




一、实现流程
二、altermanger组件部署
三、规则文件
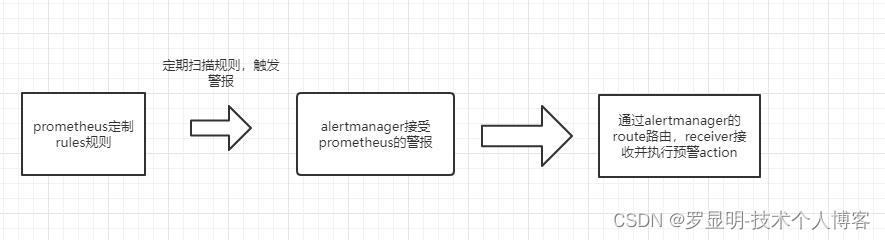
一、报警原理流程
报警明细说明:
1. prometheus服务器编写警报规则,警报规则使用我们收集的指标,通过阈值比对,触发警报
2. prometheus将警报推送到alertmanager
3. alertmanager对警报进行去重、分组、路由到指定的接收器
4. 接收器执行相应的动作
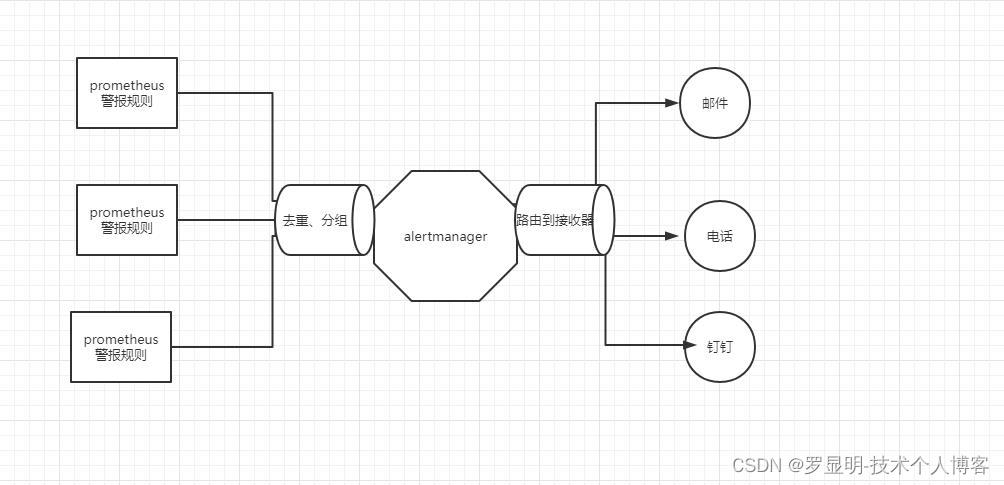
说明:alertmanager处理从客户端prometheus发过来的警报,对警报进行去重、分组、然后路由到不同的接收器,执行相应的动作,例如:短信、电话、邮件
二、alertmanager部署
1、下载软件包(可以官网查看最新的)
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
2、创建部署目录tar -xf alertmanager-0.24.0.linux-amd64.tar.gz -C /usr/local/
mv alertmanager-0.24.0.linux-amd64 alertmanager
3、编辑配置文件
cat alertmanger.yml
###################
global:
smtp_smarthost: 'smtp.qq.com:465' # smtp地址
smtp_from: '450776257@qq.com' # 谁发邮件
smtp_auth_username: '450776257@qq.com' # 邮箱用户
smtp_auth_password: 'xxxxxxxxxxx' #不是用户密码,是邮箱的
smtp_require_tls: false #必须设置未FALSE,因为默认未TRUEtemplates: #包含保存警报模板的目录列表
- '/usr/local/alertmanager/template/*.tmpl'route:
group_by: ["instance"] # 分组名
group_wait: 30s # 当收到告警的时候,等待三十秒看是否还有告警,如果有就一起发出去
group_interval: 5m # 发送警告间隔时间
repeat_interval: 3h # 重复报警的间隔时间
receiver: mail # 全局报警组,这个参数是必选的,和下面报警组名要相同receivers: #接收器
- name: 'mail' # 报警组名
email_configs:
- to: '18717124161@163.com' # 发送给谁
配置块说明:
global块: 定义alertmanager全局配置,这里的选项为所有其他块设置默认值
template:定义警报模板列表
route:定义路由;注意可以定义子路由
receiver: 定义接收器;每个接收器都有名称和配置项
# 启动alertmanager
nohup ./alertmanager --config.file alertmanager.yml &
# alertmanager提供了web管理界面,默认端口9093
http://192.168.161.20:9093
