




 本文介绍了一种使用Python爬虫技术批量抓取网站上的励志文章的方法,包括如何解析URL、发送请求、使用正则表达式提取标题和文章内容,并将其保存为HTML文件的全过程。
本文介绍了一种使用Python爬虫技术批量抓取网站上的励志文章的方法,包括如何解析URL、发送请求、使用正则表达式提取标题和文章内容,并将其保存为HTML文件的全过程。
学了大概4、5天的爬虫终于能爬点图片和文章了
其实这两个差不多,后面一个稍微复杂一点
这次来讲解一下怎么爬取标题的这个网址
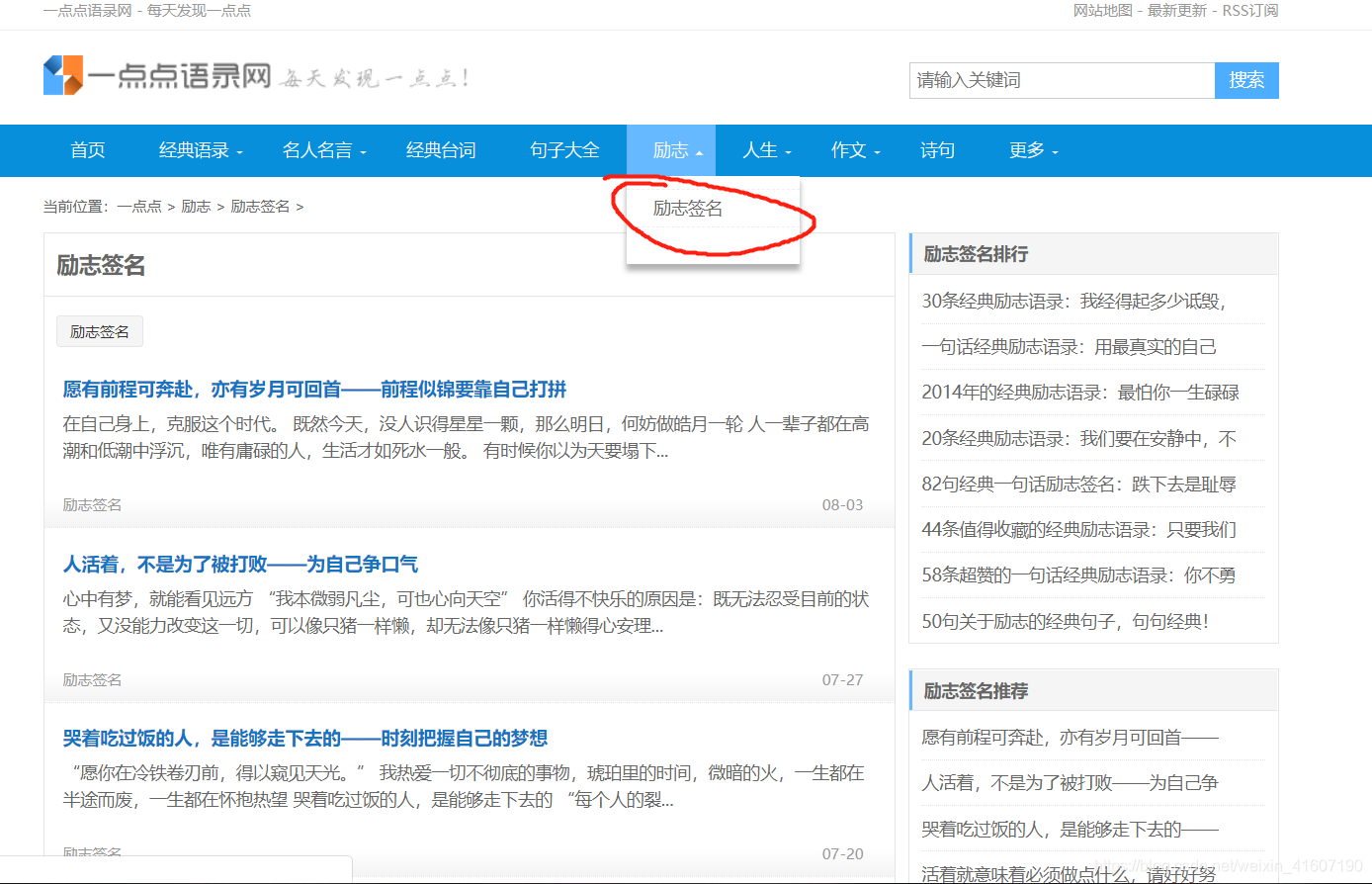
要做的是爬取这些文章,我们输入起始页码和结束页码,爬取页码之间的每篇文章
我们现在看到的是标题,标题点进去之后才是我们要的文章,我们要把每篇文章写进一个html文件里
需求就是这样,开工!
