




 本文介绍了几种有效的变量筛选方法,包括SCAD、SIS及随机森林等,对比了它们在模拟实验与真实数据上的表现。重点讲解了SCAD方法如何结合L0与L1惩罚的优点,SIS方法在超高维数据下的应用,以及随机森林如何评估变量重要性。
本文介绍了几种有效的变量筛选方法,包括SCAD、SIS及随机森林等,对比了它们在模拟实验与真实数据上的表现。重点讲解了SCAD方法如何结合L0与L1惩罚的优点,SIS方法在超高维数据下的应用,以及随机森林如何评估变量重要性。
由于《An Introduction to Statistical Learning with R》书中的方法书中的方法都是一些比较基础的方法,在做模拟实验以及真实超高维数据时,会出现很多局限性。因此本文后半部分介绍了课本上未提及到的一些方法。这些方法会在后面的模拟实验以及真实数据中进行应用,并且比较书上传统的方法与下述三种方法的真实变量筛选效果。
首先介绍将 L 0 L^0 L0范数与 L 1 L^1 L1范数相结合的SCAD方法。
SCAD(Smoothly Clipped Absolute Deviation)
与岭回归相比,SCAD降低了模型的预测方差,与此同时与Lasso相比,SCAD又缩小了参数估计的偏差,同时它还有很多前面算法所不具备的优秀性质,因而受到了广泛的关注。
SCAD将前面博客提到的
g
λ
(
β
)
=
λ
f
(
β
)
g_\lambda(\beta) = \lambda f(\beta)
gλ(β)=λf(β),变为如下形式:
g
λ
(
β
)
=
{
λ
∣
β
j
∣
,
0
≤
∣
β
j
∣
<
λ
,
−
(
∣
β
j
∣
2
−
2
a
λ
∣
β
j
∣
+
λ
2
)
/
(
2
a
−
2
)
,
λ
≤
∣
β
j
∣
<
a
λ
,
(
a
+
1
)
λ
2
/
2
,
∣
β
j
∣
≥
a
λ
.
g_\lambda(\beta) = \left\{ \begin{array}{ll} \lambda |\beta_j|, & 0 \leq |\beta_j| < \lambda,\\ -(|\beta_j| ^ 2 - 2a \lambda |\beta_j| + \lambda^2)/(2a-2), & \lambda \leq |\beta_j| < a\lambda,\\ (a+1)\lambda^2 / 2, & |\beta_j| \geq a \lambda. \\ \end{array} \right.
gλ(β)=⎩⎨⎧λ∣βj∣,−(∣βj∣2−2aλ∣βj∣+λ2)/(2a−2),(a+1)λ2/2,0≤∣βj∣<λ,λ≤∣βj∣<aλ,∣βj∣≥aλ.
其中,
λ
≥
0
,
a
>
2
\lambda \geq 0, a>2
λ≥0,a>2,Fan和Li\cite{article11} 建议a取3.7。特别地,若设计矩阵
X
X
X正交时,SCAD法参数估计显式表达式如下:
β
^
S
C
A
D
=
{
s
i
g
n
(
β
j
^
)
∣
β
j
^
∣
−
λ
)
,
0
≤
∣
β
j
∣
<
2
λ
,
(
(
a
−
1
)
β
j
^
−
s
i
g
n
(
β
j
^
)
a
λ
)
/
(
a
−
2
)
,
2
λ
≤
∣
β
j
^
∣
<
a
λ
,
β
j
^
,
∣
β
j
^
∣
≥
a
λ
.
\hat{\beta}^{SCAD} = \left\{ \begin{array}{ll} sign(\hat{\beta_j}) |\hat{\beta_j}| - \lambda ), & 0 \leq |\beta_j| < 2 \lambda,\\((a - 1)\hat{\beta_j} - sign(\hat{\beta_j})a\lambda)/(a-2), & 2\lambda \leq |\hat{\beta_j}| < a\lambda,\\ \hat{\beta_j}, & |\hat{\beta_j}| \geq a \lambda. \\\end{array} \right.
β^SCAD=⎩⎨⎧sign(βj^)∣βj^∣−λ),((a−1)βj^−sign(βj^)aλ)/(a−2),βj^,0≤∣βj∣<2λ,2λ≤∣βj^∣<aλ,∣βj^∣≥aλ.