#prometheus配置alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.161.20:9093
#监控alertmanager
- job_name: "alertmanager"
static_configs:
- targets: ["192.168.161.20:9093"]
说明:
http://192.168.161.20:9093/metrics收集指标并抓取以alertmanager_为前缀的时间序列数据
# 添加警报规则
#与记录规则一样,警报规则在prometheus中也是用YMAL语句定义
#rules目录下创建node_alerts.yml
groups:
- name: node_alerts
rules:
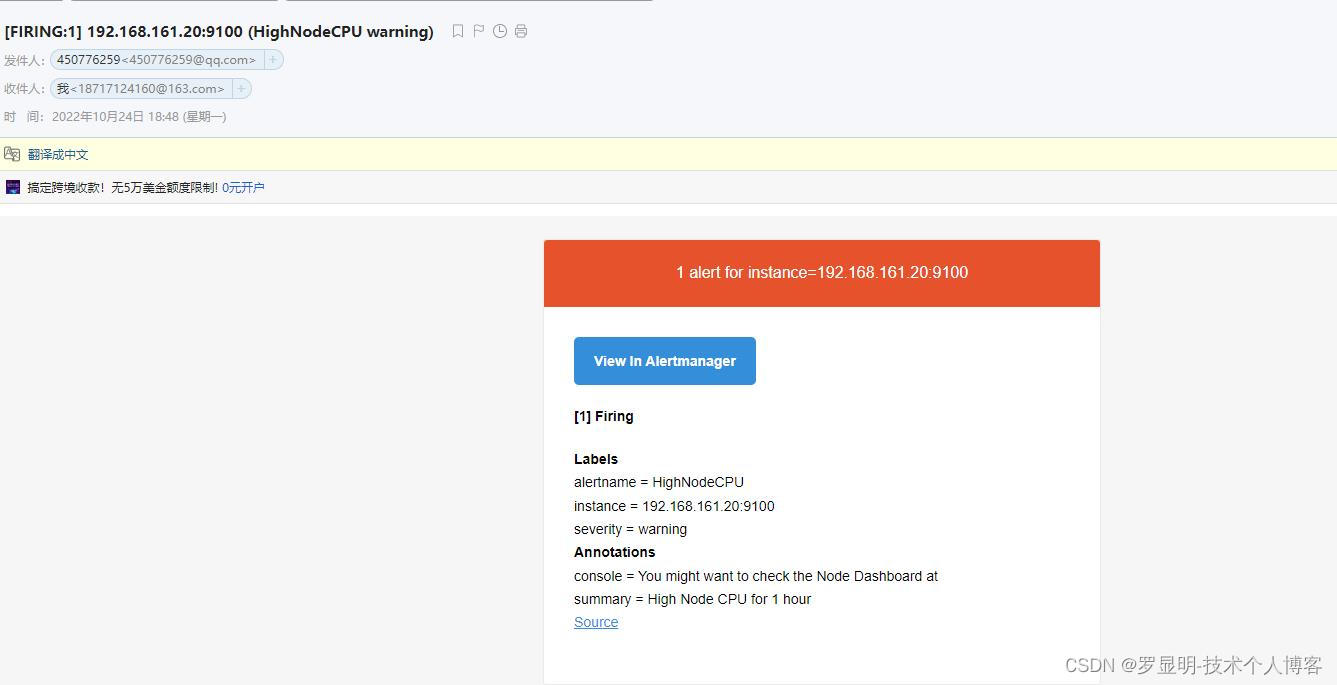
- alert: HighNodeCPU
expr: instance:node_cpu:avg_rate5m >80
for: 1m
labels:
severity: warning
annotations:
summary: High Node CPU for 1 hour
console: You might want to check the Node Dashboard at- alert: DiskWillFillIn4Hours
expr: predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h],4*3600) <0
for: 5m
labels:
severity: critical
annotations:
summary: Disk on {{ $labels.instance }} will fill in approximately 4 hours- alert: InstanceDown
expr: up{job="node"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is down
#关键字说明
alert: 警报名称。每个警报组中,警报名称必须唯一
expr:触发警报表达式
for: 触发警报之前表达式必须为TRUE的持续时间
labels: 标签。我们可以给警报添加标签
annotation:注解。通过注解,我们可以展示警报的更多的信息
注意:警报上的标签和警报名称相结合,构成了警报的标识
通过stress进行压测,提升CPU使用率,促使prometheus进行预警
stress -c 2
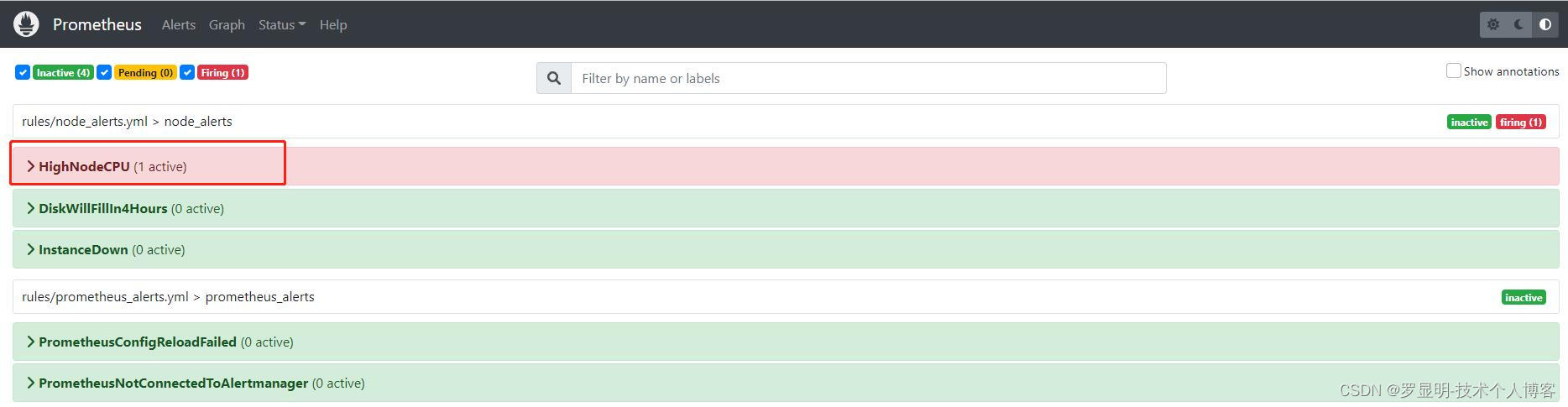
警报的三种状态
1. Inactive
警报未激活
2. Pending
警报已经满足测试表达式条件,但仍等待for子句中指定的持续时间
3. Firing
警报满足for的持续时间,已经触发
说明: 当报警表达式中指定了for,至少需要2个评估周期才能触发
1. 第一次评估周期,触发进入pending
2. 第二次评估周期,如果表达式仍旧为TRUE,则开始检查for的持续时间

















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