首先我们看看url和页码有什么关系


很明显就是后面的50_n.html就是决定页码的地方了
那么第一步先去获取响应
import urllib.request
import urllib.parse
import re
import os
import time
def main():
url = 'http://www.yikexun.cn/lizhi/qianming/'
start_page = int(input('输入起始页码:'))
end_page = int(input('输入结束页码:'))
for page in range(start_page, end_page + 1):
#生成请求对象
request = handle_request(url, page)
#发送请求,获取响应
content = urllib.request.urlopen(request).read().decode()
#下载句子,封装成函数
download(content)
因为不止有一页,我用了一个循环,每一页发送一个请求
然后把生成请求对象封装成一个函数,可以让代码更简洁
def handle_request(url, page=None):
#如果没有页数这个参数,就不拼接url
if page != None:
url = url + 'list_50_' + str(page) + '.html'
# print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3590.0 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
return request
函数根据页数和url拼接,得到我们想要的那一页的网址
打印出来大概是这样
http://www.yikexun.cn/lizhi/qianming/list_50_1.html
http://www.yikexun.cn/lizhi/qianming/list_50_2.html
http://www.yikexun.cn/lizhi/qianming/list_50_3.html
那个if条件句是为了另一个请求做准备,因为另一个请求并不需要page这个参数,提高代码的重用
然后就是仿造信息头,生成请求对象,再返回到主函数
回到主函数,有了请求自然要去获取响应
我们把获取的响应直接转成字符串(用decode()函数)
这样方便我们后边用正则处理
处理句子我们也封装成一个函数
def download(content):
#加了re.S才能用 .*? 匹配换行符,想获取哪个,哪个加小括号
pattern = re.compile(r'<h3><a href="(/lizhi/qianming/\d+\.html)"><b>(.*?)</b></a>', re.S)
#把爬到的内容放到 lt 里面,以列表的格式。
lt = pattern.findall(content)
# print(lt)
#遍历列表
for href_title in lt:
#拼接这个文章的 url,文章的url是列表每个元组中的第零个元素
a_herf = 'http://www.yikexun.cn' + href_title[0]
#获取文章标题
title = href_title[-1]
#发送请求,再封装成一个函数,直接获取封装好的内容
text = get_text(a_herf)
#写入到html文件
string = '<h1>%s</h1>%s' %(title, text)
with open('lizhi.html', 'a') as fp:
fp.write(string)
第一步就是去匹配要的内容,这之前我们要看看网页的元素内容,鼠标放在文章标题上右键,检查就能看到网页的代码
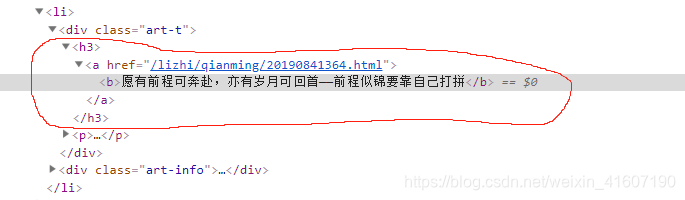
我匹配的仅仅是<h3>标签里的内容每一篇文章都是
很明显,我们也需要<a>标签中的url,因为那个就是我们文章的url,后面二次请求就要用到
pattern = re.compile(r'<h3><a href="(/lizhi/qianming/\d+\.html)"><b>(.*?)</b></a>', re.S)
解释下这个正则,用到了 \d+ 和 (.*?)
