




GAN, 作为一种非常厉害的生成模型, 在近年来得到了广泛的应用. Soumith, PyTorch之父, 毕业于纽约大学的Facebook的VP, 在2015年发明了DCGAN: Deep Convolutional GAN. 它显式的使用卷积和转置卷积在判别器和生成器中使用. 他对GAN的理解相对深入, 特地总结了关于训练GAN的一些技巧和方式, 因为不同于一般任务, 像设置优化器, 计算loss以及初始化模型权重等tips, 这些对于GAN网络能否收敛可以说至关重要. 现在特此翻译这篇文章, 以飨读者.
How to Train a GAN? Tips and tricks to make GANs work
随着人们对生成对抗网络(GANs)的研究进一步深入, 继续提高GAN的基本稳定性是非常重要的一环。我们使用了一系列技巧来训练它们,使它们保持稳定。
作者:
Soumith Chintala, Emily Denton, Martin Arjovsky, Michael Mathieu.
废话不多说, 直接上干货:
1. Normalize the inputs( 规则化输入数据)
- 将图像的数值范围限制在 [-1, 1].
- 将
Tanh层作为生成器最后输出层.
2. A modified loss function(修改Loss函数)
在GAN的论文中, 生成器G的目标是使得目标函数
l
o
g
(
1
−
D
)
l
o
g
(
1
−
D
)
l
o
g
(
1
−
D
)
log(1−D)log (1-D)log(1−D)
log(1−D)log(1−D)log(1−D)最小, 但是实际写代码中, 目标是让
l
o
g
(
D
)
l
o
g
(
D
)
l
o
g
(
D
)
log(D)log(D)log(D)
log(D)log(D)log(D)最大. 这是因为前面的式子有梯度消失问题. Goodfellow et. al (2014)
此外, 训练生成器的时候, 还可以将数据对应的**标签(label)**进行翻转: 即real = fake, fake = real来进行训练. 其目的是增强生成器的泛化能力(通常作为在生成器能力很强的时候fine-tune的策略.)
3. Use a spherical Z(使用球面分布)
通常的GAN中,包括2019年最新的styleGAN,它们的latent vector z都是通过正态分布进行采样得到的(根据情况,可能是非标准正态分布)。
本文推荐对高斯分布(gaussian distribution)进行采样而得到 z。
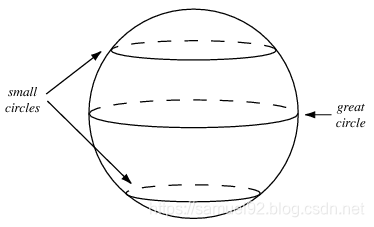
此外, Soumith还指出需要注意以下2点:
- When doing interpolations, do the interpolation via a great circle, rather than a straight line from point A to point B.
- Tom White’s Sampling Generative Networks ref code https://github.com/dribnet/plat has more details.
4. Batch Norm(批归一化)
- 如果要用BN的话,只能在all-fake或all-real的mini-batch中使用。
- 现在流行使用PixelNorm和InstanceNorm
[3](关于其PyTorch1.0.1的实现,在我复现StyleGAN的代码中有,欢迎参考~)
5. Avoid Sparse Gradients: ReLU, MaxPool(避免稀疏梯度)
如果你使用了ReLU或MaxPooling,那么这样的GAN通常稳定性较差(由于梯度的稀疏性)。
LeakyReLU = good (in both G and D)也是目前几乎所有GAN的标配。- 下采样时,建议使用Average Pooling或者Conv2d + stride的方式。
- 上采样通常使用PixelShuffle
[4]和ConvTranspose2d + stride。
6. Use Soft and Noisy Labels(使用光滑和带噪声的标签)
-
对标签进行平滑, i.e. if you have two target labels: Real=1 and Fake=0, then for each incoming sample, if it is real, then replace the label with a random number between 0.7 and 1.2, and if it is a fake sample, replace it with 0.0 and 0.3 (for example).
