JDBC代码的层面上实际上没有区别,除了SQL语句不同:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("UPDATE students SET name=? WHERE id=?")) {
ps.setObject(1, "Bob"); // 注意:索引从1开始
ps.setObject(2, 999);
int n = ps.executeUpdate(); // 返回更新的行数
}
}
D
删除操作是DELETE语句,它可以一次删除若干列。和更新一样,除了SQL语句不同外,JDBC代码都是相同的:
try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {
try (PreparedStatement ps = conn.prepareStatement("DELETE FROM students WHERE id=?")) {
ps.setObject(1, 999); // 注意:索引从1开始
int n = ps.executeUpdate(); // 删除的行数
}
}
JDBC事务
connection.setAutoCommit(false);//打开事务。
connection.commit();//提交事务。
connection.rollback();//回滚事务。
这里需要提的就是,当只想撤销事务中的部分操作时可使用SavePoint:
SavePoint sp = connection.setSavepoint();
connection.rollerbak(sp);connection.commit();
函数式编程
Lambda表达式
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
//Lambda表达式
Arrays.sort(array, (s1, s2) -> {
return s1.compareTo(s2);
});
使用Stream
与java.io的对比
这个Stream不同于java.io的InputStream和OutputStream,它代表的是任意Java对象的序列。两者对比如下:
| java.io | java.util.stream | |
|---|---|---|
| 存储 | 顺序读写的byte或char | 顺序输出的任意Java对象实例 |
| 用途 | 序列化至文件或网络 | 内存计算/业务逻辑 |
| 元素 | 已分配并存储在内存 | 可能未分配,实时计算 |
因此,Stream API的基本用法就是:创建一个Stream,然后做若干次转换,最后调用一个求值方法获取真正计算的结果:
int result = createNaturalStream() // 创建Stream
.filter(n -> n % 2 == 0) // 任意个转换
.map(n -> n * n) // 任意个转换
.limit(100) // 任意个转换
.sum(); // 最终计算结果
必须定义limit才能打印
创建Stream
- 通过指定元素、指定数组、指定
Collection创建Stream; Stream stream = List.of(“X”, “Y”, “Z”).stream(); - 通过
Supplier创建Stream,可以是无限序列; Stream s = Stream.generate(Supplier sp); - 通过其他类的相关方法创建。 Stream i = Stream.of(1 , 2);
基本类型的Stream有IntStream、LongStream和DoubleStream。
使用map
Stream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream。
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s2 = s.map(n -> n * n);
使用filter
Stream.filter()是Stream的另一个常用转换方法。
使用filter()方法可以对一个Stream的每个元素进行测试,通过测试的元素被过滤后生成一个新的Stream。
Stream.generate(new LocalDateSupplier())
.limit(31)
.filter(ldt -> ldt.getDayOfWeek() == DayOfWeek.SATURDAY || ldt.getDayOfWeek() == DayOfWeek.SUNDAY)
.forEach(System.out::println);
使用reduce
map()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果,聚合方法会立刻对Stream进行计算。
reduce()方法将一个Stream的每个元素依次作用于BinaryOperator,并将结果合并。
int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);
输出集合
Stream通过collect()方法可以方便地输出为List、Set、Map,还可以分组输出。
//分组输出
List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
其他操作
Stream提供的常用操作有:
转换操作:map(),filter(),sorted(),distinct();
合并操作:concat(),flatMap();
并行处理:parallel();
聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();
其他操作:allMatch(), anyMatch(), forEach()。
设计模式(见外面的设计模式.md)
Web开发
Servlet API(类似C# WebAPI)
servlet生命周期
主要有三个方法:
init()初始化阶段
service()处理客户端请求阶段
destroy()终止阶段
┌───────────┐
│My Servlet │
├───────────┤
│Servlet API│
┌───────┐ HTTP ├───────────┤
│Browser│<──────>│Web Server │
└───────┘ └───────────┘
实现一个最简单的Servlet:
// WebServlet注解表示这是一个Servlet,并映射到地址/:
@WebServlet(urlPatterns = "/")
public class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
// 设置响应类型:
resp.setContentType("text/html");
// 获取输出流:
PrintWriter pw = resp.getWriter();
// 写入响应:
pw.write("<h1>Hello, world!</h1>");
// 最后不要忘记flush强制输出:
pw.flush();
}
}
Servlet API是一个jar包,需要通过Maven来引入它,才能正常编译。编写pom.xml文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>web-servlet-hello</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>hello</finalName>
</build>
</project>
还需要在工程目录下创建一个web.xml描述文件,放到src/main/webapp/WEB-INF目录下(固定目录结构,不要修改路径,注意大小写)。文件内容可以固定如下:
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>Archetype Created Web Application</display-name>
</web-app>
整个工程结构如下:
web-servlet-hello
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── itranswarp
│ └── learnjava
│ └── servlet
│ └── HelloServlet.java
├── resources
└── webapp
└── WEB-INF
└── web.xml
运行Maven命令mvn clean package,在target目录下得到一个hello.war文件,这个文件就是编译打包后的Web应用程序
要运行hello.war,首先要下载Tomcat服务器,解压后,把hello.war复制到Tomcat的webapps目录下,然后切换到bin目录,执行startup.sh或startup.bat启动Tomcat服务器:
$ ./startup.sh
Using CATALINA_BASE: .../apache-tomcat-9.0.30
Using CATALINA_HOME: .../apache-tomcat-9.0.30
Using CATALINA_TMPDIR: .../apache-tomcat-9.0.30/temp
Using JRE_HOME: .../jdk-11.jdk/Contents/Home
Using CLASSPATH: .../apache-tomcat-9.0.30/bin/bootstrap.jar:...
