




 本文详细介绍了数据挖掘的过程,包括数据探索、特征工程和模型构建,并重点探讨了机器学习中的十大算法,如决策树、随机森林、逻辑回归等,深入解析了它们的工作原理和应用场景。
本文详细介绍了数据挖掘的过程,包括数据探索、特征工程和模型构建,并重点探讨了机器学习中的十大算法,如决策树、随机森林、逻辑回归等,深入解析了它们的工作原理和应用场景。
1、数据探索
主要基于pandas库,利用常见的:.head()、.value_counts()、.describe()、isnull()、.unique()等函数以及通过matplotlib作图对数据进行理解和探索。
2、特征工程
主要是通过从日期中提取年月日、季节、weekday,对年龄进行分段,计算相关特征之间的差值,根据用户id进行分组,从而统计一些特征变量的次数、平均值、标准差等,以及通过one-hot coding和labels encoding对数据进行编码来提取特征。
3、构建模型
主要基于sklearn包、xgboost包,通过调用不同的模型进行预测,其中涉及到的模型有:逻辑回归模型Logistic Regression;数模型DecisionTree、randomForest、AdaBoost、Bagging、ExtraTree、GraBoost;SVM模型SVM-rbf、SVM-poly、SVM-linear、xgboost;以及通过改变模型参数和数据量大小,来观察NDGG的评分结果,从而了解不同模型、不同参数和不同数据量大小对预测结果的影响。
机器学习十大算法:
监督学习:
1、决策树(Decision Trees/DT):
理解:根据一些feature进行分类,每个节点提一个问题,通过判断将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这颗树上的问题,将数据划分到合适的叶子上。