Salimans et. al. 2016 -
在训练鉴别器的时候,偶尔翻转label,即
fake->real,real->fake。
7. DCGAN / Hybrid Models(DCGAN和混合模型)
这里,Soumith开始推销自己的工作了哈哈,他认为DCGAN在任何场景都能很好的工作。
当然,如果你愿意的话,也可以使用Hybrid的模型,比如 KL + GAN 或 VAE + GAN。
8. Use stability tricks from RL(使用增强学习中提升稳定性的策略)
- 经验重播(Experience Replay)
Keep a replay buffer of past generations and occassionally show them
Keep checkpoints from the past of G and D and occassionaly swap them out for a few iterations
- 所有稳定性技巧都适用于深度确定性策略梯度。
- 查阅 Pfau & Vinyals (2016)发表的资料。
9. Use the ADAM Optimizer(使用ADAM优化器)
Soumith认为Adam很吊,一个就够了。大多数情况,生成器和判别器都用ADAM就可以,或者,你也可以使用SGD来优化判别器。
10. Track failures early(及早发现失败)
-
① 当判别器的loss一直接近0或者为0的时候,那就说明这次训练是有问题的,应该及时停掉,检查模型和超参数的设置。
-
② 检查梯度的范数,如果超过100,就会出错。
-
③ 当模型正常训练时,判别器D的loss方差较小,并且随着时间的推移而下降,或者方差较大且呈峰值。
-
④ 如果生成器G的loss稳步下降,那可能意味着在用垃圾来迷糊判别器D(马丁说)。
11. Dont balance loss via statistics (unless you have a good reason to)(不要通过统计数字来平衡损失(除非你有充分的理由))
不要通过设计通过判断loss是否达到我们预设的阈值来进行触发训练。Soumith他们已经试了很多了,不好使。如果,你一定要这么做,那么要有自己的方法论,而不能凭直觉。
while lossD > A:
train D
while lossG > B:
train G
12. If you have labels, use them (如果有标签,那么使用它)
如果你有标签可用,训练鉴别器D分类样本: 辅助GANs。
13. Add noise to inputs, decay over time (对输入加入噪声)
这个策略在18,19年Nvidia的大神kerras的论文中都体现的淋漓尽致:
- 对喂入判别器的输入加入人为噪声。 (Arjovsky et. al., Huszar, 2016)
http://www.inference.vc/instance-noise-a-trick-for-stabilising-gan-training/
https://openreview.net/forum?id=Hk4_qw5xe - 对生成器G的每层都加入高斯噪声。 (Zhao et. al. EBGAN)
Improved GANs: OpenAI code also has it (commented out)
14. [notsure] Train discriminator more (sometimes) (使用多个判别器)
- 对数据噪声比较大的情况适用(ECCV2018 MMAN做Human parsing的一篇文章)。
- 当难以确定生成器和判别器迭代策略的时候。
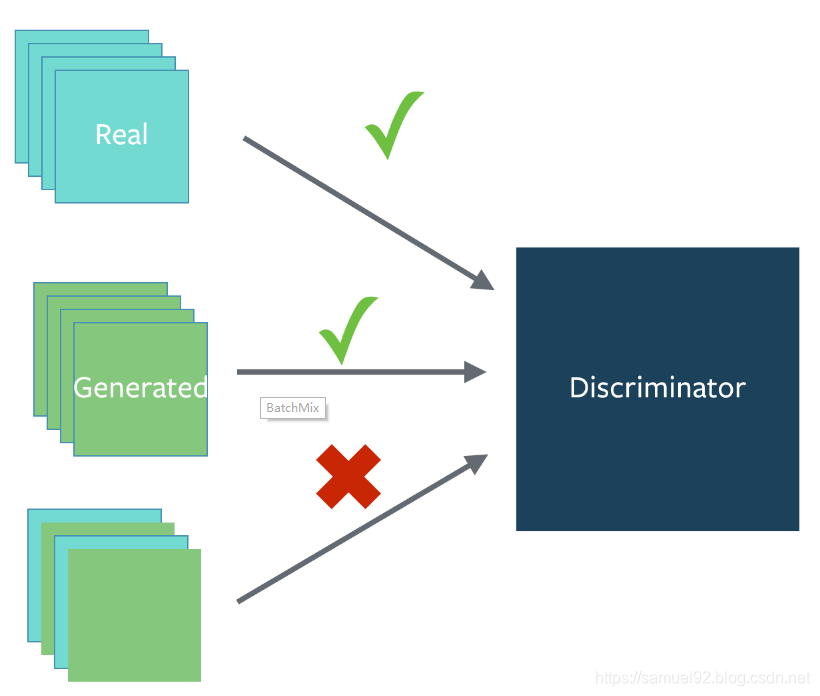
15. [notsure] Batch Discrimination (批量判别?)
- 将结果混合?
16: Discrete variables in Conditional GANs(CGAN中的离散变量)
- 使用
Embedding层。 - 为图像增加额外通道。
- 保持较低的嵌入维数,通过上采样以匹配图像通道大小。
17. Use Dropouts in G in both train and test phase (在生成器中使用Dropout)
- 以Dropout的形式模拟提供噪声 (50%)。
- 无论是训练还是推理阶段,都在生成器G中的某几层加入Dropout机制
[5]。
参考资料
[1] Soumith: How to Train a GAN? Tips and tricks to make GANs work
[2] Tom White: Sampling Generative Networks
[3] 基于PyTorch1.x复现的styleGAN
[4] PixelShuffle
[5] https://arxiv.org/pdf/1611.07004v1.pdf
[6] https://blog.youkuaiyun.com/g11d111/article/details/89100833

















 4983
4983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









