







 通过对2013年至2018年美国枪支暴力事件数据的分析,本研究揭示了枪击事件的主要特征,包括使用的枪支类型、地区分布、年度趋势以及地点统计。此外,采用ARMA模型预测了未来枪支暴力事件的趋势。
通过对2013年至2018年美国枪支暴力事件数据的分析,本研究揭示了枪击事件的主要特征,包括使用的枪支类型、地区分布、年度趋势以及地点统计。此外,采用ARMA模型预测了未来枪支暴力事件的趋势。
Kaggle(Gun Violence Data)—美国枪支暴力事件分析(1)
数据来源为kaggle:https://www.kaggle.com/jameslko/gun-violence-data
主要分析13-18年美国枪支暴力事件的特征,以及使用时间序列预测下一年枪支暴力事件发生数量。
主要用到以下数据包
Basemap是python中一个利用地图的库
plotly是开挂的作图神器,可以供js, python, R, DB等使用
Seaborn是基于matplotlib的python数据可视化库,提供更高层次的API封装,使用起来更加方便快捷。
Fbprophet :facebook开源的时间序列预测框架prophet,目前支持R语言和python语言。托管在github上:https://github.com/facebookincubator/prophet。
wordcloud 生成词云
nltk.corpus 自带词袋中的停用词表去英文停用词
导入数据包
#数据基础操作
import pandas as pd # package for high-performance, easy-to-use data structures and data analysis
import numpy as np # fundamental package for scientific computing with Python
#画图
import matplotlib
import matplotlib.pyplot as plt # for plotting
import seaborn as sns # for making plots with seaborn
color = sns.color_palette()
from plotly.offline import init_notebook_mode, iplot,plot
init_notebook_mode(connected=True)
import plotly.graph_objs as go
import squarify
from numpy import array
from matplotlib import cm
'''
数据处理包
'''
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
from nltk.corpus import stopwords
from textblob import TextBlob
import datetime as dt
import warnings
import string
import time
stop_words = list(set(stopwords.words('english')))
warnings.filterwarnings('ignore')
punctuation = string.punctuation查看数据
df=pd.read_csv('gun-violence-data_01-2013_03-2018.csv',parse_dates = ['date'])
df.head()
数据集维度
#数据集维度
df.shape
#(239677, 29)
数据为空的数量
#数据为空的数量
df.isnull().sum()

可以看出某些特征中空值特别多,但我们后面又没有用到,所以就不管它了。
数据预处理
#增加特征
# Create some additional features
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['monthday'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday
df['loss'] = df['n_killed'] + df['n_injured']
try :
df.drop(['incident_id', 'incident_url', 'source_url', 'incident_url_fields_missing', 'sources','participant_name'], axis=1, inplace=True)
#去掉2013年数据
df=df.loc[df['date'].dt.year!=2013]
except :
print('process finish')
df.head()
将时间分成年、月、日,并把受伤和死亡人数求和,方便后面的运算。因为在后面的分析中还发现2013年数据特别少,直觉去掉13年数据后进行分析 :)
一、数据分析
1.1暴乱冲突中使用过哪些枪支?
