




 本文介绍如何使用Python装饰器提升代码效率,包括日志记录、斐波那契数列高速缓存及版本号比较等实战应用。
本文介绍如何使用Python装饰器提升代码效率,包括日志记录、斐波那契数列高速缓存及版本号比较等实战应用。
Question1 记录日志装饰器练习题
好的日志对一个软件的重要性是显而易见的。如果函数的入口都要写一行代码来记
录日志,这种方式实在是太低效了。
那么请你创建一个装饰器, 功能实现函数运行时自动产生日志记录。
日志格式如下:
程序运行时间 主机短名 程序名称: 函数[%s]运行结果为[%s]
产生的日志文件并不直接显示在屏幕上, 而是保存在 file.log 文件中, 便于后期
软件运行结果的分析.
代码如下:
import os
import time
import sys
import socket
import json
# 装饰器: 用来添加日志信息的
def add_log(fun):
"""
May 26 09:50:14 foundation0 systemd: Removed slice user-0.slice.*args
ar
"""
def wrapper(*args, **kwargs): # args=(1, 2) =====> *args=1 2 #
# 获取被装饰的函数的返回值
result = fun(*args, **kwargs) # add(*args) ====> add(1, 2)
# 返回当前的字符串格式时间
now_time = time.ctime()
# 获取主机名 nodename='foundation0.ilt.example.com'
hostname = socket.gethostname()
# 运行的程序
process_full_name = sys.argv[0]
process_name = os.path.split(process_full_name)[-1]
# 日志内容
# info = "正在运行程序: " + str(fun)
# 获取函数名: 函数名.__name__
info = "函数[%s]的运行结果为%s" % (fun.__name__, result)
global log
log = " ".join([now_time, hostname, process_name, info])
print(log)
return result
return wrapper
@add_log # 语法糖====music = add_log(music)
def music():
time.sleep(1)
print("正在听音乐.....")
@add_log
def add(x, y):
return x + y
@add_log
def roll(name, age, **kwargs):
print(name, age, kwargs)
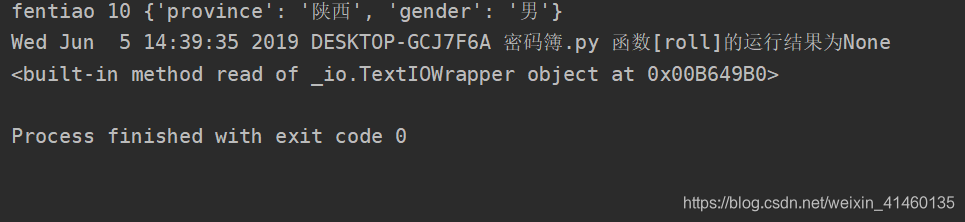
roll(name='fentiao', age=10, province='陕西', gender='男')
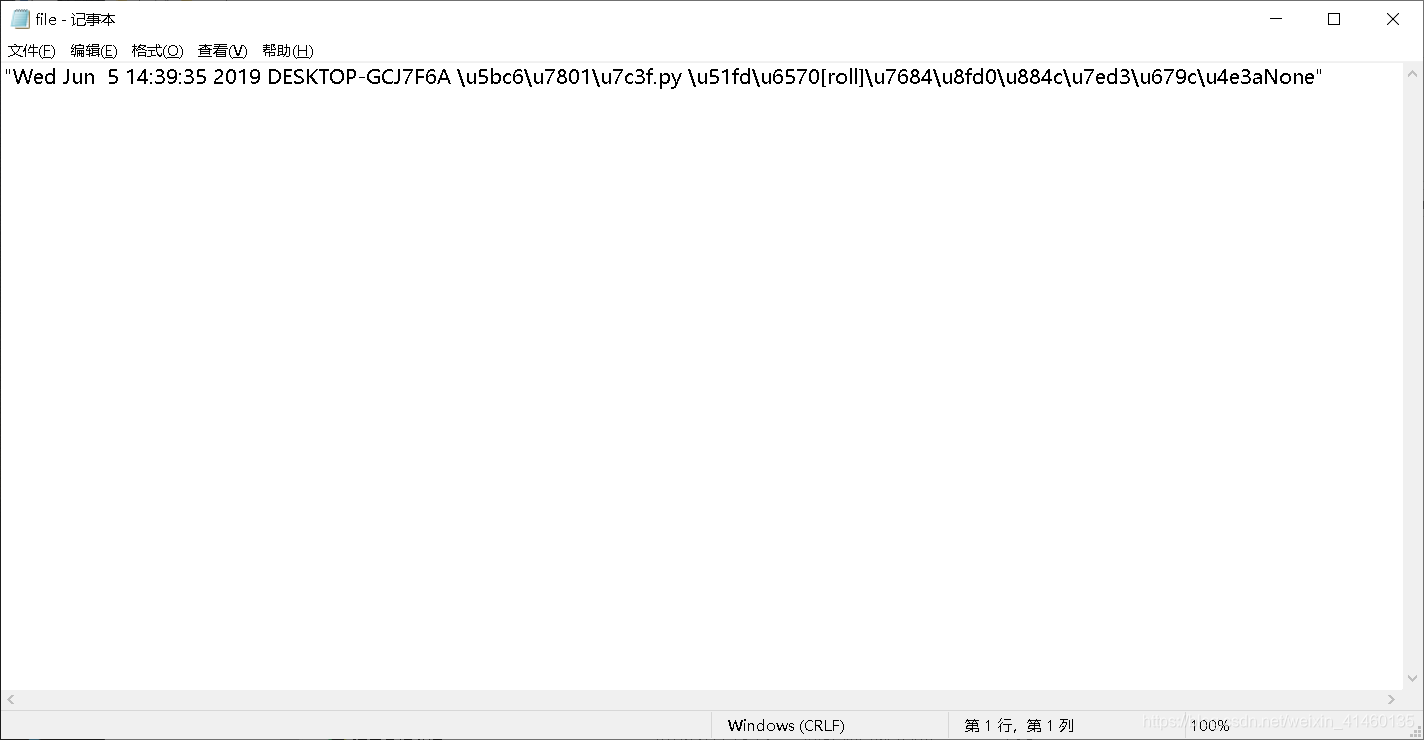
with open('file.log', 'w+') as f:
new_log = json.dumps(log)
f.write(new_log)
print(f.read)
运行结果:
Question2斐波那契数列的装饰器练习: 实现高速缓存递归
在数学上,费波那契数列是以递归的方法来定义:
用文字来说,就是费波那契数列由 0 和 1 开始,之后的费波那契系数就是由之前的两数相
加而得出。首几个费波那契系数是:
0,1,1,2,3,5,8,13,21,34,55,89,144,233……(OEIS 中的数列 A000045)
装饰器 1: 添加高速缓存的装饰器 num_cache
如果第一次计算 F(5) = F(4) + F(3) = 5
第二次计算 F(6) = F(5) + F(4)
显然 F(5)已经计算过了, F(4)也已经计算了, 我们可否添加一个装饰器, 专门用
来存储费波那契数列已经计算过的缓存, 后期计算时, 判断缓存中是否已经计算过了, 如
果计算过,直接用缓存中的计算结果. 如果没有计算过, 则开始计算并将计算的结果保存在缓