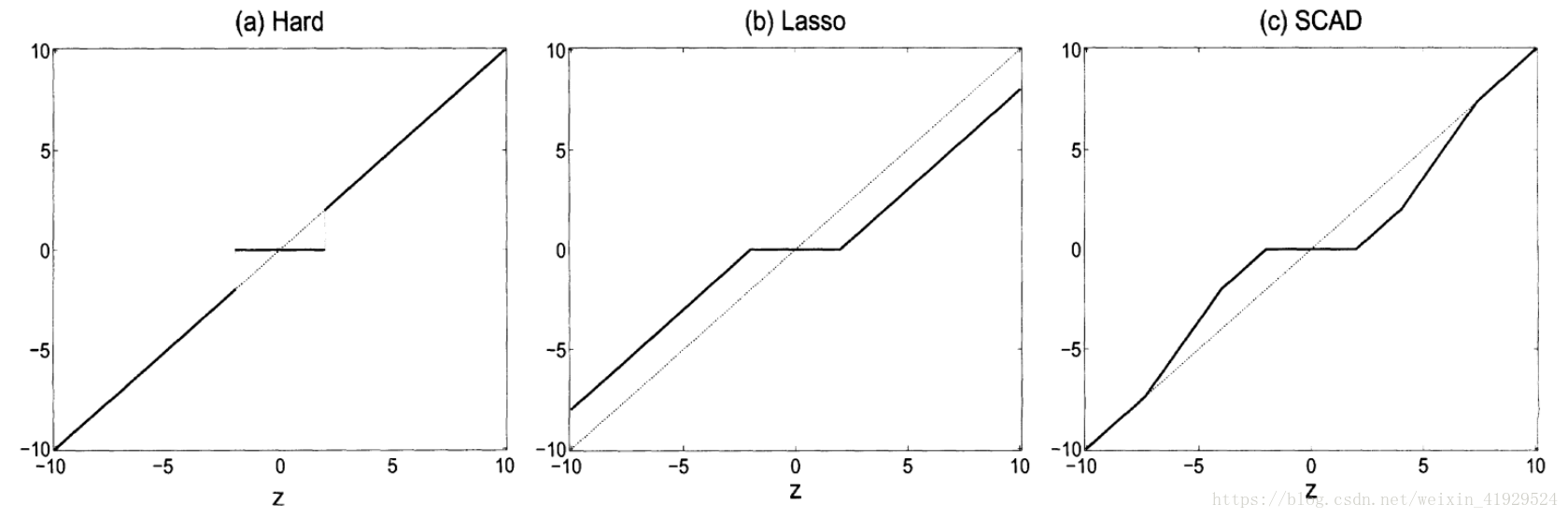
上图说明了 L 0 L^0 L0惩罚, L 1 L^1 L1惩罚,与SCAD三者惩罚之间的差别。可以看出, L 0 L^0 L0方法只会进行变量筛选,不会进行压缩, L 1 L^1 L1(LASSO)既会进行变量筛选,也会对系数继续一定的调整。而SCAD可以从图中很明显的其结合了两种方法,对系数较大的变量不进行惩罚,对系数较少的进行压缩或者删去,因此这种方法既可以筛选变量,也有着Oracle的性质,使其预测效果和真实模型别无二致。
SCAD虽然有相应的迭代算法,但是由于其复杂度高,所以计算速度相对较慢。另外老师上课讲过的将 L 1 L^1 L1与 L 2 L^2 L2范数相结合的Elastic Net方法\cite{article16},也是基于前面的一种衍生方法,本文不再进行阐述。
SIS(Sure Independence Screening)
当今大数据时代,维数远大于样本量的情况已经非常多见。尽管前面所提出的方法,而且也能一定程度上解决髙维数据问题。但当遇到超高维数据,即维数P无穷大时,上述的算法也会出现问题。针对这类超高维问题,Fan和Lv\cite{article12} 提出了SIS的方法。
针对线性回归模型(2),按照SIS的思想,首先
Y
Y
Y为中心化向量,计算
Y
Y
Y与每一个自变量
x
i
x_i
xi的相关系数,记为
ω
=
X
T
Y
,
\omega = X^T Y ,
ω=XTY,
其中
ω
=
(
ω
1
,
⋯
 
,
ω
p
)
T
\omega = (\omega_1,\cdots,\omega_p)^T
ω=(ω1,⋯,ωp)T,若
ω
i
\omega_i
ωi越大,说明
x
i
x_i
xi与
Y
Y
Y相关性越强。所以,可以根据
∣
ω
i
∣
|\omega_i|
∣ωi∣的大小来进行变量选择。对任意的
γ
∈
(
0
,
1
)
\gamma \in (0,1)
γ∈(0,1),对
∣
ω
i
∣
|\omega_i|
∣ωi∣进行从大到小排序,然后取其一个子集
M γ = { 1 ≤ i ≤ p : ∣ ω i ∣ 是前 [ γ n ] 个最大的 } , M_\gamma = \lbrace 1 \leq i \leq p:|\omega_i| \text{是前}[\gamma n] \text{个最大的} \rbrace, Mγ={1≤i≤p:∣ωi∣是前[γn]个最大的},
其中, n n n是样本数, [ γ n ] [\gamma n] [γn]是 γ n \gamma n γn的整数部分,进而保证了 [ γ n ] < n [\gamma n] < n [γn]<n,与之对应的自变量则入选模型。如果觉得选择 [ γ n ] [\gamma n] [γn]不便于确定,可以选择 n − 1 n - 1 n−1或 n / log n n/\log n n/logn。
而关于相关系数,可以选用自己认为合适的。本文后面的模拟选用传统的Pearson相关系数,以及近几年比较火的可用于检验独立的无参数假设的距离相关性(Distance Covariance),下面其计算公式:
距离相关性(Distance Covariance)
a
j
,
k
=
∥
X
j
−
X
k
∥
,
j
,
k
=
1
,
2
,
…
,
n
,
b
j
,
k
=
∥
Y
j
−
Y
k
∥
,
j
,
k
=
1
,
2
,
…
,
n
,
\begin{aligned} a_{j,k}&=\|X_{j}-X_{k}\|,\qquad j,k=1,2,\ldots ,n,\\b_{j,k}&=\|Y_{j}-Y_{k}\|,\qquad j,k=1,2,\ldots ,n, \end{aligned}