df['gun_type_parsed'] = df['gun_type'].fillna('0:Unknown')
gt = df.groupby(by=['gun_type_parsed']).agg({'n_killed': 'sum', 'n_injured' : 'sum', 'state' : 'count'}).reset_index().rename(columns={'state':'count'})
results = {}
for i, each in gt.iterrows():
wrds = each['gun_type_parsed'].split("||")
for wrd in wrds:
if "Unknown" in wrd:
continue
wrd = wrd.replace("::",":").replace("|1","")
gtype = wrd.split(":")[1]
if gtype not in results:
results[gtype] = {'killed' : 0, 'injured' : 0, 'used' : 0}
results[gtype]['killed'] += each['n_killed']
results[gtype]['injured'] += each['n_injured']
results[gtype]['used'] += each['count']
gun_names = list(results.keys())
used = [each['used'] for each in list(results.values())]
killed = [each['killed'] for each in list(results.values())]
injured = [each['injured'] for each in list(results.values())]
danger = []
for i, x in enumerate(used):
danger.append((killed[i] + injured[i]) / x)
trace1 = go.Bar(x=gun_names, y=used, name='SF Zoo', orientation = 'v',
marker = dict(color = '#EEE8AA',
line = dict(color = '#EEE8AA', width = 1) ))
data = [trace1]
layout = dict(height=400, title='Which guns have been used?', legend=dict(orientation="h"));
fig = go.Figure(data=data, layout=layout)
iplot(fig, filename='枪支使用情况统计')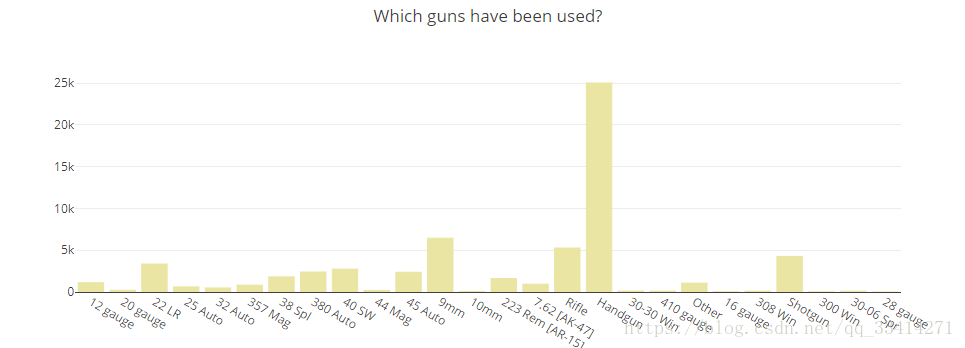
可以发现,手枪在枪击事件中用的最多,每种枪的使用频率也清晰可见。
1.2不同地区枪支暴力事件
#时间格式的转换
df_year=df.groupby(['year'])['n_killed','n_injured'].agg('sum')
states_df = df['state'].value_counts()
statesdf = pd.DataFrame()
statesdf['state'] = states_df.index
statesdf['counts'] = states_df.values
