









 本文介绍并行化Kmeans算法步骤,在特定实验条件下对相关函数详细分解并优化。通过减少冲突、使用共享内存等方式提升效率,如KmeansCUDA_distOfObjAndCluster函数使用共享内存加速7倍多。最终GPU运行较Matlab加速345倍,虽仍有优化空间,但加速效果显著。
本文介绍并行化Kmeans算法步骤,在特定实验条件下对相关函数详细分解并优化。通过减少冲突、使用共享内存等方式提升效率,如KmeansCUDA_distOfObjAndCluster函数使用共享内存加速7倍多。最终GPU运行较Matlab加速345倍,虽仍有优化空间,但加速效果显著。
1. Kmeans 步骤
常规的 Kmeans 步骤:
1. 初始化聚类中心
2. 迭代
1. 计算每个样本与聚类中心的欧式距离
2. 根据样本与聚类中心的欧式距离更新每个样本的类标签
3. 根据类标签更新聚类中心
本文中并行化的 Kmeans 的步骤:
初始化每个样本的类标签
迭代
统计每一类的样本和
统计每一类的样本个数
计算每一类的聚类中心:样本和 / 样本个数
计算每个样本与每个聚类中心的欧式距离
根据每个样本与聚类中心的欧式距离更新样本的类标签
如下所示:
/* 样本聚类索引的初始化*/
KmeansCUDA_Init_ObjClusterIdx<<<>>>();
for (int i = 0; i < maxKmeansIter; i++)
{
/* 统计每一类的样本和 */
KmeansCUDA_Update_Cluster<<<>>>();
/* 统计每一类的样本个数 */
KmeansCUDA_Count_objNumInCluster<<<>>>();
/* 聚类中心平均 = 样本和 / 样本个数 */
KmeansCUDA_Scale_Cluster<<<>>>();
/* 计算每个样本与每个聚类中心的欧式距离 */
KmeansCUDA_distOfObjAndCluster<<<>>>();
/* 根据每个样本与聚类中心的欧式距离更新样本的类标签 */
KmeansCUDA_Update_ObjClusterIdx<<<>>>();
}
2. 完全分解
不同的数据,可能会有不同的优化方式,所以本文首先给出本文的实验条件:
数据
将一个 256 * 256 * 3 的三维图像进行块划分,块的大小为 5 * 5 * 3,取块的间隔为 1 个像素,所以总的块数(样本数)为(256 - 5 + 1)*(256 - 5 + 1)= 63504 个,样本的维度为 5 * 5 * 3 = 75。聚类的个数为 80。
环境
GPU:NVIDIA GTX980,2048 个核
CUDA版本:6.5
第一部分对应的几个函数的详细分解方式如下所示:
KmeansCUDA_Init_ObjClusterIdx函数
由于只执行一次,且计算量非常小,故不作为优化的重点。
线程块维度:256
线程格维度:(63504 + 256 - 1) / 256 = 249
每个线程负责初始化一个样本的类标签。
KmeansCUDA_Update_Cluster函数
如果每个类的样本都放在连续空间,那么此函数可以使用类似于规约求和的方式就可以实现,且效率很高。但是此处每个类是分散的,所以换一种方式:
线程块维度:(16,16)
线程格维度:((75 + 16 - 1) / 16, (63504 + 16 - 1) / 16) = (5, 3969)
每个线程负责一个样本中的一个数据,此处要使用原子操作,因为多个线程可能同时写一个聚类中心的数据。当然,也可以按下列的方式划分线程块和线程格:
线程块维度:256
线程格维度:(63504 + 256 - 1) / 256 = 249
每个线程负责更新一个样本,但是此时的效率不高:
第一种方式运行 14 次的时间为: 6.686ms
第二种方式运行 14 次的时间为:14.142ms
KmeansCUDA_Count_objNumInCluster函数
与KmeansCUDA_Init_ObjClusterIdx函数类似,计算量很少,每个负责处理一个样本的计数,只有一个原子操作的加法,所以依旧采用一维的线程方式:
线程块维度:256
线程格维度:(63504 + 256 - 1) / 256 = 249
由于会有 63504 个线程写 80(类数)个位置,所以会存在许多冲突,所以此处对其进行优化,开辟线程数变为:
线程块维度:1024
线程格维度:(63504 + 1024 - 1) / 1024 = 63
此时,在每个块内申请 80 个整数大小的共享内存,先在块内进行统计,最后再写到全局内存,而不是像第一种方式那样,直接写全局内存,这样就避免了很多的冲突,两种方式的时间对比为:
第一种方式运行 14 次的时间为:733.3us
第二种方式运行 14 次的时间为:61.44us
从上可以看出,通过减少冲突,使用共享内存,可以加速 12 倍左右。
KmeansCUDA_Scale_Cluster函数
此函数用于对每个样本求和之后的取平均操作,计算量极其少,不是优化的重点,开辟二维线程块
线程块维度:(16,16)
线程格维度:((75 + 16 - 1) / 16, (80 + 16 - 1) / 16) = (5, 5)
每个线程负责更新聚类中心中的一个数。
KmeansCUDA_distOfObjAndCluster函数
此函数是优化的重点,因为 Kmeans 的绝大部分计算量都集中在求每个样本与每个聚类中心的欧式距离,在此也开辟二维线程块:
线程块维度:(16,16)
线程格维度:((80 + 16 - 1) / 16, (63504 + 16 - 1) / 16) = (5, 3969)
