




 本文详细介绍了Apache Spark的任务调度机制,包括Task的概念及其类型、任务的提交过程、序列化机制、TaskScheduler的工作原理以及任务在Executor上的执行流程。
本文详细介绍了Apache Spark的任务调度机制,包括Task的概念及其类型、任务的提交过程、序列化机制、TaskScheduler的工作原理以及任务在Executor上的执行流程。
Task
一个执行单位, Spark中有两种Task:
Spark工作由一个或多个阶段组成, 作业的最后一个阶段由多个ResultTasks组成,而早期的阶段由ShuffleMapTasks组成
ShuffleMapTask
ShuffleMapTask执行任务并将任务输出分为多个桶(基于任务的分区程序)ResultTask
ResultTask执行任务并将任务输出发送回驱动程序应用程序
task提交
DAGScheduler.submitMissingTasks
stage.findMissingPartitions首先找出要计算的分区id的索引
partitionsToCompute
findMissingPartitions:找到没有执行的partition的Id集合序列化
ShuffleMapStage: 序列化该stage的RDD与依赖
ResultStage: 序列化该stage的RDD和在RDD的每个分区上运行的函数var taskBinary: Broadcast[Array[Byte]] = null try { // For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep). // For ResultTask, serialize and broadcast (rdd, func). val taskBinaryBytes: Array[Byte] = stage match { case stage: ShuffleMapStage => closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array() case stage: ResultStage => closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array() } taskBinary = sc.broadcast(taskBinaryBytes) } catch { // In the case of a failure during serialization, abort the stage. case e: NotSerializableException => abortStage(stage, "Task not serializable: " + e.toString, Some(e)) runningStages -= stage // Abort execution return case NonFatal(e) => abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return }broadcast
taskBinary = sc.broadcast(taskBinaryBytes)
把这个task广播到各个Executor,taskBinaryBytes就是上一步序列化的元数据根据分区和stage转化Tasks
包括stageId,attemptId,broadcast元数据,stage中RDD的分区,task执行首选host,partitionId,
internalAccumulators(TODO)ShuffleMapStage: Seq(ShuffleMapTask)
ResultStage: Seq(ResultTask)val tasks: Seq[Task[_]] = try { stage match { case stage: ShuffleMapStage => partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.internalAccumulators) } case stage: ResultStage => val job = stage.activeJob.get partitionsToCompute.map { id => val p: Int = stage.partitions(id) val part = stage.rdd.partitions(p) val locs = taskIdToLocations(id) new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators) } } } catch { case NonFatal(e) => abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return }最后提交taskScheduler
taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
TaskScheduler
该接口被不同调度器实现, 每个SparkContext中只有一个TaskScheduler实例来调度任务,
