




 探讨使用Kettle从文本文件读取数据,通过自定义脚本处理并转化为JSON格式,最终推送至Kafka的过程。文章详细记录了遇到的问题及解决方法,包括Kettle插件配置、JSON格式调整及与Logstash、Elasticsearch集成的最佳实践。
探讨使用Kettle从文本文件读取数据,通过自定义脚本处理并转化为JSON格式,最终推送至Kafka的过程。文章详细记录了遇到的问题及解决方法,包括Kettle插件配置、JSON格式调整及与Logstash、Elasticsearch集成的最佳实践。
警告: 本篇博客是记录一个学习的过程,中间会有很多弯路
kettle中可以使用多种输入输出, 常用的有:表输入,文件输入,表输出,文件输出等, 本文用到的输入为txt文本文件输入, 输出类型为输出到kafka
这里解释一下为什么要是用kafka而不是直接生成文件到本地
因为需要处理的数据是比较多的, 一般是几亿条, 或者几十亿条, 文件大概是几个G到几十G, 如果生成的文件落地到磁盘, 那将会非常耗费资源
kettle清洗数据建立快速索引
kettle从数据源获取数据, 这里是从txt文件中获取
首先新建一个转换
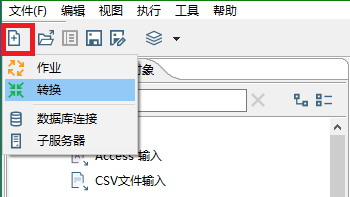
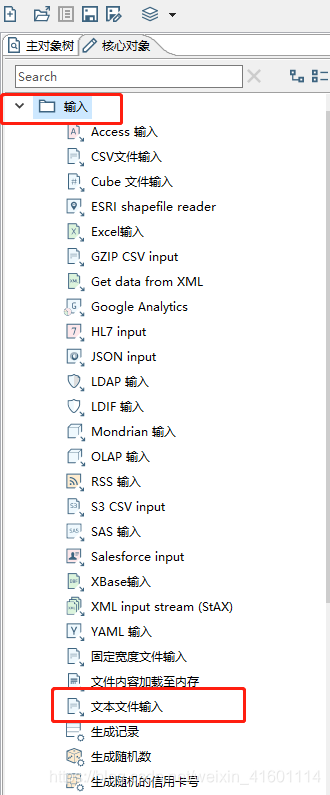
在输入目录中, 找到"文本文件输入",拖动到右侧编辑页面中
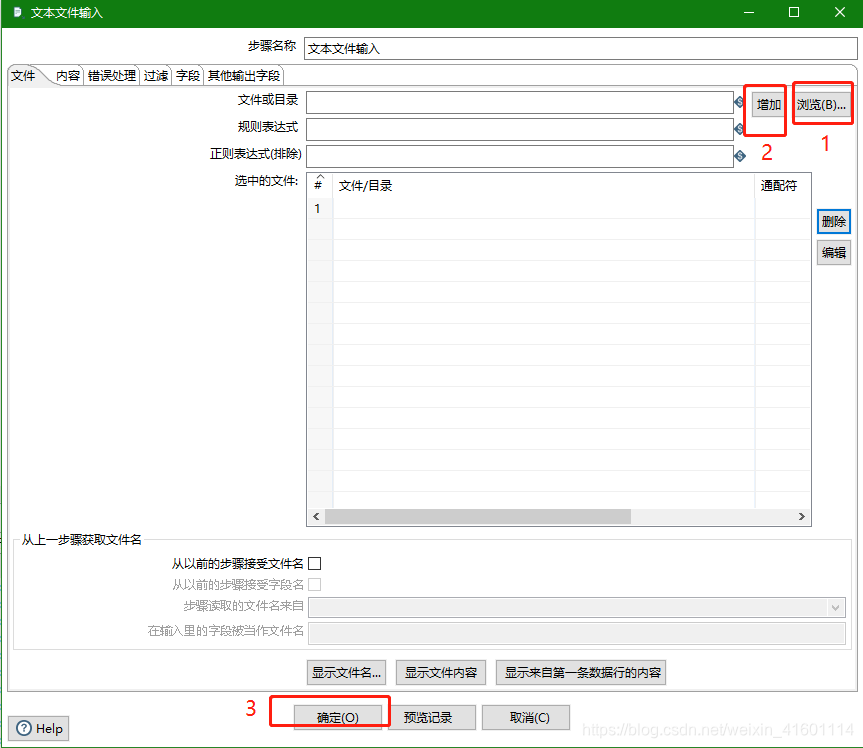
按住"shift"键 , 将两个图标连接起来, 双击图标对"文本文件输入"进行编辑, 点击"浏览"选择文本文件, 选择后点击"增加"即可添加到输入文件目录中,最后点击"确定"
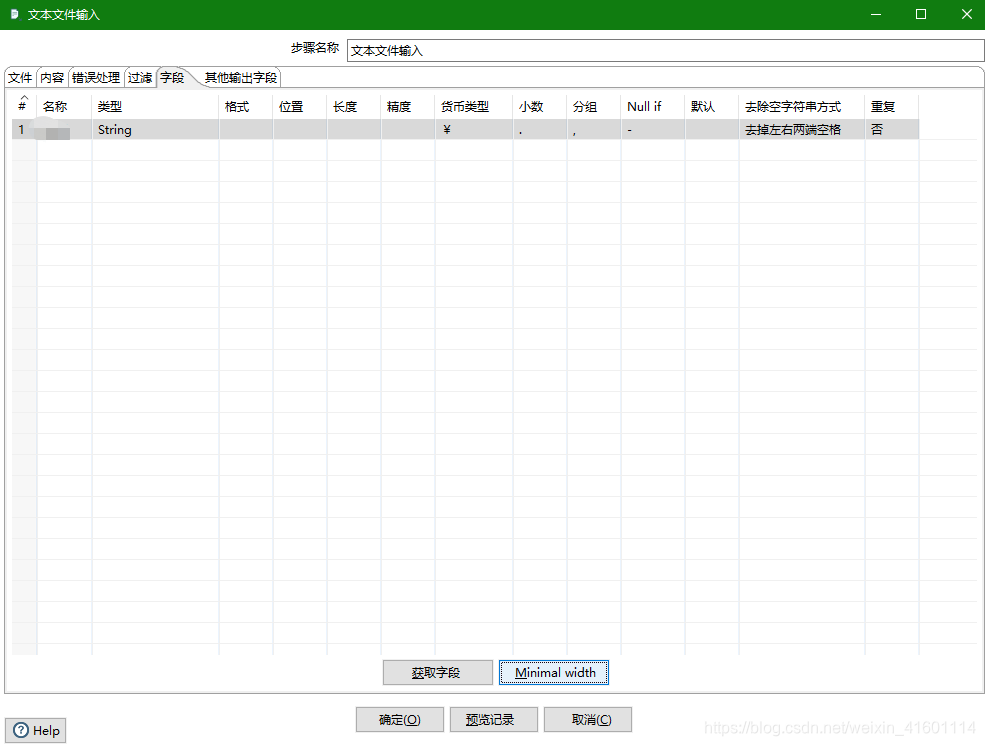
随后还需要对输入的数据的字段进行设置, 再次双击打开, 点击"字段" – > “获取字段” --> “Manimal width”,这里我只有一个字段, 处理完结果如下, 点击确定即可
对文件中数据进行格式化加工,输出json格式数据
在左侧目录中,选择"输出" --> "JSON output"输出,双击打开设置页面
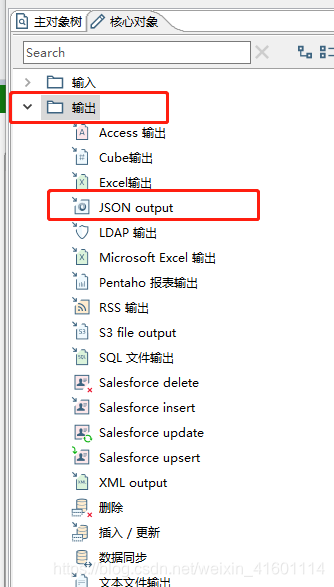
目前kettle自带的json Output 可以支持三种输出模式
- 输出json字符串的值