每个线程负责计算一个样本与一个聚类中心的欧式距离。考虑到此函数的计算过程中聚类中心是不变的,可以考虑使用常量内存,以此加快对聚类中心的访问速度(此方案称为方案二)。另外,考虑到此函数的计算方式与矩阵乘法类似,可以考虑使用共享内存,每个线程块的任务是计算 16 个样本与 16 个聚类中心的距离(此方案称为方案三)将16 个样本与 16 个聚类中心的数据存到共享内存中(每一个线程块的共享内存为:32 * 75 * 4 / 1024 = 9.375kb 小于 每块最大可以使用量 48kb,每个 SM 最多调度 2048 个线程,也就是最多 8 个线程块,所以每个 SM 使用的共享内存为 75kb,小于 GTX980 每块 SM 的 96kb,综上,共享内存是够用的)。三种方案的执行14次的时间为:
方案一:183.562ms
方案二:243.298ms
方案三:25.213ms
从上可以看出,使用共享内存的计算时间远远小于未使用共享内存的计算时间,方案三相较于方案一加速 7 倍多,考虑到是计算量最大的模块加速 7 倍多,所以加速效果相当理想。但是方案二使用常量内存的计算时间反而比不使用常量内存的时间还长,这是因为聚类中心的数据大小为:80 *75*4/1024 = 23.4375 kb,虽然 GTX980 的最大可用常量内存为 64 kb,但是在每个 SM 共共常量内存使用的高速缓存只有 10 kb(常量内存是借助于高速缓存来实现快速访问,对于计算能力小于 5.0 的设备,此值为 8 kb),也就是说不够缓存所有的聚类中心,导致反复缓存,缓存命中的效率极低。
__shared__ float objShared[BLOCKSIZE][OBJLENGTH]; // 存样本
__shared__ float cluShared[BLOCKSIZE][OBJLENGTH]; // 存聚类中心
for (int xidx = threadIdx.x; xidx < OBJLENGTH; xidx += BLOCKSIZE)
{
int index = myParameter.objLength * threadIdx.y + xidx;
objShared[threadIdx.y][xidx] = objects[index];
cluShared[threadIdx.y][xidx] = clusters[index];
}
上述代码中将数据从全局内存拷贝到共享内存中的方式如下图所示,每次读同一种颜色的块,经多次循环之后全部读入共享内存中。
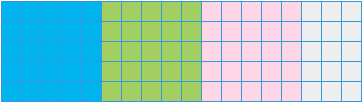
上述访问方式会人为的将连续的内存区域分成不连续的访问,将无法实现合并访问,进而无法隐藏内存访问的延迟,导致效率不高,因此对其进行优化。
__shared__ float objShared[OBJLENGTH * BLOCKSIZE]; // 存样本
__shared__ float cluShared[OBJLENGTH * BLOCKSIZE]; // 存聚类中心
for (int index = BLOCKSIZE * threadIdx.y + threadIdx.x; index < OBJLENGTH * BLOCKSIZE; index = BLOCKSIZE * BLOCKSIZE + index)
{
objShared[index] = objects[index];
cluShared[index] = clusters[index];
}
读取方式如下图所示:
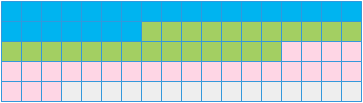
优化前后的时间对比为:
优化前:25.213ms
优化后:24.173ms
虽然效率没有明显提升,但是还是很可观的。
KmeansCUDA_Update_ObjClusterIdx函数
用于寻找每个样本与所有聚类中心中距离最小的,将当前样本划归到该类。可以开辟一维线程:
线程块维度:256
线程格维度:(63504 + 256 - 1) / 256 = 249
每个线程用于查找当前样本对应的最短距离(共 80 个)。因为求最小与规约类似,而上述方式的每个样本却是完全串行的方式,所以对其进行优化,开辟二维线程:
线程块维度:(16,16)
线程格维度:((1, (63504 + 16 - 1) / 16) = (1, 3969)
每个线程块用于计算 16 个样本的最小距离,也就是说用 16 个线程来计算原来 1 个线程的工作(查找 80 个数的最小值)。
最后,把剩余两个元素的较小值作为最短距离,优化前后的时间对比为:
优化前:12.725ms
优化后:1.887ms
优化后加速 7 倍左右,效果相当可观。
3. 结果
如下图所示,是优化的最终版本的 visual profile 结果,可见,依旧是计算样本与聚类中心的距离最耗时,也必然还有优化的空间。
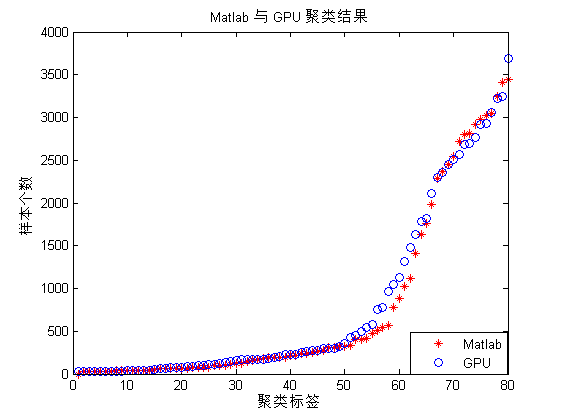
另外,本文对 Matlab 和 GPU 上的运行时间进行对比,以衡量加速效果(采用相同数据,相同的迭代次数):
GPU 运行时间为:32.1842 ms
Matlab 运行时间为:11102.919 ms
最终的加速比为:345 倍
下图所示的为聚类结果,按每一类中的样本数从大到小排列,由于初始聚类中心的不同,有部份计算误差。
代码:
kernel.cu