Tomcat started.
在浏览器输入http://localhost:8080/hello/即可看到HelloServlet的输出
如果想直接使用/而不是/hello/
先关闭Tomcat(执行shutdown.sh或shutdown.bat),然后删除Tomcat的webapps目录下的所有文件夹和文件,最后把hello.war复制过来,改名为ROOT.war,文件名为ROOT的应用程序将作为默认应用,启动后直接访问http://localhost:8080/即可。
请求乱码
- Tomcat8及以上版本不存在乱码问题
- Tomcat7及之前的服务器使用的是ISO8859-1编码,不支持中文
解决方案一:全局配置:修改server.xml文件中的节点,添加编码方式属性
解决方案二:代码级别配置:在servlet中接收到请求后,对乱码字符串进行解码和重新编码 - 在servlet的doPost方法中添加:request.setCharacterEncoding(“UTF-8”);
响应乱码
- 解决方案一:response.setCharacterEncoding(“UTF-8”);
- 解决方案二:修改响应头信息
response.setHeader(“Content-Type”, “text/html;charset=UTF-8”);
不配置Tomcat在IDE中直接开发webapp
流程
因为Tomcat本身也是通过java开发的,因此可以通过直接引用Tomcat的jar包,然后自己编写main方法(似乎更像webapi了呢)。
编写pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>web-servlet-embedded</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
<tomcat.version>9.0.26</tomcat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-core</artifactId>
<version>${tomcat.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<version>${tomcat.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
随后编写webapp主体
public class Main {
public static void main(String[] args) throws Exception {
// 启动Tomcat:
Tomcat tomcat = new Tomcat();
tomcat.setPort(Integer.getInteger("port", 8080));
tomcat.getConnector();
// 创建webapp:
Context ctx = tomcat.addWebapp("", new File("src/main/webapp").getAbsolutePath());
WebResourceRoot resources = new StandardRoot(ctx);
resources.addPreResources(
new DirResourceSet(resources, "/WEB-INF/classes", new File("target/classes").getAbsolutePath(), "/"));
ctx.setResources(resources);
tomcat.start();
tomcat.getServer().await();
}
}
@WebServlet(urlPatterns = "/hello")
class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html");
String name = req.getParameter("name");
if (name == null) {
name = "world";
}
PrintWriter pw = resp.getWriter();
pw.write("<h1>Hello, " + name + "!</h1>");
pw.flush();
}
}
//其他接口
@WebServlet(urlPatterns = "/signin")
public class SignInServlet extends HttpServlet {
...
}
@WebServlet(urlPatterns = "/")
public class IndexServlet extends HttpServlet {
...
}
Flush与Close
close()关闭流对象,但是先刷新一次缓冲区,关闭之后,流对象不可以继续再使用了。
flush()仅仅是刷新缓冲区(一般写字符时要用,因为字符是先进入的缓冲区),流对象还可以继续使用
写入完毕后对输出流调用flush()而不是close()方法!