scl = [[0.0, 'rgb(242,240,247)'],[0.2, 'rgb(218,218,235)'],[0.4, 'rgb(188,189,220)'],\
[0.6, 'rgb(158,154,200)'],[0.8, 'rgb(117,107,177)'],[1.0, 'rgb(84,39,143)']]
state_to_code = {'District of Columbia' : 'dc','Mississippi': 'MS', 'Oklahoma': 'OK', 'Delaware': 'DE', 'Minnesota': 'MN', 'Illinois': 'IL', 'Arkansas': 'AR', 'New Mexico': 'NM', 'Indiana': 'IN', 'Maryland': 'MD', 'Louisiana': 'LA', 'Idaho': 'ID', 'Wyoming': 'WY', 'Tennessee': 'TN', 'Arizona': 'AZ', 'Iowa': 'IA', 'Michigan': 'MI', 'Kansas': 'KS', 'Utah': 'UT', 'Virginia': 'VA', 'Oregon': 'OR', 'Connecticut': 'CT', 'Montana': 'MT', 'California': 'CA', 'Massachusetts': 'MA', 'West Virginia': 'WV', 'South Carolina': 'SC', 'New Hampshire': 'NH', 'Wisconsin': 'WI', 'Vermont': 'VT', 'Georgia': 'GA', 'North Dakota': 'ND', 'Pennsylvania': 'PA', 'Florida': 'FL', 'Alaska': 'AK', 'Kentucky': 'KY', 'Hawaii': 'HI', 'Nebraska': 'NE', 'Missouri': 'MO', 'Ohio': 'OH', 'Alabama': 'AL', 'Rhode Island': 'RI', 'South Dakota': 'SD', 'Colorado': 'CO', 'New Jersey': 'NJ', 'Washington': 'WA', 'North Carolina': 'NC', 'New York': 'NY', 'Texas': 'TX', 'Nevada': 'NV', 'Maine': 'ME'}
statesdf['state_code'] = statesdf['state'].apply(lambda x : state_to_code[x])
data = [ dict(
type='choropleth',
colorscale = scl,
autocolorscale = False,
locations = statesdf['state_code'],
z = statesdf['counts'],
locationmode = 'USA-states',
text = statesdf['state'],
marker = dict(
line = dict (
color = 'rgb(255,255,255)',
width = 2
) ),
colorbar = dict(
title = "Gun Violence Incidents")
) ]
layout = dict(
title = 'State wise number of Gun Violence Incidents',