aj,kbj,k=∥Xj−Xk∥,j,k=1,2,…,n,=∥Yj−Yk∥,j,k=1,2,…,n,
其中:
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣表示Euclidean范数(欧几里得距离),有:
A
j
,
k
:
=
a
j
,
k
−
a
‾
j
⋅
−
a
‾
⋅
k
+
a
‾
⋅
⋅
,
B
j
,
k
:
=
b
j
,
k
−
b
‾
j
⋅
−
b
‾
⋅
k
+
b
‾
⋅
⋅
,
A_{j,k}:=a_{j,k}-{\overline {a}}_{j\cdot }-{\overline {a}}_{\cdot k}+{\overline {a}}_{\cdot \cdot },\qquad B_{j,k}:=b_{j,k}-{\overline {b}}_{j\cdot }-{\overline {b}}_{\cdot k}+{\overline {b}}_{\cdot \cdot },
Aj,k:=aj,k−aj⋅−a⋅k+a⋅⋅,Bj,k:=bj,k−bj⋅−b⋅k+b⋅⋅,
其中:
a
‾
j
⋅
\overline {a}_{j\cdot}
aj⋅表示由
a
j
,
k
a_{j,k}
aj,k组成的矩阵,第
j
j
j行均值,
a
‾
⋅
k
\overline {a}_{\cdot k}
a⋅k 表示第
k
k
k列均值,以及
a
‾
⋅
⋅
\overline {a}_{\cdot \cdot }
a⋅⋅是
X
X
X样本中所有数取平均。
b
b
b的符号标记同
a
a
a一样,则样本的距离相关性定义为:
dCov
n
2
(
X
,
Y
)
:
=
1
n
2
∑
j
=
1
n
∑
k
=
1
n
A
j
,
k
 
B
j
,
k
.
\text{dCov}_{n}^{2}(X,Y):={\frac {1}{n^{2}}}\sum _{j=1}^{n}\sum _{k=1}^{n}A_{j,k}\,B_{j,k}.
dCovn2(X,Y):=n21j=1∑nk=1∑nAj,kBj,k.
利用随机森林进行变量筛选
其实使用随机森林进行变量筛选是一个比较小众的方法,但其实代表了一类方法。模型本身是用于预测的模型,但在预测过程中,可以对变量重要性进行排序,然后通过这种排序来进行变量筛选。这类方法其实还适用于最近比较火的xgboost,lightgbm等一些非常流行的基于树的机器学习算法,在实际应用中,效果都非常突出。
本文只以较为基础的随机森林中的变量筛选为例:
变量重要性评判用Gini指数为标准,针对一棵树中的每个节点
k
k
k,我们都可以计算一个Gini指数:
G
k
=
2
p
^
k
(
1
−
p
^
k
)
,
G_k = 2 \hat{p}_k (1 - \hat{p}_k),
Gk=2p^k(1−p^k),
其中
p
^
k
\hat{p}_k
p^k表示样本在节点
k
k
k属于任意一类的概率估计值。
一个节点的重要性由节点分裂前后Gini指数的变化量来确定:
I
△
k
=
G
k
−
G
k
1
−
G
k
2
,
I_{\triangle k} = G_k - G_{k1} - G_{k2},
I△k=Gk−Gk1−Gk2,
G
k
1
G_{k1}
Gk1和
G
k
2
G_{k2}
Gk2分别表示
G
k
G_k
Gk产生的子节点。针对森林中的每棵树,都用上述的标准来递归产生,最终随机抽取样本和变量,产生森林,假设森林共产生
T
T
T棵树。
森林中,如果变量
X
i
X_i
Xi在第
t
t
t棵树中出现
M
M
M次,则变量
X
i
X_i
Xi在第
t
t
t棵树的重要性为:
I
i
t
=
∑
j
=
1
M
I
△
j
.