存中.
装饰器 2: 程序运行计时器的装饰器 timeit
该装饰器用来测试有无高速缓存求斐波那契数列, 它们两者运行的时间效率高低.
代码如下:
def num_cache(func):
cache = {}
def wrap(*args):
'''
判断args是否有缓存在cache中,有即返回。
:param args:
:return:
'''
if args not in cache:
cache[args] = func(*args)
return cache[args]
return wrap
@num_cache
def fibonacci(n):
if n <= 2:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
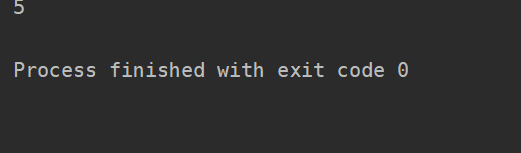
print(fibonacci(5))
结果如下:
Question3Leetcode 字符串练习题目: 比较版本号
比较两个版本号 version1 和 version2。
如果 version1 > version2 返回 1,如果 version1 < version2 返回 -1, 除此之外返回 0。
你可以假设版本字符串非空,并且只包含数字和 . 字符。
. 字符不代表小数点,而是用于分隔数字序列。
例如,2.5 不是“两个半”,也不是“差一半到三”,而是第二版中的第五个小版本。
你可以假设版本号的每一级的默认修订版号为 0。例如,版本号 3.4 的第一级(大版本)和第二级(小版本)修订号分别为 3 和 4。其第三级和第四级修订号均为 0。
示例 1:
输入: version1 = "0.1", version2 = "1.1"
输出: -1
示例 2:
输入: version1 = "1.0.1", version2 = "1"
输出: 1
示例 3:
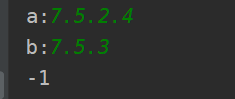
输入: version1 = "7.5.2.4", version2 = "7.5.3"
输出: -1
示例 4:
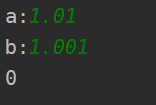
输入:version1 = "1.01", version2 = "1.001"
输出:0
解释:忽略前导零,“01” 和 “001” 表示相同的数字 “1”。
示例 5:
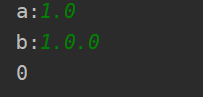
输入:version1 = "1.0", version2 = "1.0.0"
输出:0
解释:version1 没有第三级修订号,这意味着它的第三级修订号默认为 “0”。
代码如下:
def compare(a, b):
if len(a) == len(b):
if float(a) > float(b):
return 1
elif float(a) <float(b):
return -1
else:
return 0
elif len(a) != len(b):
# 获取版本字符串的组成部分
lena = len(a.split('.'))
lenb = len(b.split('.'))
# b比a长的时候补全a
a2 = a + '.0' * (lenb - lena)
b2 = b + '.0' * (lena - lenb)
for i in range(max(lena, lenb)): # 对每个部分进行比较,需要转化为整数进行比较
if int(a2.split('.')[i]) > int(b2.split('.')[i]):
return 1
elif int(a2.split('.')[i]) < int(b2.split('.')[i]):
return -1
elif i == max(lena, lenb)-1:
return 0
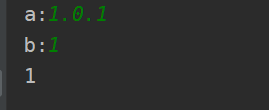
print(compare('3.8.0','3.8'))
截图如下:


















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