geo = dict(
scope='usa',
projection=dict( type='albers usa' ),
showlakes = True,
lakecolor = 'rgb(255, 255, 255)'),
)
fig = dict( data=data, layout=layout )
iplot( fig, filename='不同地区枪支暴力事件' )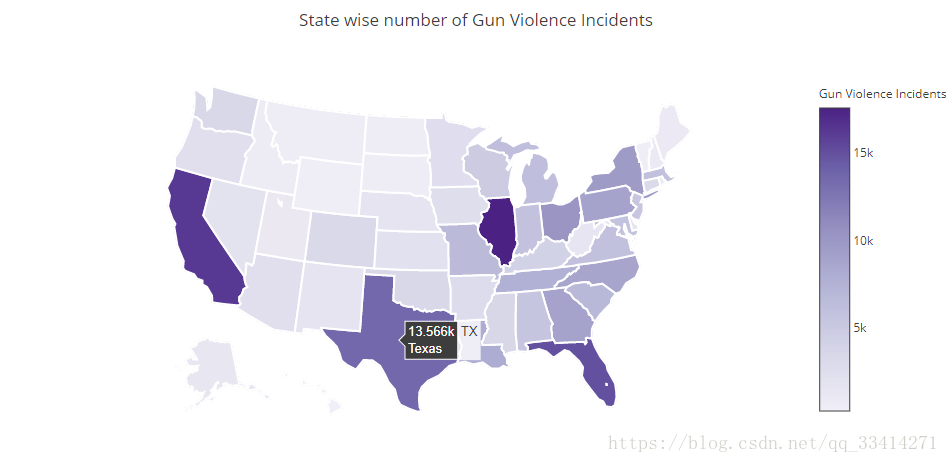
可以清晰的看到哪个州发生枪击暴力事件的数量最多
1.3枪支发生年份统计
df_year.head(1)
df_year.plot(figsize=(10,8))
plt.show()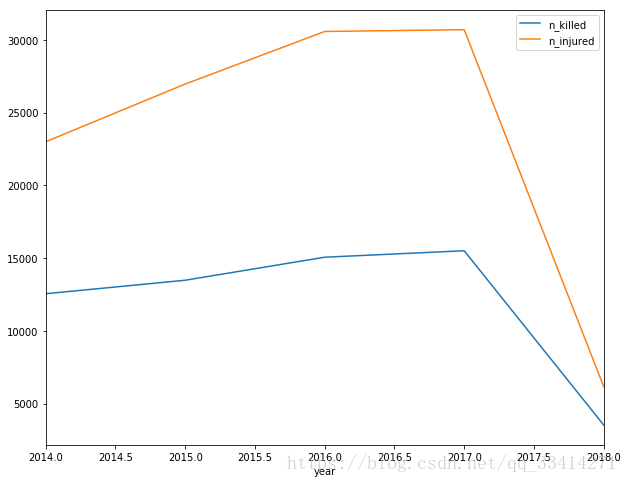
1.4枪支暴力冲突数量最多的前20个州
temp = df["state"].value_counts().head(20)
#temp.iplot(kind='bar', xTitle = 'State name', yTitle = "No. of incidents", title = 'Top 20 States with highest number of Gun Violence',color="Red")trace1
trace_top20=go.Bar(x=temp.index, y=temp.values)
data=[trace_top20]
iplot(data,filename='枪支暴力冲突数量最多的前20个州')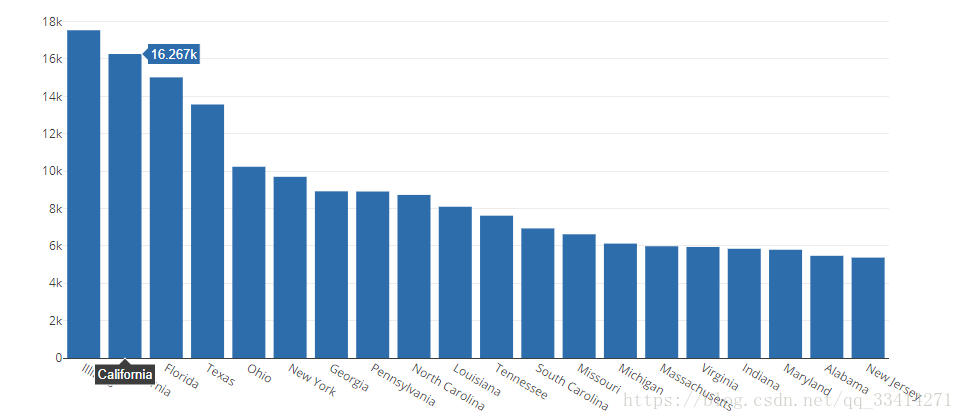
此处去掉了13年数据
1.5每个州在枪击事件中受伤+死亡人数统计
df['loss'] = df['n_killed'] + df['n_injured']
statdf = df.reset_index().groupby(by=['state']).agg({'loss':'sum', 'year':'count'}).rename(columns={'year':'count'})
statdf['state'] = statdf.index
trace1 = go.Bar(
x=statdf['state'],
y=statdf['count'],
name='Count of Incidents',
marker=dict(color='rgb(255,10,225)'),
opacity=0.6
)
trace2 = go.Bar(
x=statdf['state'],
y=statdf['loss'],
name='Total Loss',
marker=dict(color='rgb(58,22,225)'),
opacity=0.6
)
data = [trace1, trace2]
layout = go.Layout(
barmode='group',
margin=dict(b=150),
legend=dict(dict(x=-.1, y=1.2)),
title = 'State wise number of Gun Violence Incidents and Total Loss',
)
fig = go.Figure(data=data, layout=layout)
iplot(fig, filename='grouped-bar')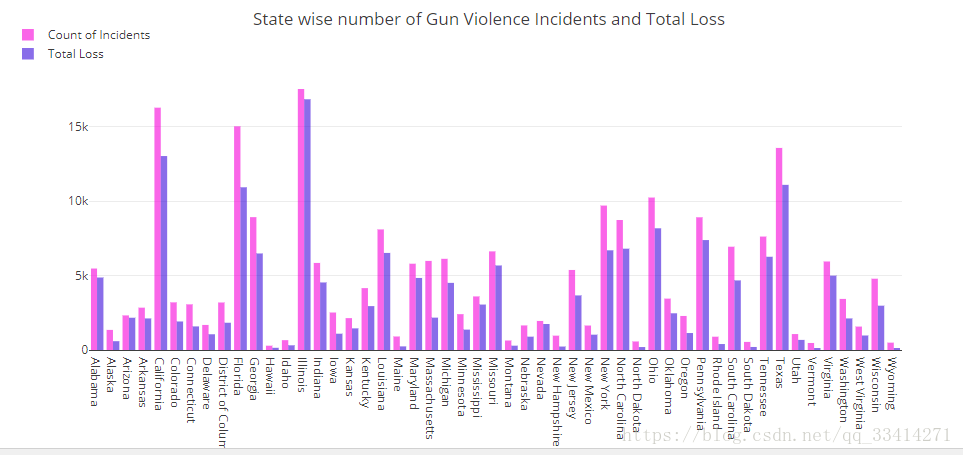
先跳过1.6哈~详细的可以看github上的源码哈,地址在文章末尾!