- 以json格式写入到文件
- 输出json格式的值,同时写入数据到指定文件
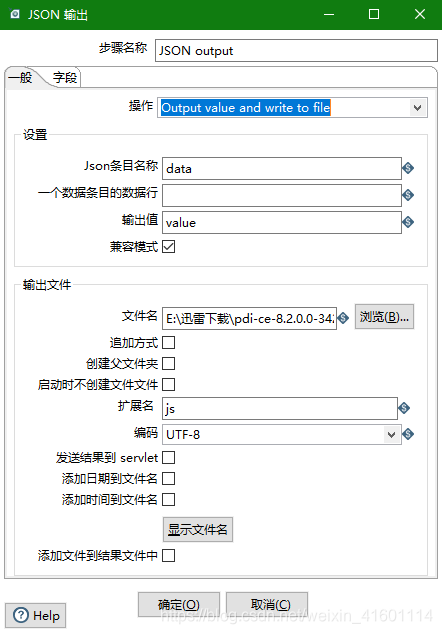
在操作中可以设置应该如何输出, 是只需要输出值? 还是需要写入到文件? 还是需要既输出值又需要写入到文件?
设置中:
- Json条目名称, 这个是用来配置生成的json数据的键的, 可参考下面的json格式, 这里默认是data
- 一个数据条目的数据行:用来配置data中有多少个json串,如果设置为不为0的数, 那么就会生成多个文件,每个文件中的json有指定数量的子json串,如果不设置值, 所有数据都会在同一个文件中
- 输出值: 生成json串在后面使用时如何调用, 这里配置的是变量字段的名称
- 兼容模式没啥大用, 影响不大
- 文件名: 如果设置为写入到文件或者既输出值又写入到文件, 那么需要在这里指定输出位置和文件名
- 扩展名:在这里指定文件的类型, 常用的也就是js和txt
但是存在一个问题就是我们需要写入kafka中, logstash对kafka中的topic进行读取,这时kafka中topic的每条记录都应该是json格式,例如
{
"name":"tomcat"}
而kettle中自带json Output插件输出的json格式为:
"{""data"":[{""pwd"":""aol.com""},{""pwd"":""mail.ru""},{""pwd"":""mail.ru""},{""pwd"":""plews.com""},{""pwd"":""mail.ru""},{""pwd"":""rambler.ru""},{""pwd"":""aol.com""},{""pwd"":""gmail.com""},{""pwd"":""gmail.com""},{""pwd"":""hotmail.com""}]}"
这明显不是我们要求的样子啊,哪来那么多的引号啊???
然后看一下使用json Output的输出到文件的效果,这里可以设置生成文件类型为js
这时
输出到js文件中格式是:
{
"data":[{
"pwd":"aol.com"},{
"pwd":"mail.ru"},{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1513
1513





 到【灌水乐园】发言
到【灌水乐园】发言