- 学习目标:根据给定的训练数据集构建一个决策树模型,使它能对实例进行正确的分类。
- 学习本质:从训练集中归纳出一组分类规则,或是由训练数据集估计条件概率模型。
- 损失函数:正则化的极大似然函数。
- 测试:最小化损失函数。
2、随机森林(Random Forest/RF)(集成算法中最简单的,模型融合算法)
在原数据中随机选取数据,组成几个子集。
S矩阵是源数据,有1-N条数据,a、b、c是feature,最后一列C是类别:
S=[fa1fb1fc1C1⋮⋮⋮⋮faNfbNfcNCN]S = \left[ \begin{matrix} f_{a1} & f_{b1} & f_{c1} & C_1 \\ \vdots & \vdots & \vdots & \vdots \\ f_{aN} & f_{bN} & f_{cN} & C_N \\ \end{matrix} \right] S=⎣⎢⎡fa1⋮faNfb1⋮fbNfc1⋮fcNC1⋮CN⎦⎥⎤
由S随机生成M个子矩阵,这M个子集得到M个决策树:将新数据投入到这M个树中,得到M个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果。
3、逻辑回归(logistic regressions)
当预测目标是概率这样的,值域需要满足“大于等于0”、 “小于等于1”,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出规定区间。
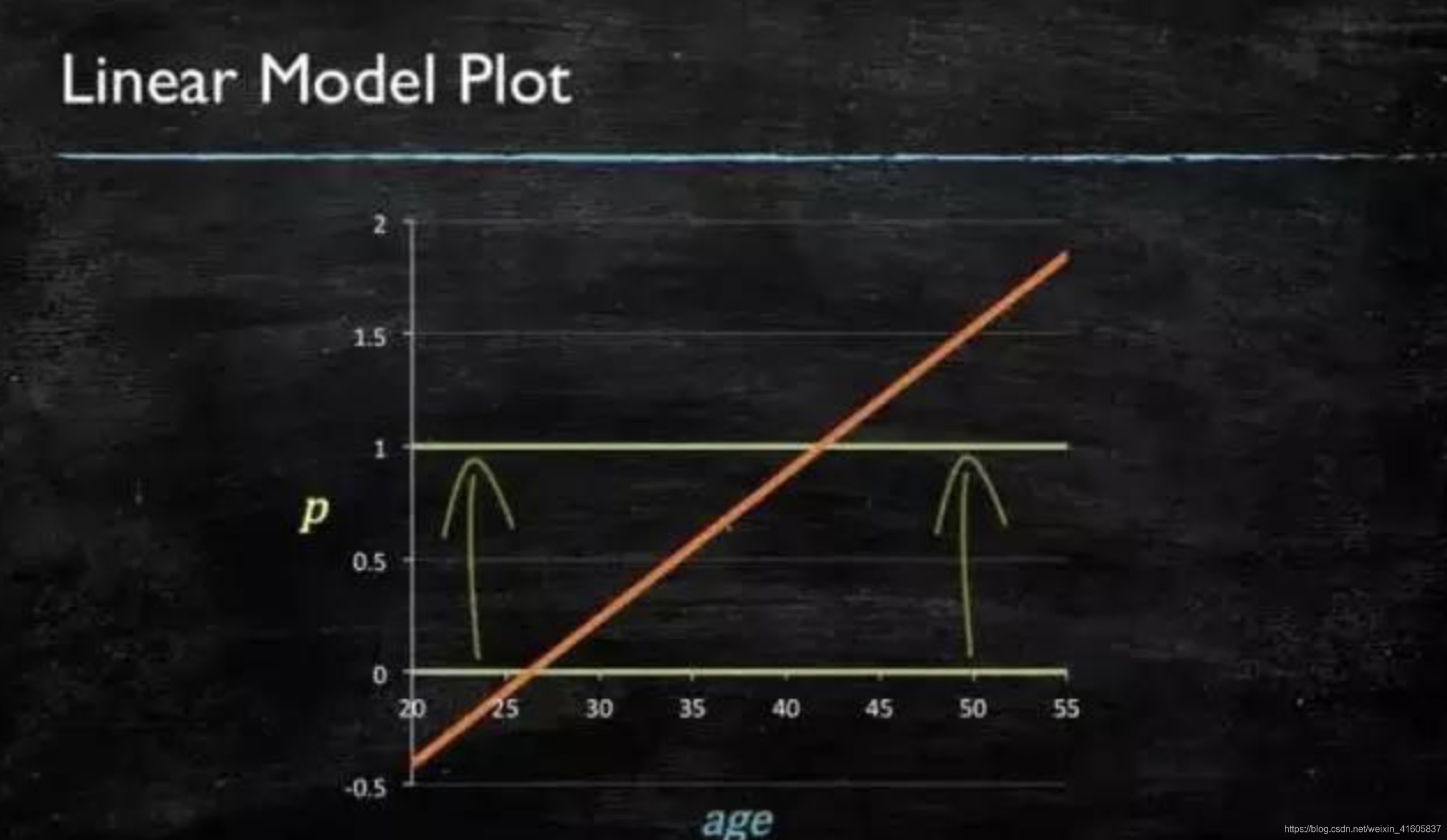
图3.1 线性模型图
所以此时需要如下的模型会比较好:
那么怎么得到这样的模型呢?