I_{it} = \sum_{j = 1}^M I_{\triangle j}.
Iit=j=1∑MI△j.
则
X
i
X_i
Xi在整个森林中的变量重要性为:
I
(
i
)
=
1
n
∑
t
=
1
T
I
i
t
.
I_{(i)} =\frac{1}{n} \sum_{t = 1}^T I_{it}.
I(i)=n1t=1∑TIit.
最终我们根据变量重要性来选择变量,选择的个数可以用SIS中的方法,选取 n − 1 n - 1 n−1或 n / log n n/\log n n/logn个。
至此,变量筛选的一些方法已进行了简要的概述,包括课本中的以及一些延伸的方法。下面将用模拟实验以及真实数据,来对这些方法进行比较分析。
原始对偶激活集算法(PDAS)
原始对偶激活集算法(Primal Dual Active Set,PDAS)是一个非常新的方法,但做的事情是最优子集选择的事情。其主要思想是引入激活集,对所有的 β \beta β进行批量迭代更新。这个方法的优势在于,可以处理超高维数据(上万维),而最优子集选择一旦超过了50维,基本就完全没办法进行运算。后面我们也将采用PDAS来进行模拟。
其算法如下:
- 给定某固定的 T T T,初始的 β 0 \beta^0 β0, d 0 = − g ( β 0 ) h ( β 0 ) d^0=-\dfrac{g(\beta_0)}{h(\beta_0)} d0=−h(β0)g(β0),根据 β 0 \beta^0 β0和 d 0 d^0 d0得出 A 0 \mathcal{A}^0 A0、 I 0 \mathcal{I}^0 I0。令 k = 0 k=0 k=0
- For
k
=
0
,
1
,
2
,
…
,
K
m
a
x
k=0,1,2,\ldots,K_{max}
k=0,1,2,…,Kmax, do
(2.a) 更新 ( β k + 1 , d k + 1 ) (\beta^{k+1},d^{k+1}) (βk+1,dk+1):
{ β I k k + 1 = 0 d A k k + 1 = 0 β A k k + 1 = a r g   m i n   l ( β A k ∣ Y , X A k ) d I k k + 1 = − g ( β I k k ) h ( β I k k ) \left\{ \begin{array}{ll} \beta_{I^k}^{k+1}=0\\ d_{A^k}^{k+1}=0\\ \beta_{A^k}^{k+1}=arg\,min\,l(\beta_{A^k}|\textit{Y},\textit{X}_{A^k})\\ d_{I^k}^{k+1}=-\dfrac{g(\beta_{I^{k}}^{k})}{h(\beta_{I^{k}}^{k})} \end{array} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧βIkk+1=0dAkk+1=0βAkk+1=argminl(βAk∣Y,XAk)dIkk+1=−h(βIkk)g(βIkk)
(2.b) 通过以下方式计算新的激活集 A k + 1 \mathcal{A}^{k+1} Ak+1和非激活集 I k + 1 \mathcal{I}^{k+1} Ik+1:
A k + 1 = { j : − h ( β j k + 1 ) ∣ β j k + 1 + d j k + 1 ∣ ⩾ − h ( β j k + 1 ) ∥ β j k + 1 + d j k + 1 ∥ T , ∞ } , A^{k+1}=\lbrace{j}:\sqrt{-h(\beta_{j}^{k+1})}\vert\beta_{j}^{k+1}+d_{j}^{k+1}\vert\geqslant\sqrt{-h(\beta_{j}^{k+1})}\Vert\beta_{j}^{k+1}+d_{j}^{k+1}\Vert_{T,\infty}\rbrace, Ak+1={j:−h(βjk+1)∣βjk+1+djk+1∣⩾−h(βjk+1)∥βjk+1+djk+1∥T,∞},
I k + 1 = ( A k + 1 ) c I^{k+1}=(A^{k+1})^c Ik+1=(Ak+1)c
(2.c) 如果 A k + 1 = A k \mathcal{A}^{k+1}=\mathcal{A}^{k} Ak+1=Ak,则停止迭代;否则令 k = k + 1 k=k+1 k=k+1,继续(2.a)和(2.b)步。
(2.d) 输出 β = β k + 1 \beta=\beta^{k+1} β=βk+1。
后面我们将对前面提及的一些算法进行模拟,以及真实案例操作。传送门:一些变量筛选方法——4、模拟实验

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









