






 本文详细介绍SQL数据库操作,包括字段的添加、修改、删除,表名和注释的更改,以及字段类型的调整。同时,深入解析MySQL函数,如FIND_IN_SET、EXISTS、concat与group_concat的用法,和时间函数的应用。通过实例展示如何优化SQL查询效率。
本文详细介绍SQL数据库操作,包括字段的添加、修改、删除,表名和注释的更改,以及字段类型的调整。同时,深入解析MySQL函数,如FIND_IN_SET、EXISTS、concat与group_concat的用法,和时间函数的应用。通过实例展示如何优化SQL查询效率。
1.数据库DLL操作
添加新字段
ALTER TABLE table_name ADD column_name VARCHAR(20) comment '注释';
新增字段直接设置默认值
ALTER TABLE table_name ADD column_name VARCHAR(20) NOT NULL DEFAULT 1;
修改表的名称呢
ALERT TABLE 表名 RENAME TO 新的名字;
修改表中的注释
ALTER TABLE table_name MODIFY COLUMN 字段名 varchar(32) comment '修改注释';
修改字段类型
ALTER TABLE table_name MODIFY COLUMN 字段名 修改类型;
修改字段名
ALTER TABLE table_name CHANGE 旧的字段 新的字段 字段数据类型; eg:alter table ta0 change unames uname varchar(20);
修改字段时 指定设置默认值。
ALTER TABLE table_name MODIFY column_name VARCHAR(20) NOT NULL DEFAULT 1;
修改字段默认值
ALTER TABLE table_name ALTER column_name SET DEFAULT 1000;
删除字段默认值
ALTER TABLE table_name ALTER column_name DROP DEFAULT;
删除数据库中的字段
ALTER TABLE table_name DROP COLUMN column_name;
SQL中改变列的数据类型
一、该列非主键、无default约束
直接更新:
alter table 表名 alter column 列名 数据类型
二、该列为主键列、无default约束
(1)删除主键
alter table 表名 drop constraint 主键名称
(2)更新数据类型
alter table 表名 alter column 列名 数据类型 not null
(3)添加主键
alter table 表名 add constraint 主键名称 primary key (主键字段1,主键字段2)
三、该列为主键列,有default约束
(1)删除主键
alter table 表名 drop constraint 主键名称
(2)解除default约束
USE 数据库名
IF EXISTS (SELECT name FROM sysobjects
WHERE name = 'default约束名'
AND type = 'D')
BEGIN
EXEC sp_unbindefault '数据表.字段'
END
GO
(3)更新数据类型
alter table 表名 alter column 列名 数据类型 not null
(4)添加主键
alter table 表名 add constraint 主键名称 primary key (主键字段1,主键字段2)
辅助语句:
(1)找出字段约束名称并赋值到变量中
declare @name varchar(50)
select @name =b.name from sysobjects b join syscolumns a on b.id = a.cdefault
where a.id = object_id('表名')
and a.name ='列名'
(2)将字段绑定到用户自定义的数据类型,并不影响现有绑定(使用futureonly)
此示例将默认值 def_ssn 绑定到用户定义的数据类型 ssn。因为已指定 futureonly,所以不影响类型 ssn 的现有列。
USE 数据库名
EXEC sp_bindefault '列名', '自定义数据类型', 'futureonly'
查询时间的结果比较:
SELECT NOW(),CURDATE(),CURTIME()
结果类似:NOW() CURDATE() CURTIME()
2008-12-29 16:25:46 2008-12-29 16:25:46
二、mysql函数
1:FIND_IN_SET(str,strlist)
定义:
1. 假如字符串str在由N子链组成的字符串列表strlist中,则返回值的范围在1到N之间。
2. 一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串。
3. 如果第一个参数是一个常数字符串,而第二个是typeSET列,则FIND_IN_SET()函数被优化,使用比特计算。
4. 如果str不在strlist或strlist为空字符串,则返回值为0。
5. 如任意一个参数为NULL,则返回值为NULL。这个函数在第一个参数包含一个逗号(‘,’)时将无法正常运行。
strlist:一个由英文逗号“,”链接的字符串,例如:"a,b,c,d",该字符串形式上类似于SET类型的值被逗号给链接起来。
示例:SELECT FIND_IN_SET('b','a,b,c,d'); //返回值为2,即第2个值
一篇较详细的文章:http://blog.sina.com.cn/s/blog_5b5460eb0100e5r9.html
https://www.cnblogs.com/mytzq/p/7090197.html
2:exist
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
EXISTS 指定一个子查询,检测 行 的存在。
EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...), 我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
https://www.cnblogs.com/qlqwjy/p/8598091.html
3:MySQL教程之concat以及group_concat的用法 https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc
concat()函数
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
3、举例:
例1:select concat (id, name, score) as info from tt2;
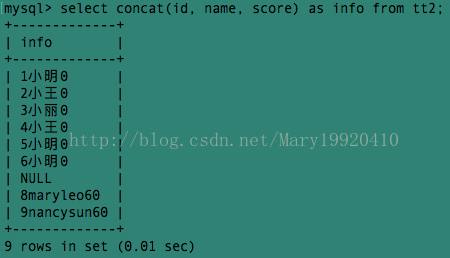
中间有一行为null是因为tt2表中有一行的score值为null。
例2:在例1的结果中三个字段id,name,score的组合没有分隔符,我们可以加一个逗号作为分隔符:
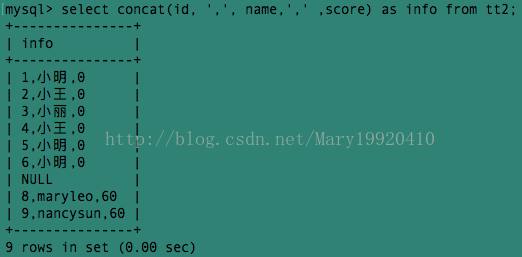
这样看上去似乎顺眼了许多~~
但是输入sql语句麻烦了许多,三个字段需要输入两次逗号,如果10个字段,要输入九次逗号...麻烦死了啦,有没有什么简便方法呢?——于是可以指定参数之间的分隔符的concat_ws()来了!!!
