




# -*- coding: utf-8 -*-
"""
Created on Wed May 02 16:43:10 2018
@author: TY
"""
# coding:utf8
#引入时间模块
import datetime
import time
#定义一个爬虫函数,用来实现爬虫功能
def pachong():
# 把爬虫程序放在这个类里
print '爬虫已经工作完毕!'
# 定义一个函数,用来判断时间
def main(h, m):
#判断当地时间与设定时间是否吻合
if h == 1 and m == 0:
pachong()
#break
elif h == 17 and m == 5:
pachong()
#break
else:
# 每隔60秒检测一次
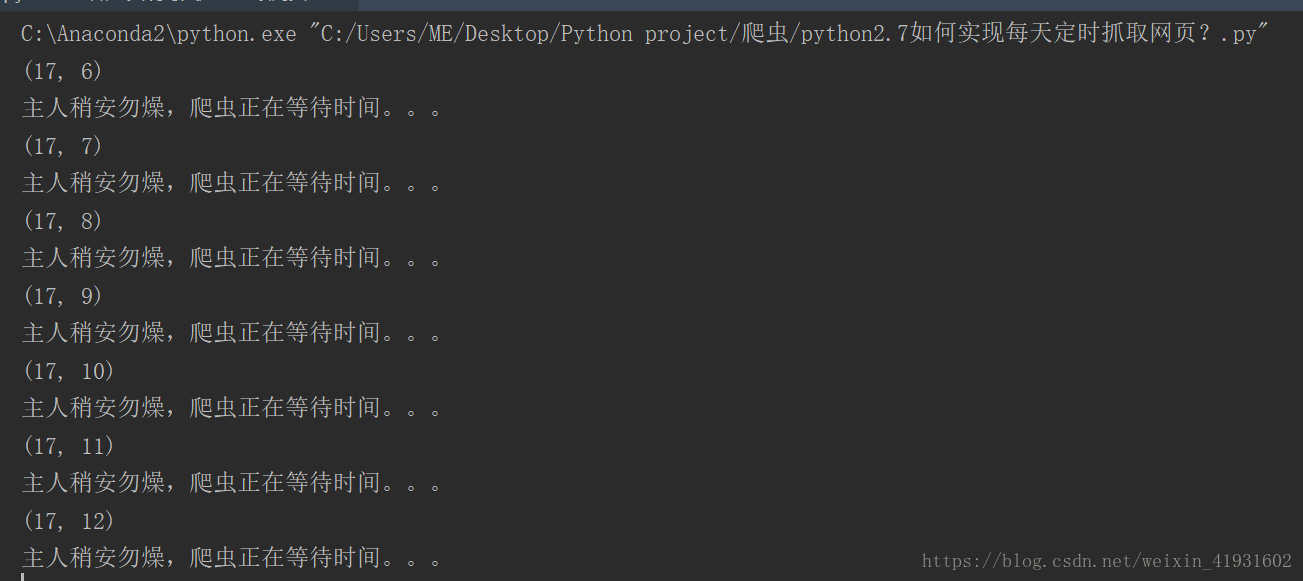
print '主人稍安勿燥,爬虫正在等待时间。。。'
#每隔60秒调用一次nowtime函数,重新做一次判断
time.sleep(60)
nowtime()
print '程序结束!'
#定义一个函数,用于提取当前时间
def nowtime():
#输出当前时间,并且赋值给hour和minute
now = datetime.datetime.now()
print(now.hour, now.minute)
hour = now.hour
minute = now.minute
main(hour,minute)
#调用nowtime函数,判断时间
nowtime()主要通过不断的调用函数做判断,看是否满足要求,如果满足要求才进行抓取数据

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









