




 Zookeeper采用Zab协议实现原子广播,确保数据一致性。Zab协议包含恢复模式(选主)和广播(同步)模式。在恢复模式中,选主过程保证了Zxid最大的epoch,并在多数follower支持下结束。广播模式类似两阶段提交,通过单调递增的zxid排序消息。Zookeeper遵循CAP定理,牺牲分区容错性以保证一致性和可用性。
Zookeeper采用Zab协议实现原子广播,确保数据一致性。Zab协议包含恢复模式(选主)和广播(同步)模式。在恢复模式中,选主过程保证了Zxid最大的epoch,并在多数follower支持下结束。广播模式类似两阶段提交,通过单调递增的zxid排序消息。Zookeeper遵循CAP定理,牺牲分区容错性以保证一致性和可用性。
1.Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步(数据最新,一致性)。
实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复(选主)模式和广播(同步)模式。
2.恢复(选主)模式:
2.1 服务启动、leader崩溃、leader失去了半数以上的支持,进入该模式。
生成选票,写着投给哪个server,那台 server 的 zxid 是什么。一开始的时候,所有机器都先把票投给自己,然后轮询集群中所有其他机器的选票,如果有其他机器的 zxid 大于自己,那么就把选票投给它,如果 zxid 相同就投给那个 serverid 最大的,这个过程一直持续到有个server得到了超过半数的机器的支持。
2.2 在出现分区的时候,如果 leader 在多数 follower 的一方,那么这半边正常,另外半边均不能读写,集群是正常的。
如果 leader 少数 follower 一方,那么leader会意识到没有多数follower的支持了,而多数的一方会选举出新的leader。
(这里牺牲了一定的分区容错性,例如5台机器,分为2、2、1三个区时)
2.3 选完leader以后,zk就进入状态同步过程。大多数server和leader的状态同步以后,恢复模式结束。
(选举过程中,特别是Zxid最大的机器挂掉时,可能牺牲一定的可用性?)
当有新的Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。同步结束后参与消息广播。
2.4 恢复阶段的保证:
① 绝不能遗忘已经被deliver的消息,若一条消息在一台机器上被deliver,那么该消息必须将在每台机器上deliver。
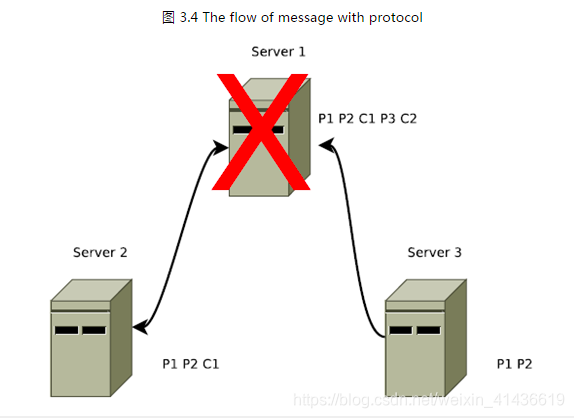
如下图,Server 1为leader,发起并只有自己收到Commit 2时崩溃了,C2已经被deliver,新leader绝不能将其遗忘。
 </
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