这个模型需要满足连个条件“大于等于0”、“小于等于1”。“大于等于0”的模型可以选择绝对值、平方值,这里用指数函数,一定大于0;“小于等于1”用除法,分子是自己,分母是自己+1。
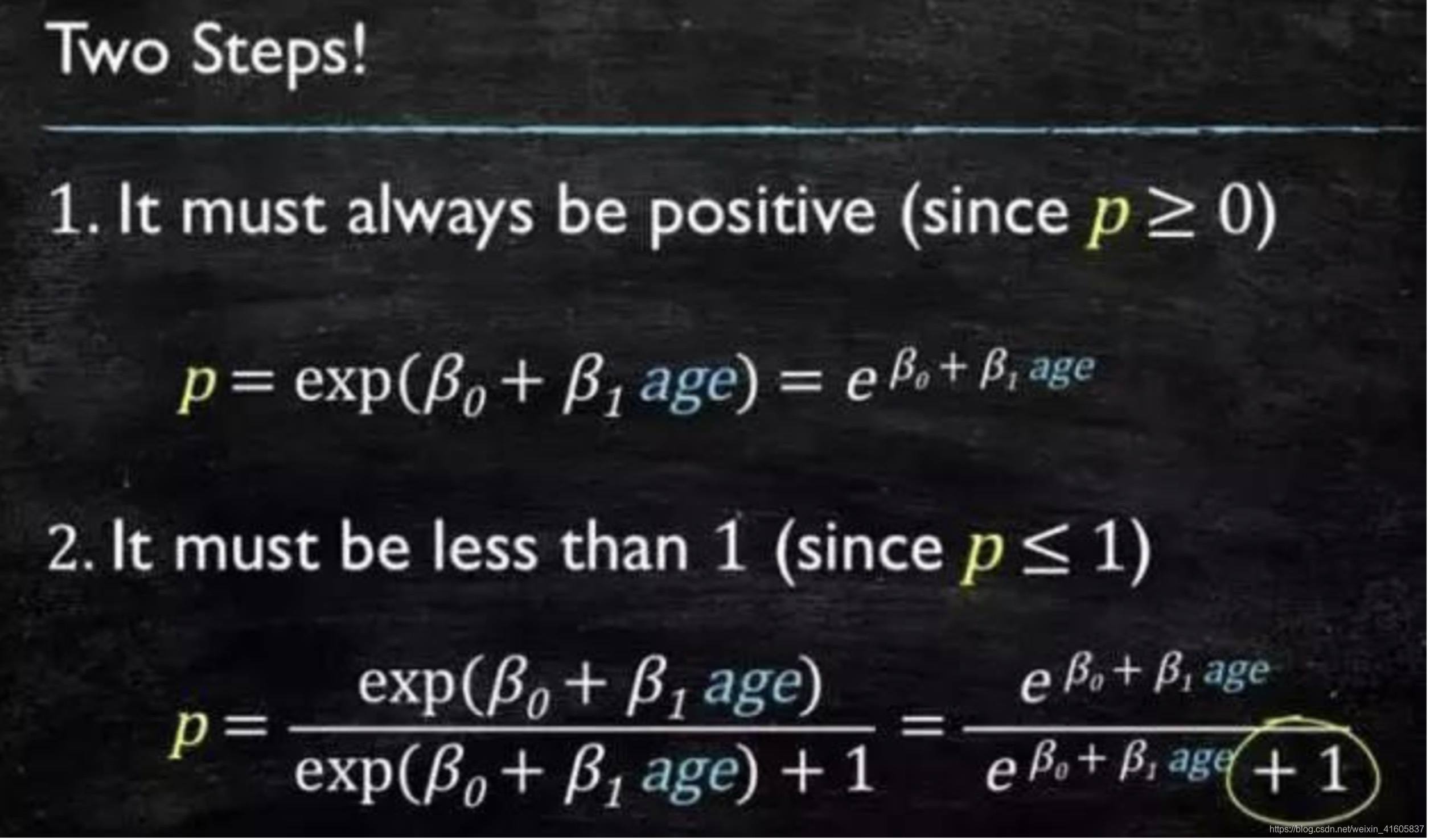
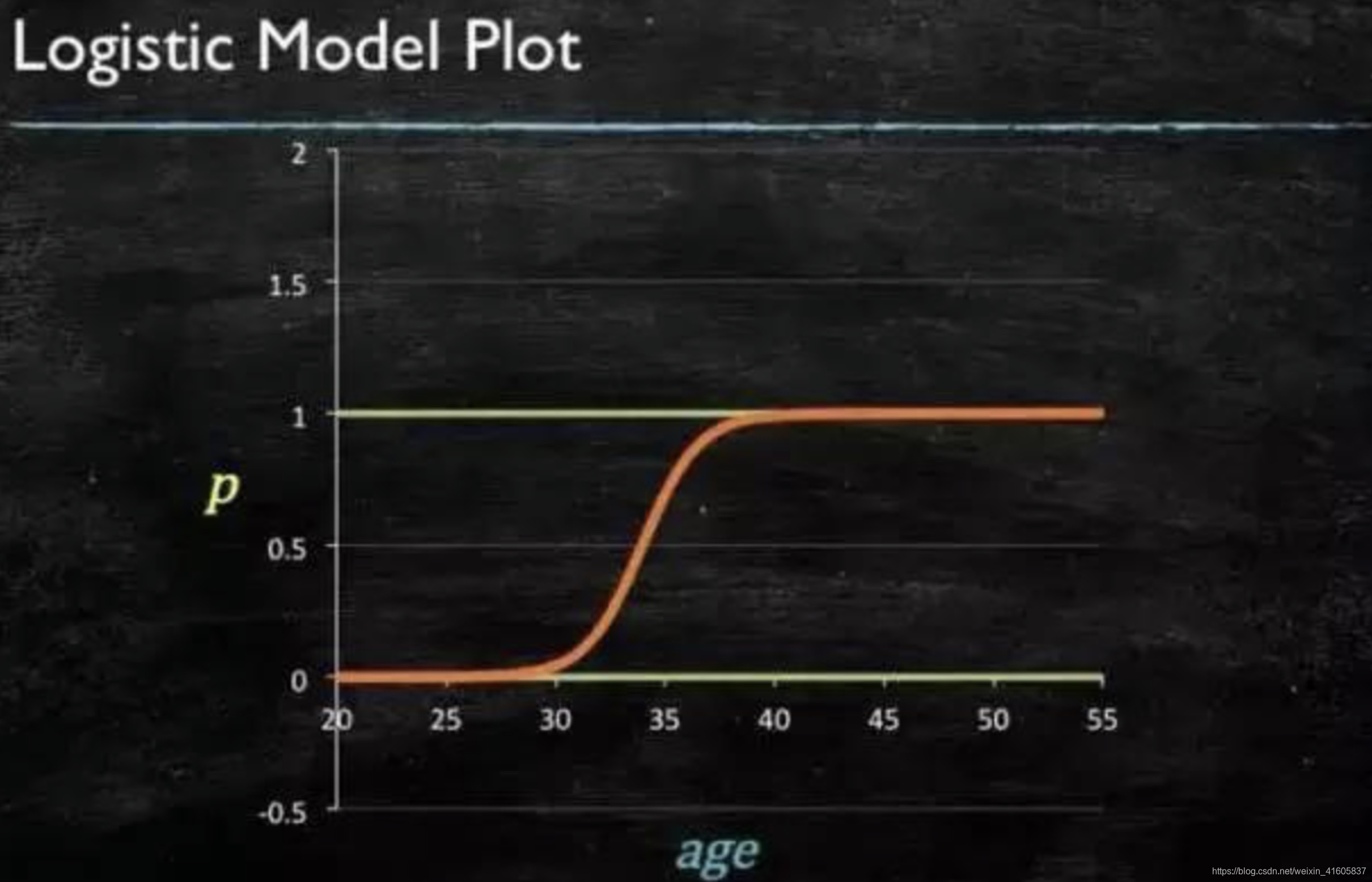
