



 本文详细介绍了SQL的基础知识,包括书写顺序与执行顺序的区别、数据类型的选择与使用、DDL、DML及事务控制等内容,并深入探讨了SELECT、INSERT、DELETE等语句的应用,以及IN与EXISTS、NOT IN与NOT EXISTS的区别。
本文详细介绍了SQL的基础知识,包括书写顺序与执行顺序的区别、数据类型的选择与使用、DDL、DML及事务控制等内容,并深入探讨了SELECT、INSERT、DELETE等语句的应用,以及IN与EXISTS、NOT IN与NOT EXISTS的区别。
1.sql基本功
sql也是一门语言,我认为掌握sql最基本的就是掌握好sql的书写顺序和执行顺序,才能对我们在应对业务逻辑书写sql中最基本的东西。书写顺序是规定了sql的语法,执行顺序是这条语句在数据库中运行时的对数据的操作,所以我们也可以根据sql的执行顺序来提高书写的sql的性能。
sql的书写顺序:select,from,where,group by,having,union,order by
sql的执行顺序:from,where,group by,having,select,distinct,union,order by
如果语句中使用了group by,那么在select中要使用聚合函数,如果不用聚合函数,那么和没有group by的效果是一样的。
sql语言的几个部分
DDL:数据库定义语言(Data-Definition Language),修改关系和删除关系,包括定义视图的命令,包括定义对关系和视图的访问权限的命令。
DML:数据操纵语言(Data-Manipulation Language)提供从数据库查询信息。
事务控制:sql包括定义事务的开始和结束命令
2.sql支持查询字段的类型
char(n):固定长度的字符串,由用户来指定长度。
varchar(n):可变长度的字符串,用户指定的最大长度n,
int:整数类型,
smallint:小整数类型。
numberic(p,d):精度由用户指定,这个数有p位数字,其中d位数字在小数点右侧,例如:numberic(8,2),指字段是数字型,长度为8,小数位有2位,整数位有6位。
float(n):精度至少为n位的浮点数。
bigdecimal:java中用来表示小数的有doule,float和bigdecimal,然而doule和float会损失精度。bigdecimal适用与金融场合且小数位不多的时候,但是如果小数位较多,建议整体变成bigint。
有两种方式创建bigdecimal类型的数据;
代码:
BigDecimal b1 = new BigDecimal(16.213213);
BigDecimal b2 = new BigDecimal(4.9761636);
BigDecimal b3 = b1.add(b2);
System.out.println("b3:"+b3);//实际运算:21.1893766
System.out.println("==============");
BigDecimal d1 = BigDecimal.valueOf(16.213213);
BigDecimal d2 = BigDecimal.valueOf(4.9761636);
BigDecimal d3 = d1.add(d2);
System.out.println("d3:"+d3);
运行结果:

通过上述的代码和运行结果可知,这两种方式运行的结果并不一样。显然valueof方法更加准确。通过看底层代码可知,这两种方法都是创建了新的对象,
而直接new BigDecimal()针对构造方法的不同进行了复杂的运算
2.代码
BigDecimal bigLoanAmount = new BigDecimal("12.17897897987897"); //创建BigDecimal对象
BigDecimal bigInterestRate = new BigDecimal(12);
BigDecimal bigInterest = bigLoanAmount.multiply(bigInterestRate); //BigDecimal运算
NumberFormat currency = NumberFormat.getCurrencyInstance(); //建立货币格式化引用
NumberFormat percent = NumberFormat.getPercentInstance(); //建立百分比格式化用
percent.setMaximumFractionDigits(3); //百分比小数点最多3位
//利用BigDecimal对象作为参数在format()中调用货币和百分比格式化
System.out.println("Loan amount:\t" + currency.format(bigLoanAmount));
System.out.println("Interest rate:\t" + percent.format(bigInterestRate));
System.out.println("Interest:\t" + currency.format(bigInterest));
运行结果:
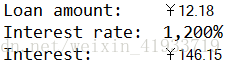
decimal:属于sql server和mysql等数据库的类型,不属于浮点数类型。在定义时划定整数部分和小数部分的位数,使用精确小数类型不仅能够保证数据计算更为精确,还可以节省存储空间,例如百分比使用decimal(4,2),一个decimal类型的数据占用了2-17个字节。使用与财务和货币计算。
p (有效位数)
可储存的最大十进位数总数,小数点左右两侧都包括在内。有效位数必须是 1 至最大有效位数 38 之间的值。预设有效位数是 18。
s (小数位数)
小数点右侧所能储存的最大十进位数。小数位数必须是从 0 到 p 的值。只有在指定了有效位数时,才能指定小数位数。预设小数位数是 0;因此,0 <= s <= p。最大储存体大小会随著有效位数而不同。
Decimal(n,m)表示数值中共有n位数,其中整数n-m位,小数m位。例:decimal(10,6),数值中共有10位数,其中整数占4位,小数占6位。
例:decimal(2,1),此时,插入数据“12.3”、“12”等会出现“数据溢出错误”的异常;插入“1.23”或“1.2345...”会自动四舍五入成“1.2”;插入“2”会自动补成“2.0”,以确保2位的有效长度,其中包含1位小数。
当用 int类型会有溢出时,可以用 decimal 类型进行处理,把结果可以用 convert 或是 cast 进行转换。
numeric和decimal的区别?