#include "KmeansCUDA.h" #include <cuda_runtime.h> #include <device_launch_parameters.h> #include "ClassParameter.h" #include "ReadSaveImage.h" #include <iostream> using std::cout; using std::endl; int main() { sParameter myParameter{63504, 75, 80, 40, 150, 14}; float *objData = (float*)malloc(myParameter.objNum * myParameter.objLength * sizeof(float)); float *centerData = (float*)malloc(myParameter.clusterNum * myParameter.objLength * sizeof(float)); int *objClassIdx = (int*)malloc(myParameter.objNum * sizeof(int)); ReadData(objData, myParameter); KmeansCUDA(objData, objClassIdx, centerData, myParameter); SaveData(objClassIdx, myParameter); cudaDeviceReset(); return 0; }
ReadSaveImage.h
#ifndef READSAVEIMAGE_H #define READSAVEIMAGE_H #include "ClassParameter.h" void ReadData(float *fileData, sParameter myParameter); void SaveData(int *fileData, sParameter myParameter); #endif // !READSAVEIMAGE_H
ReadSaveImage.cpp
#include "ReadSaveImage.h" #include <iostream> #include <fstream> /** * 功能:从txt文件中读取数据 * 输出:fileData 输出数据的头指针 * 输入:fileName 读取的文本文件的文件名 * 输入:dataNum 读取的数据个数 */ void ReadFile(float *fileData, std::string fileName, int dataNum) { std::fstream file; file.open(fileName, std::ios::in); if (!file.is_open()) { std::cout << "不能打开文件" << std::endl; return; } // 读入数据到内存中 for (int i = 0; i < dataNum; i++) file >> fileData[i]; file.close(); } void ReadData(float *fileData, sParameter myParameter) { std::string str = "D:\\Document\\vidpic\\CUDA\\Kmeans\\objData.txt"; //文件路径 ReadFile(fileData, str, myParameter.objNum*myParameter.objLength); } /** * 功能:把数据保存到文本文件中 * 输入:fileData 输入数据的头指针 * 输入:fileName 保存的文本文件的文件名 * 输入:dataNum 保存的数据个数 */ void SaveFile(int *fileData, std::string fileName, int dataNum) { std::fstream file; file.open(fileName, std::ios::out); if (!file.is_open()) { std::cout << "不能打开文件" << std::endl; return; } // 读入数据到内存中 for (int i = 0; i < dataNum; i++) file << fileData[i] << std::endl; file.close(); } void SaveData(int *fileData, sParameter myParameter) { std::string str = "D:\\Document\\vidpic\\CUDA\\Kmeans\\objClusterIdxPre.txt"; //文件路径 SaveFile(fileData, str, myParameter.objNum); }
KmeansCUDA.h
#ifndef KMEANSCUDA_H #define KMEANSCUDA_H #include "ClassParameter.h" /** * 功能:并行 Kmeans 聚类 * 输入:objData 样本数据 * 输出:objClusterIdx 每个样本的类别索引 * 输出:clusterData 聚类中心 * 输入:myPatameter 输入参数 */ void KmeansCUDA(float *objData, int *objClusterIdx, float*clusterData, sParameter myParameter); #endif // KMEANSCUDA_H
KmeansCUDA.cu