Servlet进阶
重定向
已经编写了一个能处理/hello的HelloServlet,如果收到的路径为/hi,希望能重定向到/hello,可以再编写一个RedirectServlet:
@WebServlet(urlPatterns = "/hi")
public class RedirectServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 构造重定向的路径:
String name = req.getParameter("name");
String redirectToUrl = "/hello" + (name == null ? "" : "?name=" + name);
// 发送重定向响应:
resp.sendRedirect(redirectToUrl);
//如果要实现301永久重定向,可以这么写:
//resp.setStatus(HttpServletResponse.SC_MOVED_PERMANENTLY); // 301
//resp.setHeader("Location", "/hello");
}
}
重定向有两种:一种是302响应,称为临时重定向,一种是301响应,称为永久重定向。两者的区别是,如果服务器发送301永久重定向响应,浏览器会缓存/hi到/hello这个重定向的关联,下次请求/hi的时候,浏览器就直接发送/hello请求了。
转发
已经编写了一个能处理/hello的HelloServlet,继续编写一个能处理/morning的ForwardServlet:
@WebServlet(urlPatterns = "/morning")
public class ForwardServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.getRequestDispatcher("/hello").forward(req, resp);
}
}
ForwardServlet在收到请求后,它并不自己发送响应,而是把请求和响应都转发给路径为/hello的Servlet。
转发和重定向的区别在于,转发是在Web服务器内部完成的,对浏览器来说,它只发出了一个HTTP请求,而重定向不是。
使用Session和Cookie
把这种基于唯一ID识别用户身份的机制称为Session。每个用户第一次访问服务器后,会自动获得一个Session ID。如果用户在一段时间内没有访问服务器,那么Session会自动失效,下次即使带着上次分配的Session ID访问,服务器也认为这是一个新用户,会分配新的Session ID。
以登录为例,当一个用户登录成功后,就可以把这个用户的名字放入一个HttpSession对象,以便后续访问其他页面的时候,能直接从HttpSession取出用户名:
@WebServlet(urlPatterns = "/signin")
public class SignInServlet extends HttpServlet {
// 模拟一个数据库:
private Map<String, String> users = Map.of("bob", "bob123", "alice", "alice123", "tom", "tomcat");
// GET请求时显示登录页:
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html");
PrintWriter pw = resp.getWriter();
pw.write("<h1>Sign In</h1>");
pw.write("<form action=\"/signin\" method=\"post\">");
pw.write("<p>Username: <input name=\"username\"></p>");
pw.write("<p>Password: <input name=\"password\" type=\"password\"></p>");
pw.write("<p><button type=\"submit\">Sign In</button> <a href=\"/\">Cancel</a></p>");
pw.write("</form>");
pw.flush();
}
// POST请求时处理用户登录:
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String name = req.getParameter("username");
String password = req.getParameter("password");
String expectedPassword = users.get(name.toLowerCase());
if (expectedPassword != null && expectedPassword.equals(password)) {
// 登录成功:
req.getSession().setAttribute("user", name);
resp.sendRedirect("/");
} else {
resp.sendError(HttpServletResponse.SC_FORBIDDEN);
}
}
}
上述SignInServlet在判断用户登录成功后,立刻将用户名放入当前HttpSession中:
HttpSession session = req.getSession();
session.setAttribute("user", name);
在IndexServlet中,可以从HttpSession取出用户名:
@WebServlet(urlPatterns = "/")
public class IndexServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 从HttpSession获取当前用户名:
String user = (String) req.getSession().getAttribute("user");
resp.setContentType("text/html");
resp.setCharacterEncoding("UTF-8");
resp.setHeader("X-Powered-By", "JavaEE Servlet");
PrintWriter pw = resp.getWriter();
pw.write("<h1>Welcome, " + (user != null ? user : "Guest") + "</h1>");
if (user == null) {
// 未登录,显示登录链接:
pw.write("<p><a href=\"/signin\">Sign In</a></p>");
} else {
// 已登录,显示登出链接:
pw.write("<p><a href=\"/signout\">Sign Out</a></p>");
}
pw.flush();
}
}
如果用户已登录,可以通过访问/signout登出。登出逻辑就是从HttpSession中移除用户相关信息:
@WebServlet(urlPatterns = "/signout")
public class SignOutServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 从HttpSession移除用户名:
req.getSession().removeAttribute("user");
resp.sendRedirect("/");
}
}
JSP开发(已很少使用)
JSP是Java Server Pages的缩写,它的文件必须放到/src/main/webapp下,文件名必须以.jsp结尾,整个文件与HTML并无太大区别,但需要插入变量,或者动态输出的地方,使用特殊指令<% ... %>。
编写一个hello.jsp,内容如下:
<html>
<head>
<title>Hello World - JSP</title>
</head>
<body>
<%-- JSP Comment --%>
<h1>Hello World!</h1>
<p>
<%
out.println("Your IP address is ");
%>
<span style="color:red">
<%= request.getRemoteAddr() %>
</span>
</p>
</body>
</html>
MVC开发
原理
把UserServlet看作业务逻辑处理,把User看作模型,把user.jsp看作渲染,这种设计模式通常被称为MVC:Model-View-Controller,即UserServlet作为控制器(Controller),User作为模型(Model),user.jsp作为视图(View),整个MVC架构如下:
┌───────────────────────┐
┌────>│Controller: UserServlet│
│ └───────────────────────┘
│ │
┌───────┐ │ ┌─────┴─────┐
│Browser│────┘ │Model: User│
│ │<───┐ └─────┬─────┘
└───────┘ │ │
│ ▼
│ ┌───────────────────────┐
└─────│ View: user.jsp │
└───────────────────────┘
设计MVC框架(没写完,我看傻了)
先定义一个ModelAndView
public class ModelAndView {
Map<String, Object> model;
String view;
}
这个MVC的架构如下:
HTTP Request ┌─────────────────┐
──────────────────>│DispatcherServlet│
└─────────────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌───────────┐┌───────────┐┌───────────┐
│Controller1││Controller2││Controller3│
└───────────┘└───────────┘└───────────┘
│ │ │
└────────────┼────────────┘
▼
HTTP Response ┌────────────────────┐
<────────────────│render(ModelAndView)│
└────────────────────┘
打包jar包命令
jar {ctxu}[vfm0Mi] [jar-文件] [manifest-文件] [-C 目录] 文件名 …
jar cvfm classes.jar mymanifest -C foo/ .


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