再做一下变形,就得到了logistic regressions模型:

通过原数据计算可以得到相应的系数:

4、支持向量机(SVM)
要将两类分开,想要得到一个超平面,最优的超平面是到两类的margin达到最大,margin就是超平面与离它近一点的距离,如图4.1,Z2>Z1,所以绿色的超平面比较好。
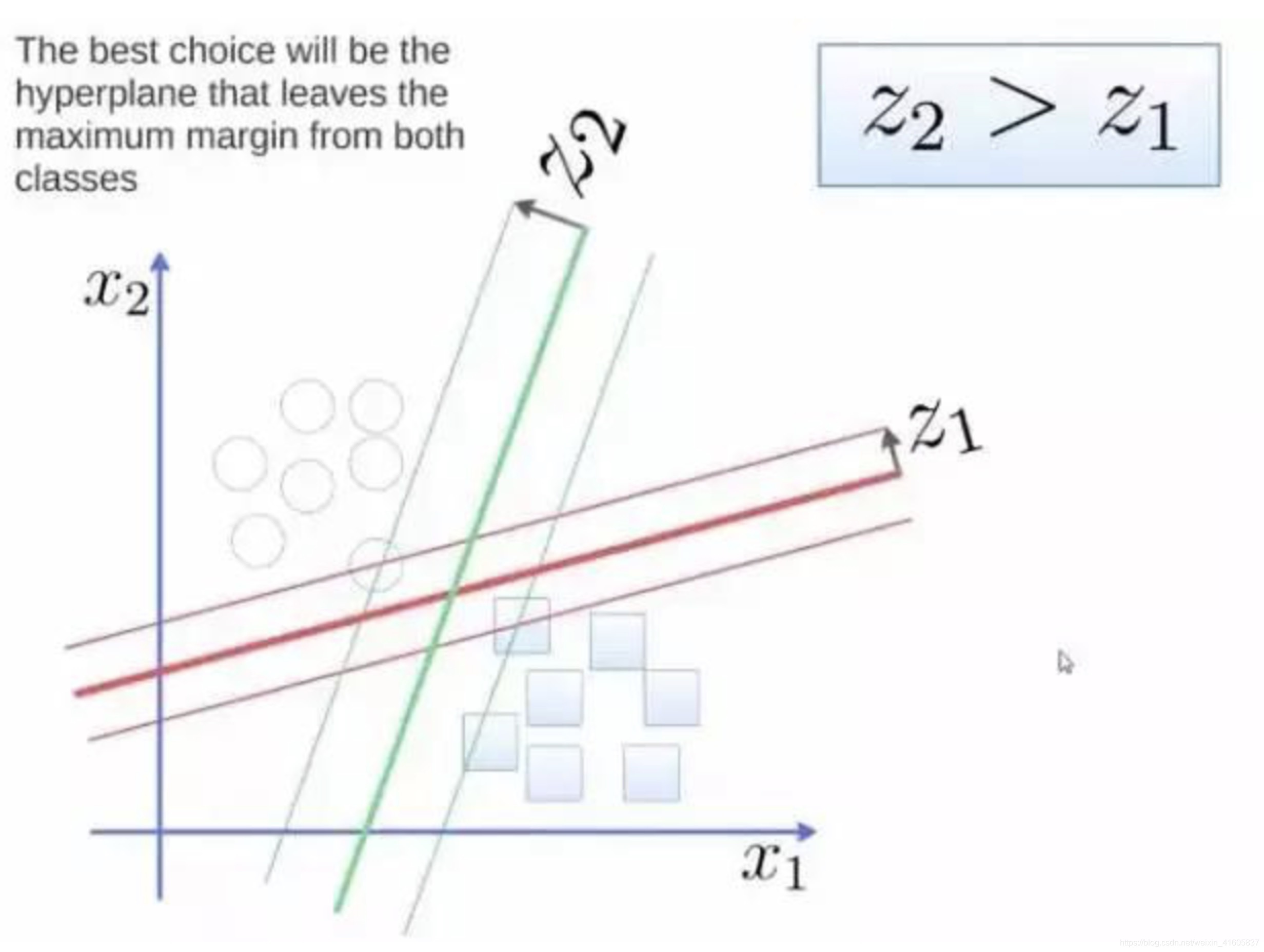
图4.1 分类超平面
将这个超平面表示成一个线性方程,如图4.2,在线上方的一类,都大于等于1,另一类小于等于-1:
g(x⃗)≥1,∀x⃗∈class1g(\vec{x})\geq1, \forall\vec{x}\in class1g(x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