#include "KmeansCUDA.h" #include <cuda_runtime.h> #include <device_launch_parameters.h> #include <curand_kernel.h> #include <iostream> #include <stdlib.h> #define BLOCKSIZE_16 16 #define BLOCKSIZE_32 32 #define OBJLENGTH 75 /** * 功能:初始化每个样本的类索引 * 输出:objClusterIdx_Dev 每个样本的类别索引 * 输入:objNum 样本个数 * 输入:maxIdx 索引的最大值 */ __global__ void KmeansCUDA_Init_ObjClusterIdx(int *objClusterIdx_Dev, int objNum, int maxIdx) { int index = blockDim.x * blockIdx.x + threadIdx.x; curandState s; curand_init(index, 0, 0, &s); if (index < objNum) objClusterIdx_Dev[index] = (int(curand_uniform(&s) * maxIdx)); } /** * 功能:更新 Kmeans 的聚类中心 * 输入:objData_Dev 样本数据 * 输入:objClusterIdx_Dev 每个样本的类别索引 * 输出:clusterData_Dev 聚类中心 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Update_Cluster(float *objData_Dev, int *objClusterIdx_Dev, float *clusterData_Dev, sParameter myParameter) { int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标 int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标 if (x_id < myParameter.objLength && y_id < myParameter.objNum) { int index = y_id * myParameter.objLength + x_id; int clusterIdx = objClusterIdx_Dev[y_id]; atomicAdd(&clusterData_Dev[clusterIdx * myParameter.objLength + x_id], objData_Dev[index]); } } /** *功能:更新 Kmeans 的聚类中心 * 输入:objClusterIdx_Dev 每个样本的类别索引 * 输出:objNumInCluster 每个聚类中的样本数 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Count_objNumInCluster(int *objClusterIdx_Dev, int *objNumInCluster, sParameter myParameter) { int index = blockDim.x * blockIdx.x + threadIdx.x; if (index < myParameter.objNum) { int clusterIdx = objClusterIdx_Dev[index]; atomicAdd((int*)&objNumInCluster[clusterIdx], 1); // 计数 } } /** *功能:更新 Kmeans 的聚类中心 * 输入:objClusterIdx_Dev 每个样本的类别索引 * 输出:objNumInCluster 每个聚类中的样本数 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Count_objNumInCluster1(int *objClusterIdx_Dev, int *objNumInCluster, sParameter myParameter) { int index = blockDim.x * blockIdx.x + threadIdx.x; __shared__ int sData[80]; if (threadIdx.x < myParameter.clusterNum) sData[threadIdx.x] = 0; __syncthreads(); if (index < myParameter.objNum) { int clusterIdx = objClusterIdx_Dev[index]; atomicAdd((int*)&sData[clusterIdx], 1); } __syncthreads(); if (threadIdx.x < myParameter.clusterNum) atomicAdd((int*)&objNumInCluster[threadIdx.x], sData[threadIdx.x]); // 计数 } /** *功能:平均 Kmeans 的聚类中心 * 输出:clusterData_Dev 聚类中心 * 输出:objNumInCluster 每个聚类中的样本数 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Scale_Cluster(float *clusterData_Dev, int *objNumInCluster, sParameter myParameter) { int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标 int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标 if (x_id < myParameter.objLength && y_id < myParameter.clusterNum) { int index = y_id * myParameter.objLength + x_id; clusterData_Dev[index] /= float(objNumInCluster[y_id]); } } /** * 功能:计算两个向量的欧拉距离 * 输入:objects 