第一个是用来匹配数字,因为发现网页代码中,每篇文章的那里都不一样
第二个是用来匹配<b>标签中的文字,也就是标题
要注意的是 (.*?) 是非贪婪模式,后面要加上re.S这个参数才能匹配换行符,因为本来 “.” 就是匹配换行符以外的字符。至于为什么这么用,后面估计会有很多用 “.*?” 来匹配,所以现在就这么用着先
还有 \d+\. 后面的 \. 是转义字符,把". "当作字符而不是正则表达式
然后我们用 findall() 方法把之前获取的响应内容当作参数放里面,返回一个列表。列表中每一个元素都是一个元组,元组中的第一个是每一篇文章的标识,第二个是文章的标题,可以看到我们正则表达式也就用了两个,所以匹配出两个元素
[('/lizhi/qianming/20190841364.html', '愿有前程可奔赴,亦有岁月可回首——前程似锦要靠自己打拼'), ('/lizhi/qianming/20190741356.html', '人活着,不是为了被打败——为自己争口气'), ('/lizhi/qianming/20190741353.html', '哭着吃过饭的人,是能够走下去的——时刻把握自己的梦想'), ('/lizhi/qianming/20190741350.html', '活着就意味着必须做点什么,请好好努力——生活很难但请你坚持'), ('/lizhi/qianming/20190741338.html', '你想要赢,拿命来换——奋斗者的必读语录'), ('/lizhi/qianming/20190741330.html', '没有一个冬天不可逾越,没有一个春天不会来临——年轻人的励志经典语录'), ('/lizhi/qianming/20190741326.html', '钱非万能 无钱万万不能——现实的残酷要求你去拼搏'), ('/lizhi/qianming/20190641322.html', '前面的路还很远,你可能会哭,但是一定要走下去——励志追梦人的经典语录'), ('/lizhi/qianming/20190541318.html', '越努力越幸运,这句话真实存在——离梦想更近一步'), ('/lizhi/qianming/20190541315.html', '不要低头,要往上看,要去更高的地方——经典励志语录'), ('/lizhi/qianming/20190541314.html', '人一旦无畏,人生就会无限——成为你想成为的那个人'), ('/lizhi/qianming/20190541310.html', '虽然很辛苦,但努力过真好——将来的你会感谢现在的自己'), ('/lizhi/qianming/20190541303.html', '祝我们永远年轻永远热泪盈眶——年轻人努力奋斗的经典励志语录'), ('/lizhi/qianming/20190541301.html', '如果我踩不过荆棘,那么便不配得到风光——2019励志人生青春语录'), ('/lizhi/qianming/20190541295.html', '我知道你很累,但别人都在飞。——2019高考加油励志经典语录')]
这是我匹配出来结果,只能单行显示。。。每个小括号就是一个元组
到这里,文章标题我们已经处理好了,文章的url也获取了,所以现在发送第二次请求,获取文章内容
打开第一篇
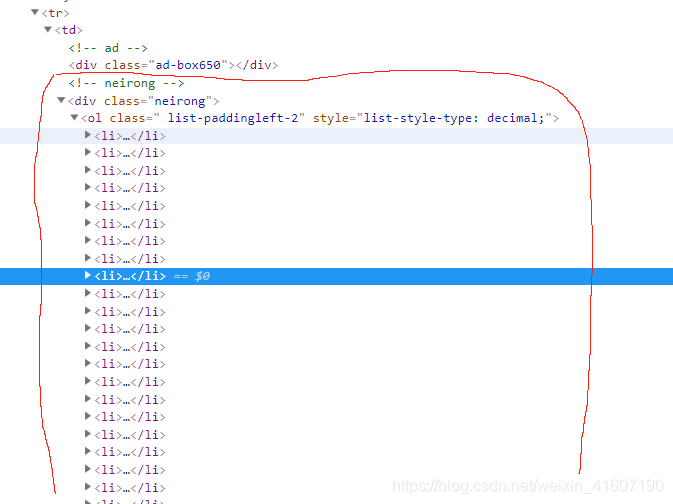
开发者还是挺贴心的,直接告诉我们这内容,打开方法还是一样,右键检查
要匹配的就是 <div class=neirong> 这个标签的东西
def get_text(href):
#调用函数handle_request,生成请求对象
request = handle_request(href)
#发送请求,获取响应内容
content = urllib.request.urlopen(request).read().decode()
#处理获取到的每一篇文章
pattern = re.compile(r'<div class="neirong">(.*?)</div>', re.S)
#返回列表
lt = pattern.findall(content)
# print(lt)
# exit()
#返回的列表只有一个元素
return lt[0]
直接看正则,没什么好说的,(.*?)匹配这标签之间的任何字符,这么理解就可以了
虽然网上看正则表达式规则蛮多的,实际用起来确实只有几个
直接返回列表,这里面就是文章了,因为只有一个元素,return lt[0] 就可以返回字符串,里面还是包含标签的,写进html文件时就能直接显示了
#写入到html文件
string = '<h1>%s</h1>%s' %(title, text)
with open('lizhi.html', 'a') as fp:
fp.write(string)
最后一步,在 download(content) 里面,然后就完成啦
看成果



更新一波,去除掉图片的标签,直接上代码吧
def get_text(href):
#调用函数handle_request,生成请求对象
request = handle_request(href)
#发送请求,获取响应内容
content = urllib.request.urlopen(request).read().decode()
#处理获取到的每一篇文章
pattern = re.compile(r'<div class="neirong">(.*?)</div>', re.S)
#返回列表
lt = pattern.findall(content)
text = lt[0]
#把里面的图片清除
patt = re.compile(r'<img .*?>', re.M)
text = patt.sub('', text)
# print(text)
# exit()
#返回的列表只有一个元素
return text

















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