二、concat_ws()函数
1、功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
3、举例:
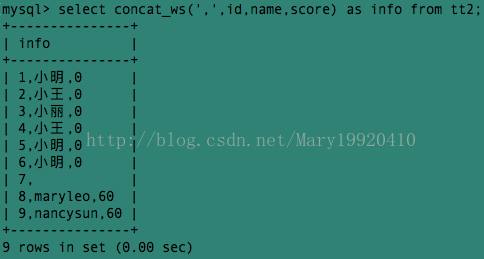
例3:我们使用concat_ws()将 分隔符指定为逗号,达到与例2相同的效果:
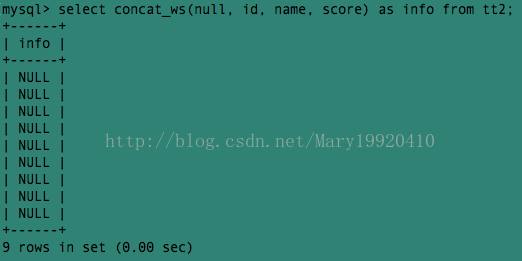
例4:把分隔符指定为null,结果全部变成了null:
三、group_concat()函数
前言:在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中。(有关group by的知识请戳:浅析SQL中Group By的使用)。
例5:
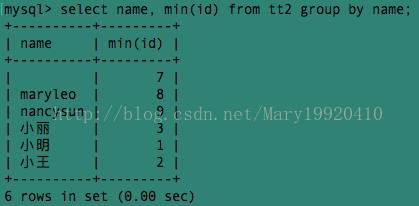
该例查询了name相同的的人中最小的id。如果我们要查询name相同的人的所有的id呢?
当然我们可以这样查询:
例6:
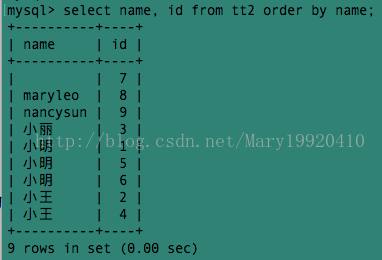
但是这样同一个名字出现多次,看上去非常不直观。有没有更直观的方法,既让每个名字都只出现一次,又能够显示所有的名字相同的人的id呢?——使用group_concat()
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
3、举例:
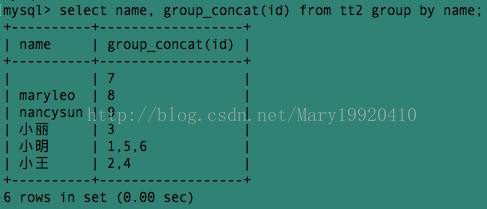
例7:使用group_concat()和group by显示相同名字的人的id号:
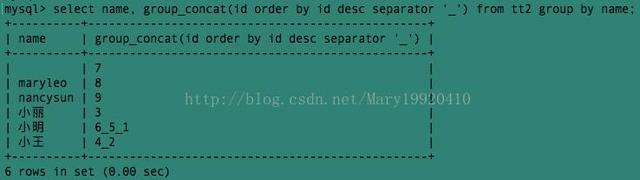
例8:将上面的id号从大到小排序,且用'_'作为分隔符:
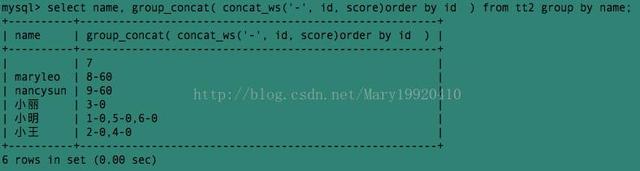
例9:上面的查询中显示了以name分组的每组中所有的id。接下来我们要查询以name分组的所有组的id和score:
4:时间函数 MySQL Date 函数 https://www.w3school.com.cn/sql/sql_dates.asp
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前的日期和时间 |
| CURDATE() | 返回当前的日期 |
| CURTIME() | 返回当前的时间 |
| DATE() | 提取日期或日期/时间表达式的日期部分 |
| EXTRACT() | 返回日期/时间按的单独部分 |
| DATE_ADD() | 给日期添加指定的时间间隔 |
| DATE_SUB() | 从日期减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的天数 |
| DATE_FORMAT() | 用不同的格式显示日期/时间 |
查询并集(union all)--未去重
SELECT oname,odesc FROM object_a
UNION ALL
SELECT oname,odesc FROM object_b
结果如下
查询并集(union)--去重
SELECT oname,odesc FROM object_a
UNION
SELECT oname,odesc FROM object_b
结果如下
PS:union自带去重
交集、并集、差集...等--https://blog.youkuaiyun.com/sanzhongguren/article/details/76615464

















 3785
3785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