从上面DAGScheduler分析也能看出,每个stage会提交taskSet到该调度器,由该调度器负责将任务发送到集群,运行它们,
在出现故障时重试以及mitigating stragglers(???), 他们将活动返回给DAGScheduler。
我们先分析TaskSchedulerImpl,
submitTasks
createTaskSetManager创建TaskSetManagerschedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)把
TaskSetManager插入资源生成器中SchedulableBuilder:一个接口来构建可调度树
buildPools:构建树节点(池)
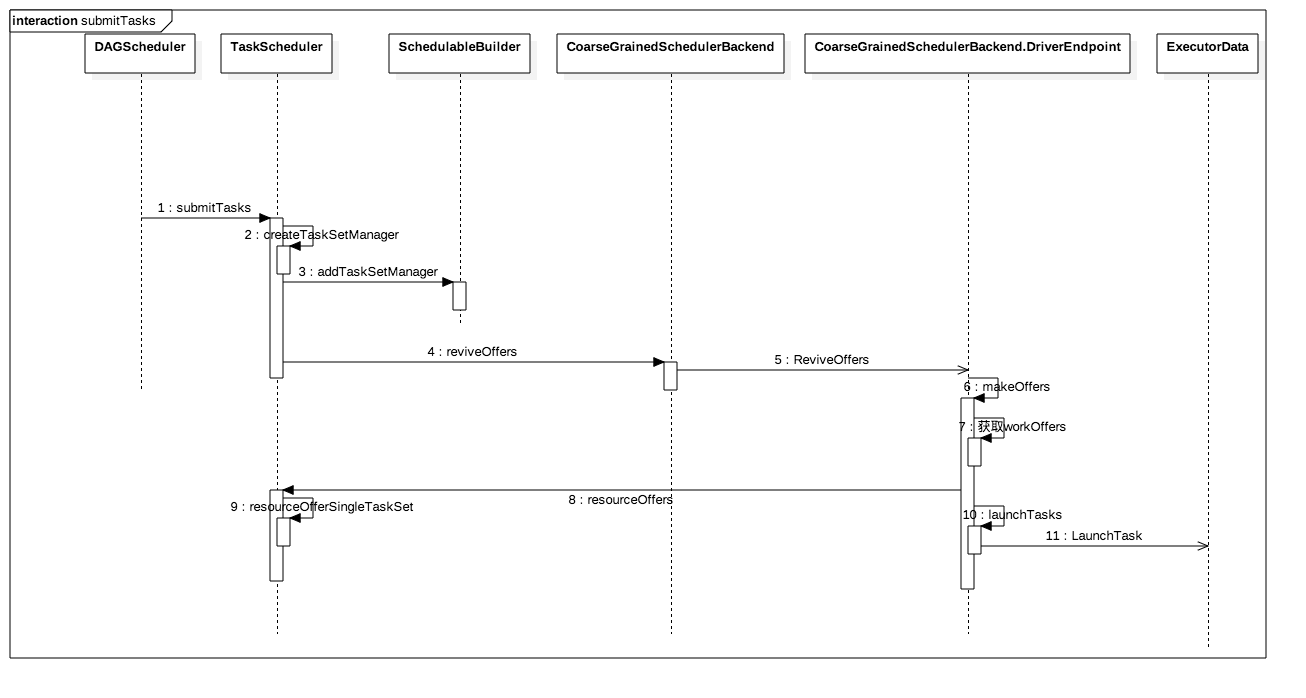
addTaskSetManager:构建叶节点(TaskSetManagers)SchedulerBackend.reviveOffers(): 主要功能告诉Driver后端RPC服务,我taskSet准备好了,你尝试执行一下DriverEndpoint.makeOffers: 获取active executor,即workOffersTaskScheduler.resourceOffers(workOffers): 根据workOffers根据TaskSet的core/mem/位置要求确定executorCoarseGrainedSchedulerBackend.launchTasks(task): 启动tasks,先序列化task元数据,rpc发送到executor上
我们画一个流程图方便理解调度关系:
TaskSetManager
在TaskSchedulerImpl的单个TaskSet中安排任务。
此类跟踪的 每个任务在失败时重试任务(达到有限次数),以及通过延迟调度处理此TaskSet的区域感知调度。
它的主要接口是resourceOffer,它询问TaskSet是否想要在一个节点上运行任务,和statusUpdate,
它告诉它它的一个任务改变了状态(例如finished)。
SchedulerBackend
上面这行流程涉及到一些类这里解释一下:用于调度系统的后端接口,允许在TaskSchedulerImpl下插入不同的接口
实现类如CoarseGrainedSchedulerBackend(先分析这个类): 粗粒度Driver后端调度器,
startcreateDriverEndpoint`创建DriverEndpoint服务
DriverEndpoint: 粗粒度Driver后端RPC服务,接收RPC发送的Events
executor如何执行task
启动Executor服务,初始化Executor,还可以接收不同的注册过的事件比如LaunchTask
ExecutorBackend
executor执行器, 实现类如CoarseGrainedExecutorBackend粗粒度后台执行器,Executor中执行,
接收SchedulerBackend提交的task任务,以线程TaskRunner方式执行,流程如下:
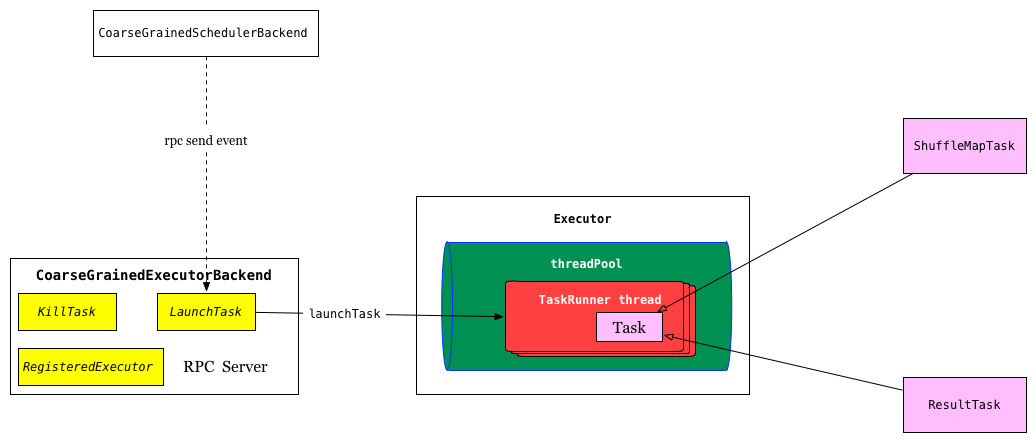
TaskRunner首先反序列化task,调用task.run方法,task内部先设置上下文环境,然后执行runTask,该方法被子类实现:
ShuffleMapTask
runTask:
ShuffleMapTask将RDD的元素划分为多个桶(基于partitioner中的ShuffleDependency)
首先把广播变量还原成RDD与dependency,从ShuffleManager获取ShuffleWriter,rdd.iterator管道流出来之后,
写到对应分区,比如HashShuffleWriter:
override def write(records: Iterator[Product2[K, V]]): Unit = {
val iter = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
shuffle.writers(bucketId).write(elem._1, elem._2)
}
}ShuffleManager
在Driver端中创建SparkEnv时创建,不同manager实现不同ShuffleWriter,如:
SortShuffleManager=>ShuffleWriter
HashShuffleManager=>HashShuffleWriter
ResultTask
runTask:
该Task会将执行结果发送回Driver端
首先序列化广播变量,获得rdd与func,该func是之前ResultStage介绍过,Driver端定义的合并合并函数,
同样执行rdd.iterator管道,但是与ShuffleMapTask不同的是,该类task可能需要到shuffledRDD,即依赖不同执行器中的
partitions,从不同节点上拉数据的逻辑在shuffledRDD.compute方法中,之前介绍RDD时提到过


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