两个默认最大精度是38,最多可存储38个数字
number(p,s):p的默认值是38,s的默认值是-84-127;
两者功能一样,只不过存储的范围不一样。decimal要小一些。
decimal(p,s):p:0-38,s:0-p。取值范围是:-1038+1到1038-1。
decimal没有存储值的近似值,当数据值一定要按照指定精确存储时,可以用带有小数的decimal数据类型来存储数字。
3.sql--create
create table department
(dept_name VARCHAR(20),
building varchar(15),
budget numeric(12,2),
PRIMARY key (dept_name)
);
外键:foreign key(dept_name)references department
not null:表示一个属性上的not null约束表明在该属性上不允许为空值。
4.sql--insert,delete
insert into department VALUES('Smith','Biology',66000.23);
delete from tb_order--删除表中的数据
drop table tb_order--将表结构和表数据全部删除
5.sql-select
select dept_name,budget from department;
select DISTINCT building from department;
select dept_name,budget-2 from department;--select支持+,-,*,/,运算。
select dept_name,building,budget from department where dept_name='Smith';
从书写顺序上是select,from,where。然而真正执行的是from,where,select
select id ,name from tb_order o natural join tb_user u where o.id=u.ID;
as:可以放在select字句的后面,也可以出现在from字句的后面,用来给查询出的字段和表起别名。
sql允许在字符串上出现各种函数,例如:串联(“||”)提取子串,计算字符串长度,大小写转换(upper(s)将字符串s转换为大写或用lower(s)将字符串s转换为小写),去掉字符串后面的空格(trim(s)),不同的数据库所提供的函数不同。
%:可以匹配多个字符;_:一个下划线可以匹配一个字符
where字句后面可以使用between...and...来取某个范围的数据,可以使用运算符,字段 is null(表示此字段是空的的数据)
unoin:并运算,用于两个字句之间。如果想保留所有重复的就要使用union all
intersect:交运算,自动去除重复的。用于两个字句之间。如果想保留所有重复的就要使用intersect all
except:差运算,如果想保留所有重复的就要使用except all
6.聚集函数:用于select,having字句后面
avg(求平均值),min(求最小值),max(求最大值),sum(求和),count(统计计数)
select count(DISTINCT phone) from tb_order where (name,phone) in (select name,phone from tb_user where phone='123456');
select name from tb_order where salary > all (select salary from tb_user where name='zz' );
select name from tb_order where salary > all (select salary from tb_user);--如果不加all会报错,因为括号里不只一行
select name ,salary from tb_order GROUP BY name having avg(salary) >=all (select avg(salary) from tb_user GROUP BY name)
in和exists的区别:
执行的结果一样,但是执行流程完全不一样
例如:select student.* from student where student.sno in(select sc.sno from sc)
in:
1.在数据库内部先进性in字句的子查询,
2.然后将查询到的结果和student表做笛卡尔积,
3.最后根据student.sno in sc.sno将结果进行筛选。(其实是在比较student.sno 和sc.sno是否相等,把不相等的删除掉)
例如:select student.* from student where student.sno exists(select sc.sno from sc where sc.sno=student.sno )
exists:
1.先进行主表查询:select student.* from student
2.根据第一步查询出来的每一条数据和exists的语句进行判断,如果相等返回true(保留此行数据),如果不相等返回false(删除此行数据)
使用场景:
in:1.子查询的出的结果集少,主表中查询数据量表较大而且有索引,不对null进行处理
exists:1.如果主表的查询数据量小,子查询的数据量比较大而且又有索引时
in是把内表和外表进行连接,而exists是对内表进行循环查找
not in和not exists的区别
not in:对内外表都进行全表扫描,没有用到索引
not exists:能用到表上的索引,所以无论哪个表大,not exists都比not in查询速度快。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