1.7枪击事件发生地点统计
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
mask = np.array(Image.open('gun2.jpg'))
txt = " ".join(df['location_description'].dropna())
wc = WordCloud(mask=mask, max_words=1200, stopwords=STOPWORDS, colormap='copper', background_color='White').generate(txt)
plt.figure(figsize=(16,18))
plt.imshow(wc)
plt.axis('off')
plt.title('');
plt.show()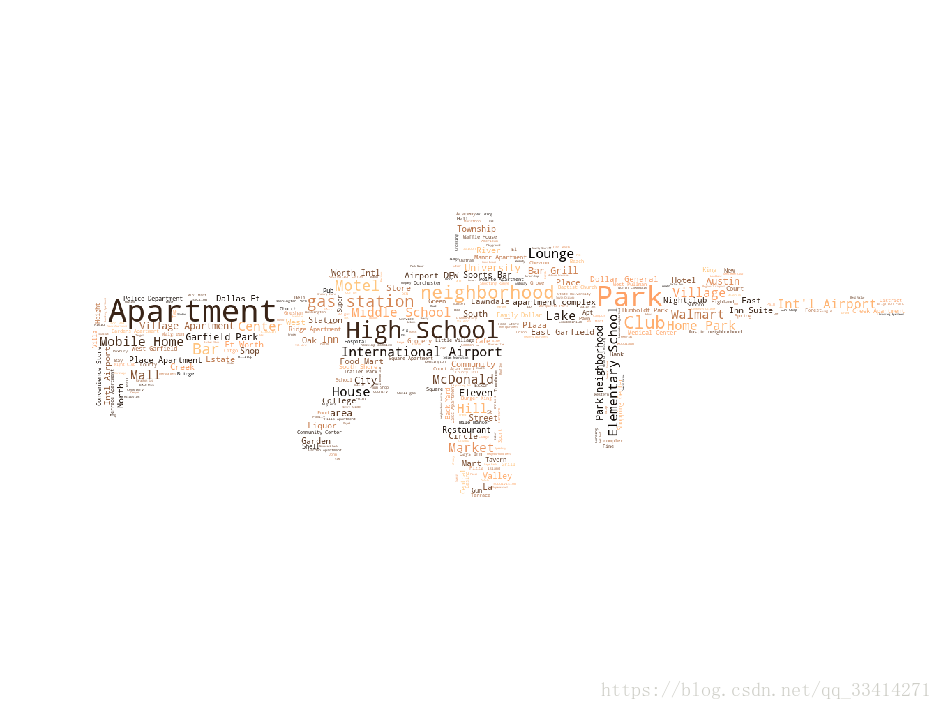
枪击事件多发在公寓,公园,高校,机场等地,这是一个很有意思的功能, 主要使用WordCloud, STOPWORDS两个库来表示出现频率最高的地点,词云的展示方式也比较好玩。
这里先跳过分析的一部分,详细代码看下面github链接哦
二、数据挖掘
2.1预测有多少枪支暴力仍然会发生
先打印2018年已有的数据的时间序列
df_18=df.ix[df['year']==2018]
df_ts=df_18[['n_killed','date']]
df_ts.index=df_18['date']
df_ts['n_killed'].plot(figsize=(15,6), color="green")
plt.xlabel('Year')
plt.ylabel('No. of Deaths')
plt.title("Death due to Gun Violence Time-Series Visualization")
plt.show()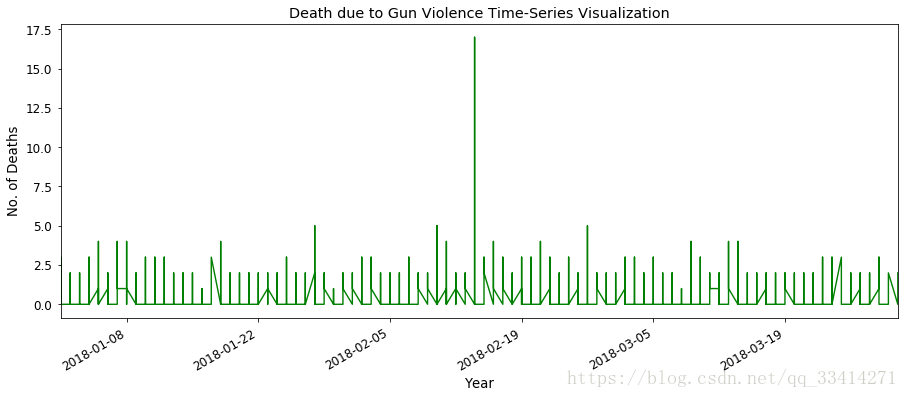
使用facebook开源的fbprophet框架中的Prophet来进行时间序列分析,还可以显示分析的周效应等细节信息,是一个非常好用的框架。
from fbprophet import Prophet
sns.set(font_scale=1)
df_date_index = df_18[['date','n_killed']]
df_date_index = df_date_index.set_index('date')
df_prophet = df_date_index.copy()