样本数据 * 输出:clusters 聚类中心数据 * 输入:objLength 样本长度 */ __device__ inline static float EuclidDistance(float *objects, float *clusters, int objLength) { float dist = 0.0f; for (int i = 0; i < objLength; i++) { float onePoint = objects[i] - clusters[i]; dist = onePoint * onePoint + dist; } return(dist); } /** * 功能:计算所有样本与聚类中心的欧式距离 * 输入:objData_Dev 样本数据 * 输入:objClusterIdx_Dev 每个样本的类别索引 * 输入:clusterData_Dev 聚类中心 * 输出:distOfObjAndCluster_Dev 每个样本与聚类中心的欧式距离 * 输入:objNumInCluster_Dev 每个聚类中的样本数 * 输入:iter 迭代次数 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_distOfObjAndCluster(float *objData_Dev, int *objClusterIdx_Dev, float *clusterData_Dev, float *distOfObjAndCluster_Dev, int *objNumInCluster_Dev, int iter, sParameter myParameter) { int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标 int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标 const int oneBlockData = OBJLENGTH * BLOCKSIZE_16; __shared__ float objShared[oneBlockData]; // 存样本 __shared__ float cluShared[oneBlockData]; // 存聚类中心 /* 数据读入共享内存 */ if (y_id < myParameter.objNum) { float *objects = &objData_Dev[myParameter.objLength * blockDim.y * blockIdx.y]; // 当前块需要样本对应的首地址 float *clusters = &clusterData_Dev[myParameter.objLength * blockDim.x * blockIdx.x]; // 当前块需要聚类中心对应的首地址 for (int index = BLOCKSIZE_16 * threadIdx.y + threadIdx.x; index < oneBlockData; index = BLOCKSIZE_16 * BLOCKSIZE_16 + index) { objShared[index] = objects[index]; cluShared[index] = clusters[index]; } __syncthreads(); } if (x_id < myParameter.clusterNum && y_id < myParameter.objNum) { //if (objNumInCluster_Dev[x_id] < myParameter.minObjInClusterNum && iter >= myParameter.maxKmeansIter - 2) // distOfObjAndCluster_Dev[y_id * myParameter.clusterNum + x_id] = 3e30; //else distOfObjAndCluster_Dev[y_id * myParameter.clusterNum + x_id] = EuclidDistance(&objShared[myParameter.objLength * threadIdx.y], &cluShared[myParameter.objLength * threadIdx.x], myParameter.objLength); } } /** * 功能:计算所有样本与聚类中心的欧式距离 * 输入:objData_Dev 样本数据 * 输入:objClusterIdx_Dev 每个样本的类别索引 * 输入:clusterData_Dev 聚类中心 * 输出:distOfObjAndCluster_Dev 每个样本与聚类中心的欧式距离 * 输入:objNumInCluster_Dev 每个聚类中的样本数 * 输入:iter 迭代次数 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_distOfObjAndCluster1(float *objData_Dev, int *objClusterIdx_Dev, float *clusterData_Dev, float *distOfObjAndCluster_Dev, int *objNumInCluster_Dev, int iter, sParameter myParameter) { int x_id = blockDim.x * blockIdx.x + threadIdx.x; // 列坐标 int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标 __shared__ float