



缓存失效算法用于在缓存空间不足时,选择合适的对象进行淘汰。优秀的算法能显著提高缓存命中率。常见的算法包括FIFO、LRU、LFU以及Caffeine中的Window TinyLFU算法。
FIFO
FIFO(先进先出)是最简单直观的缓存淘汰算法,其实现原理与队列相同:
- 新数据插入队列尾部
- 淘汰队列头部的数据
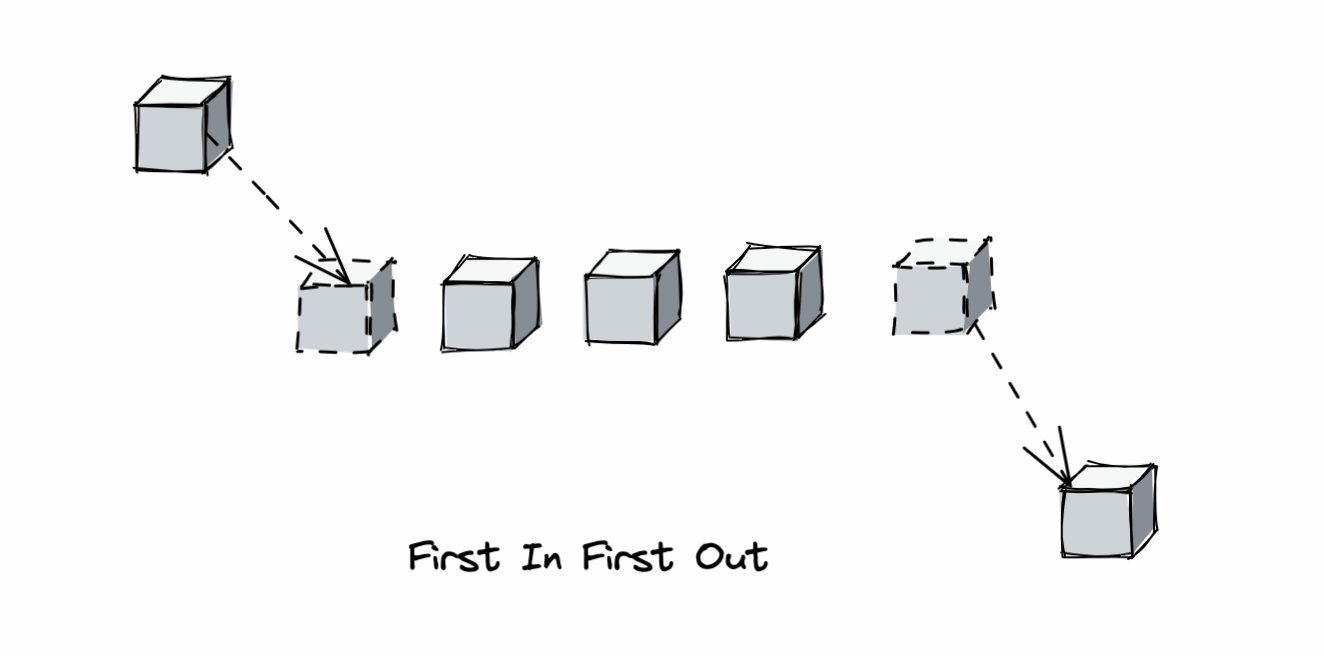
该算法基于假设:最早进入缓存的数据未来被访问的概率较低。
LRU & LFU
- LRU:基于最近访问时间,淘汰最久未使用的数据,通过链表维护访问顺序
- LFU:基于访问频率,淘汰使用最少的数据,通过引用计数实现 二者各有优势:LRU适合时间局部性强的场景,LFU适合访问频率差异大的场景
W-TinyLFU
虽然LFU能提供最佳的缓存命中率,但它存在几个主要缺陷:
- 需要为每个记录项维护频率信息,每次访问都需更新,导致存储所有key及其频次需要大量空间;
- 当数据访问模式随时间变化时,LFU无法动态调整频率信息,可能导致早期高频访问记录持续占用缓存,而后期高频记录无法命中;
- 新加入缓存的元素因初始频率低,可能立即被淘汰。
其中第一点缺陷尤为严重,使得LFU在实际中很少被采用。相比之下,LRU实现简单且内存占用低,但无法反映访问频率。LFU通常需要较大存储空间才能保证良好的缓存命中率。
W-TinyLFU是一种高效缓存淘汰算法,作为TinyLFU的改进版本,专门用于处理大规模缓存系统的淘汰问题。它采用基于窗口的近似最少使用策略,能够根据数据访问模式动态调整淘汰机制。W-TinyLFU融合了LRU和LFU的优势,兼具高命中率和低内存占用的特点。
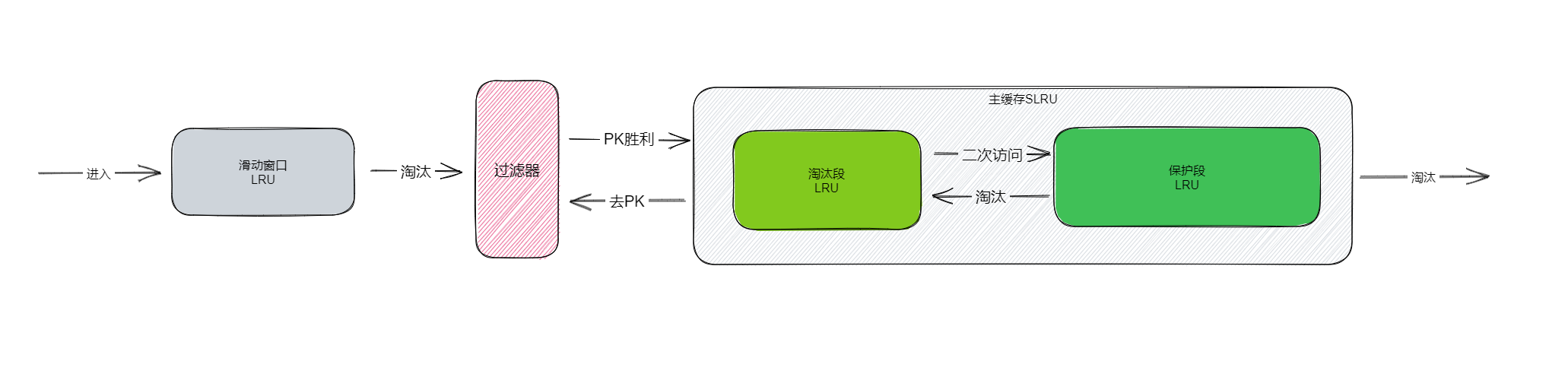
该算法由三个核心组件构成:
- 窗口缓存
- 过滤器
- 主缓存
窗口缓存采用LRU机制,为新元素提供积累访问频率的机会,避免因初始频率过低而被直接淘汰。
主缓存则采用SLRU策略:元素首先在窗口缓存暂存,当被窗口缓存淘汰时,会与主缓存中最易被淘汰的元素进行频率比较,只有胜出者才能进入主缓存。
过滤器用于数据淘汰决策

















 3714
3714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