df_prophet.reset_index(drop=False,inplace=True)
df_prophet.columns = ['ds','y']
m = Prophet()
m.fit(df_prophet)
future = m.make_future_dataframe(periods=365,freq='D')
forecast = m.predict(future)
fig = m.plot(forecast)
plt.show()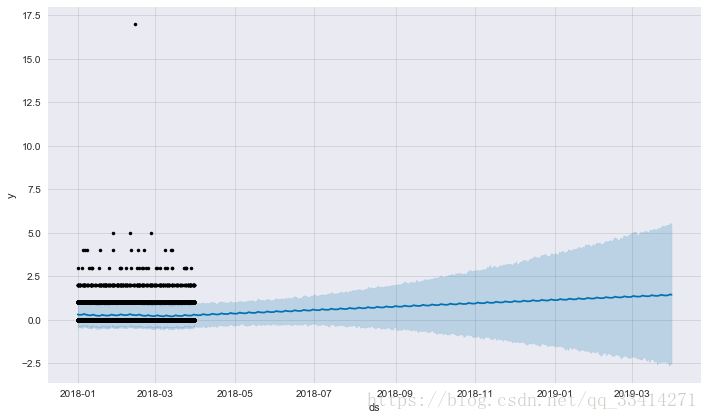
打印预测的详细趋势
m.plot_components(forecast);
plt.show()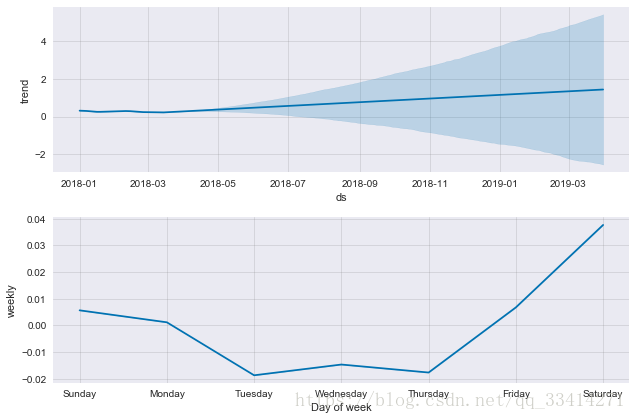
预计2018年的枪击事件数量仍然呈上升趋势,具体在星期五、星期六有较强的上升趋势,应注意防范
可能会出现的问题及解决方案
1.pip install XXX报错:
parse() got an unexpected keyword argument 'transport_encoding'解决:
conda install pip2.No matching distribution found for mpl_toolkits
解决:
pip install --upgrade matplotlib3.下载停用词表出错
Resource 'corpora/stopwords.zip/stopwords/' not found. Please
use the NLTK Downloader to obtain the resource: >>>
nltk.download()
Searched in:
- 'C:\\Users\\liang/nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'j:\\Anaconda3\\nltk_data'
- 'j:\\Anaconda3\\lib\\nltk_data'
- 'C:\\Users\\liang\\AppData\\Roaming\\nltk_data'解决方案:
nltk.download("stopwords")成功提示:
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\liang\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\stopwords.zip.