objShared[BLOCKSIZE_16][OBJLENGTH]; // 存样本 __shared__ float cluShared[BLOCKSIZE_16][OBJLENGTH]; // 存聚类中心 float *objects = &objData_Dev[myParameter.objLength * blockDim.y * blockIdx.y]; // 当前块需要样本对应的首地址 float *clusters = &clusterData_Dev[myParameter.objLength * blockDim.x * blockIdx.x]; // 当前块需要聚类中心对应的首地址 /* 数据读入共享内存 */ if (y_id < myParameter.objNum) { for (int xidx = threadIdx.x; xidx < OBJLENGTH; xidx += BLOCKSIZE_16) { int index = myParameter.objLength * threadIdx.y + xidx; objShared[threadIdx.y][xidx] = objects[index]; cluShared[threadIdx.y][xidx] = clusters[index]; } __syncthreads(); } if (x_id < myParameter.clusterNum && y_id < myParameter.objNum) { if (objNumInCluster_Dev[x_id] < myParameter.minObjInClusterNum && iter >= myParameter.maxKmeansIter - 2) distOfObjAndCluster_Dev[y_id * myParameter.clusterNum + x_id] = 3e30; else distOfObjAndCluster_Dev[y_id * myParameter.clusterNum + x_id] = EuclidDistance(objShared[threadIdx.y], cluShared[threadIdx.x], myParameter.objLength); } } /** * 功能:计算所有样本与聚类中心的欧式距离 * 输出:objClusterIdx_Dev 每个样本的类别索引 * 输入:distOfObjAndCluster_Dev 每个样本与聚类中心的欧式距离 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Update_ObjClusterIdx1(int *objClusterIdx_Dev, float *distOfObjAndCluster_Dev, sParameter myParameter) { int index = blockDim.x * blockIdx.x + threadIdx.x; if (index < myParameter.objNum) { float *objIndex = &distOfObjAndCluster_Dev[index * myParameter.clusterNum]; int idx = 0; float dist = objIndex[0]; for (int i = 1; i < myParameter.clusterNum; i++) { if (dist > objIndex[i]) { dist = objIndex[i]; idx = i; } } objClusterIdx_Dev[index] = idx; } } /** * 功能:计算所有样本与聚类中心的欧式距离(优化后的) * 输出:objClusterIdx_Dev 每个样本的类别索引 * 输入:distOfObjAndCluster_Dev 每个样本与聚类中心的欧式距离 * 输入:myPatameter 输入参数 */ __global__ void KmeansCUDA_Update_ObjClusterIdx(int *objClusterIdx_Dev, float *distOfObjAndCluster_Dev, sParameter myParameter) { int y_id = blockDim.y * blockIdx.y + threadIdx.y; // 行坐标 __shared__ float sData[BLOCKSIZE_16][BLOCKSIZE_16]; // 样本与聚类中心距离 __shared__ int sIndx[BLOCKSIZE_16][BLOCKSIZE_16]; // 距离对应的类标号 sData[threadIdx.y][threadIdx.x] = 2e30; sIndx[threadIdx.y][threadIdx.x] = 0; __syncthreads(); if (y_id < myParameter.objNum) { float *objIndex = &distOfObjAndCluster_Dev[y_id * myParameter.clusterNum]; sData[threadIdx.y][threadIdx.x] = objIndex[threadIdx.x]; sIndx[threadIdx.y][threadIdx.x] = threadIdx.x; __syncthreads(); /* 每 BLOCKSIZE_16 个进行比较 */ for (int index = threadIdx.x + BLOCKSIZE_16; index < myParameter.clusterNum; index += BLOCKSIZE_16) { float nextData = objIndex[index]; if (sData[threadIdx.y][threadIdx.x] > nextData) { sData[threadIdx.y][threadIdx.x] = nextData; sIndx[threadIdx.y][threadIdx.x] = index; } } /* BLOCKSIZE_16 个的内部规约,到只剩 2 个 */ for (int step = BLOCKSIZE_16 / 2; step > 1; step = step >> 1) { int idxStep = threadIdx.x + step; if (threadIdx.x < step && sData[threadIdx.y][threadIdx.x] > sData[threadIdx.y][idxStep]) { sData[threadIdx.y][threadIdx.x] = sData[threadIdx.y][idxStep]; sIndx[threadIdx.y][threadIdx.x] = sIndx[threadIdx.y][idxStep]; } //__syncthreads(); } if (threadIdx.x == 0) { objClusterIdx_Dev[y_id] = sData[threadIdx.y][0] < sData[threadIdx.y][1] ? sIndx[threadIdx.y][0] : sIndx[threadIdx.y][1]; } } } /** * 功能:并行 Kmeans 聚类 * 输入:objData_Host 样本数据 * 输出:objClassIdx_Host 每个样本的类别索引 * 输出:centerData_Host 聚类中心 * 输入:myPatameter 输入参数 */ void KmeansCUDA(float *objData_Host, int *objClassIdx_Host, float*centerData_Host, sParameter myParameter) { /* 开辟设备端内存 */ float *objData_Dev, *centerData_Dev; cudaMalloc((void**)&objData_Dev, myParameter.objNum * myParameter.objLength * sizeof(float)); cudaMalloc((void**)¢erData_Dev, myParameter.clusterNum * myParameter.objLength * sizeof(float)); cudaMemcpy(objData_Dev, objData_Host, myParameter.objNum * myParameter.objLength * sizeof(float), cudaMemcpyHostToDevice); int *objClassIdx_Dev; cudaMalloc((void**)&objClassIdx_Dev, myParameter.objNum * sizeof(int)); float *distOfObjAndCluster_Dev; // 每个样本与聚类中心的欧式距离 cudaMalloc((void**)&distOfObjAndCluster_Dev, myParameter.objNum * myParameter.clusterNum * sizeof(float)); int *objNumInCluster_Dev; // 每个聚类中的样本数 cudaMalloc((void**)&objNumInCluster_Dev, myParameter.clusterNum * sizeof(int)); /* 线程块和线程格 */ dim3 dimBlock1D_16(BLOCKSIZE_16 * BLOCKSIZE_16); dim3 dimBlock1D_32(BLOCKSIZE_32 * BLOCKSIZE_32); dim3 dimGrid1D_16((myParameter.objNum + BLOCKSIZE_16 * BLOCKSIZE_16 - 1) / dimBlock1D_16.x); dim3 dimGrid1D_32((myParameter.objNum + BLOCKSIZE_32 * BLOCKSIZE_32 - 1) / dimBlock1D_32.x); dim3 dimBlock2D(BLOCKSIZE_16, BLOCKSIZE_16); dim3 dimGrid2D_Cluster((myParameter.objLength + BLOCKSIZE_16 - 1) / dimBlock2D.x, (myParameter.clusterNum + BLOCKSIZE_16 - 1) / dimBlock2D.y); dim3 dimGrid2D_ObjNum_Objlen((myParameter.objLength + BLOCKSIZE_16 - 1) / dimBlock2D.x, (myParameter.objNum + BLOCKSIZE_16 - 1) / dimBlock2D.y); dim3 dimGrid2D_ObjCluster((myParameter.clusterNum + BLOCKSIZE_16 - 1) / dimBlock2D.x, (myParameter.objNum + BLOCKSIZE_16 - 1) / dimBlock2D.y); dim3 dimGrid2D_ObjNum_BLOCKSIZE_16(1, (myParameter.objNum + BLOCKSIZE_16 - 1) / dimBlock2D.y); // 记录时间 