Out[7]:
True4.去掉DataFrame中某个特征里面符合某条件的数据(如去掉“年份”中为“2013”的数据)
解决方法:
使用df=df.loc[年份=2013]
注:df.iloc[]可以很方便的截取要是用哪些数据
如df.iloc[:, 1:] 表示使用所有行,第一列以后的数据
github源码地址:
https://github.com/LIANGQINGYUAN/GunViolence_DataMining
Kaggle(Gun Violence Data)—美国枪支暴力事件分析(2)
继上次分析之后,这次打算用详细的时间序列算法预测,我们使用ARMA时间序列模型作为预测,选取17年数据和18年1月和2月数据作为训练,预测18年3月1日,3月2日及3月3日数据。
话不多说,直接整吧。
1.基本数据整理
#-*- coding: utf-8 -*-
#arima时序模型
import pandas as pd
#时序图
import matplotlib.pyplot as plt
from plotly.offline import init_notebook_mode, iplot,plot
init_notebook_mode(connected=True)
import plotly.graph_objs as go
df=pd.read_csv('gun-violence-data_01-2013_03-2018.csv')
df=df[['date','n_killed']]
df.to_csv('data_nkilled.csv')2.选取所需数据
discfile = 'data_nkilled.csv'
forecastnum = 5
#读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_csv(discfile)
data=data.iloc[:,1:]
#处理数据,只需要2018年的数据
data17=data[data['date'].astype('datetime64').dt.year==2017 ]
data18=data[data['date'].astype('datetime64').dt.year==2018 ]
data2=data18[data18['date'].astype('datetime64').dt.month<=2]
#data3=data[data['date'].astype('datetime64').dt.month==3]
#data3=data3[data3['date'].astype('datetime64').dt.day>15]
mydata=pd.DataFrame()
mydata=mydata.append(data17)
mydata=mydata.append(data2)
#mydata=data
#mydata.head()
temp=mydata.groupby('date').agg({'n_killed' : 'sum'})
#temp.head()选取17年数据和18年1月和2月数据作为训练
显示真实的时间序列
trace1=go.Bar(x=temp.index,y=temp['n_killed'])
data = [trace1]
layout =dict(height=400, title='2017-2018年被杀人数统计', legend=dict(orientation="h"));
fig = go.Figure(data=data, layout=layout)
iplot(fig)
上图为已有真实数据的分布
3.自相关图及检验
自相关图
#自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(temp)
plt.show()
上图为自相关性检验图,上图展示了明显的1阶拖尾效应,可以初步的判断序列不存在自相关性。
ADF检验
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(temp['n_killed']))原始序列的ADF检验结果为:
(-3.0443905852697957,
0.03095172945803373,
14,
408,
{‘1%’: -3.446479704252724,
‘5%’: -2.8686500930967354,
‘10%’: -2.5705574627547096},
2874.7803552969235)
ADF检验结果显示p=0.03<0.05,说明不存在显著自相关性
偏自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(temp)
plt.show() #偏自相关图
由图中可明显看出该序列的偏自相关图有明显1阶拖尾效应。
白噪声检验
#白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(temp, lags=1)) #返回统计量和p值序列的白噪声检验结果为: (array([8.36275837]), array([0.00382989]))
可见,p值远小于0.05,说明该序列为平稳的非白噪声检验,有进一步预测的必要和依据。
4.预测
由该序列的自相关图和偏自相关图都为1阶,且是平稳的非白噪声序列可以确定使用ARMA模型,且模型参数p=1,q=1.
from statsmodels.tsa.arima_model import ARMA
temp=temp.astype(float)
model = ARMA(temp, (1,1,1)).fit() #建立ARIMA(0, 1, 1)模型
model.summary2() #给出一份模型报告
model.forecast(3) #作为期5天的预测,返回预测结果、标准误差、置信区间。
可见真实值都落在了置信区间(5%)以内,可以推断我们预测的因枪击事件死亡的人数存在合理性,但枪击还是属于突发性不确定性事件,随着时间的推移,预测准确性会明显下滑。
github项目地址:
https://github.com/LIANGQINGYUAN/GunViolence_DataMining
转载自:土豆洋芋山药蛋 https://blog.youkuaiyun.com/qq_33414271/article/details/80587856

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