cudaEvent_t start_GPU, end_GPU; float elaspsedTime; cudaEventCreate(&start_GPU); cudaEventCreate(&end_GPU); cudaEventRecord(start_GPU, 0); /* 样本聚类索引的初始化*/ KmeansCUDA_Init_ObjClusterIdx<<<dimGrid1D_16, dimBlock1D_16>>>(objClassIdx_Dev, myParameter.objNum, myParameter.clusterNum); for (int i = 0; i < myParameter.maxKmeansIter; i++) { cudaMemset(centerData_Dev, 0, myParameter.clusterNum * myParameter.objLength * sizeof(float)); cudaMemset(objNumInCluster_Dev, 0, myParameter.clusterNum * sizeof(int)); /* 统计每一类的样本和 */ KmeansCUDA_Update_Cluster<<<dimGrid2D_ObjNum_Objlen, dimBlock2D>>>(objData_Dev, objClassIdx_Dev, centerData_Dev, myParameter); /* 统计每一类的样本个数 */ //KmeansCUDA_Count_objNumInCluster1<<<dimGrid1D_16, dimBlock1D_16>>>(objClassIdx_Dev, objNumInCluster_Dev, myParameter); KmeansCUDA_Count_objNumInCluster<<<dimGrid1D_32, dimBlock1D_32>>>(objClassIdx_Dev, objNumInCluster_Dev, myParameter); /* 聚类中心平均 = 样本和 / 样本个数 */ KmeansCUDA_Scale_Cluster<<<dimGrid2D_Cluster, dimBlock2D>>>(centerData_Dev, objNumInCluster_Dev, myParameter); /* 计算每个样本与每个聚类中心的欧式距离 */ KmeansCUDA_distOfObjAndCluster<<<dimGrid2D_ObjCluster, dimBlock2D>>>(objData_Dev, objClassIdx_Dev, centerData_Dev, distOfObjAndCluster_Dev, objNumInCluster_Dev, i, myParameter); /* 根据每个样本与聚类中心的欧式距离更新样本的类标签 */ //KmeansCUDA_Update_ObjClusterIdx1<<<dimGrid1D_16, dimBlock1D_16>>>(objClassIdx_Dev, distOfObjAndCluster_Dev, myParameter); KmeansCUDA_Update_ObjClusterIdx<<<dimGrid2D_ObjNum_BLOCKSIZE_16, dimBlock2D>>>(objClassIdx_Dev, distOfObjAndCluster_Dev, myParameter); } // 计时结束 cudaEventRecord(end_GPU, 0); cudaEventSynchronize(end_GPU); cudaEventElapsedTime(&elaspsedTime, start_GPU, end_GPU); std::cout << "Kmeans 的运行时间为:" << elaspsedTime << "ms." << std::endl; /* 输出从设备端拷贝到内存 */ cudaMemcpy(objClassIdx_Host, objClassIdx_Dev, myParameter.objNum * sizeof(int), cudaMemcpyDeviceToHost); cudaMemcpy(centerData_Host, centerData_Dev, myParameter.objNum * myParameter.objLength * sizeof(float), cudaMemcpyDeviceToHost); /* 释放设备端内存 */ cudaFree(objData_Dev); cudaFree(objClassIdx_Dev); cudaFree(centerData_Dev); cudaFree(distOfObjAndCluster_Dev); cudaFree(objNumInCluster_Dev); }
ClassParameter.h
#ifndef CLASSPARAMETER_H #define CLASSPARAMETER_H // 参数 class sParameter { public: int objNum; // 样本数 int objLength; // 样本维度 int clusterNum; // 聚类数 int minClusterNum; // 最少的聚类数 int minObjInClusterNum; // 每个聚类中的最少样本数 int maxKmeansIter; // 最大迭代次数 }; #endif // !CLASSPARAMETER_H

















 5589
5589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









