







 本文介绍使用Spark处理网络日志并计算PV和UV的方法。首先进行数据清洗,然后利用Spark SQL进行聚合统计,最后将结果保存至MySQL数据库。
本文介绍使用Spark处理网络日志并计算PV和UV的方法。首先进行数据清洗,然后利用Spark SQL进行聚合统计,最后将结果保存至MySQL数据库。
这里我们先理解一下spark处理数据的流程,由于spark 有standalone,local,yarn等多种模式,每种模式都有不同之处,但是总体流程都是一样的,大致就是客户端向集群管理者提交作业,生成有向无环图,图中的内容包括分成几个stage,每个stage有几个task,每个task分别由哪个executor来执行,接下来的工作就是整个spark集群按照有向无环图的布置来进行,并得出结果。
下面我们举一个网络日志计算pv uv的实例,通过代码打成jar包的方式在 spark-submit执行,代码 具体实现以下功能:
1. 数据清洗,只保留date url 和guid
2.创建spark schema ,将rdd转换成dataframe,并创建临时表
3.使用sql 语句查询 uv pv
4.将结果保存到数据库中
package com.stanley.scala.objects
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.Row
object WebLog {
def main(args: Array[String]): Unit = {
//创建配置文件,选择yarn-clent模式
val conf=new SparkConf().setAppName("SparkTest").setMaster("yarn-client")
val sc =new SparkContext(conf)
//读取数据
val fileRdd=sc.textFile(args(0))
//ETL清洗数据
val weblogRdd=fileRdd.filter(_.length>0).map(line=>{
val arr=line.split("\t")
val url=arr(1)
val guid =arr(5)
val date=arr(17).substring(0,10)
(date,guid,url)
}).filter(_._3.length>0)
//建立sparksql
val sqlContext=new SQLContext(sc)
//建立schema
val schema=StructType(
List(
StructField("date",StringType,true),
StructField("guid",StringType,true),
StructField("url",StringType,true)
)
)
val rowRdd=weblogRdd.map(tuple=>Row(tuple._1,tuple._2,tuple._3))
val weblogDf=sqlContext.createDataFrame(rowRdd, schema)
//注册临时表
weblogDf.registerTempTable("webLog")
//创建sql 语句查询uv,pv
val uvSql="select count(*) pv,count(distinct(guid)) uv from webLog"
val uvpvDf=sqlContext.sql(uvSql)
uvpvDf.show()
//结果传入mysql
val url="jdbc:mysql://master:3306/test?user=root&password=123456"
import java.util.Properties
val properties=new Properties
uvpvDf.write.jdbc(url,"uvpv",properties)
//关闭资源
sc.stop()
}
}值得注意的是 由于数据量并不是很大,我们可以在spark-defaults.conf中设定分区数,来加快运行速度,如果不设置这个参数分区数可能会有200个会产生200个task
spark.sql.shuffle.partitions 10
接下来我们运行程序,先启动集群,并打开historyserver, 然后进入spark目录,属于spark-sumbit指令
./bin/spark-submit \
--class com.stanley.scala.objects.WebLog \
/opt/testfile/sparkTest.jar \
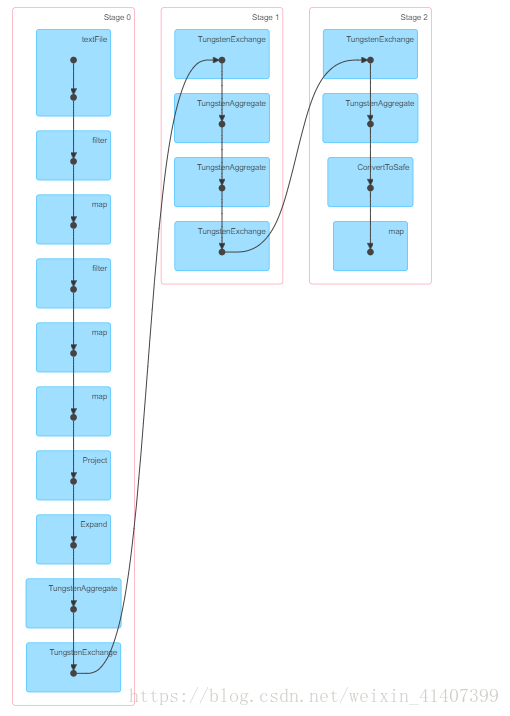
/input/2015082818这是可以通过 webUI看到有向无环图,一共分为三个阶段
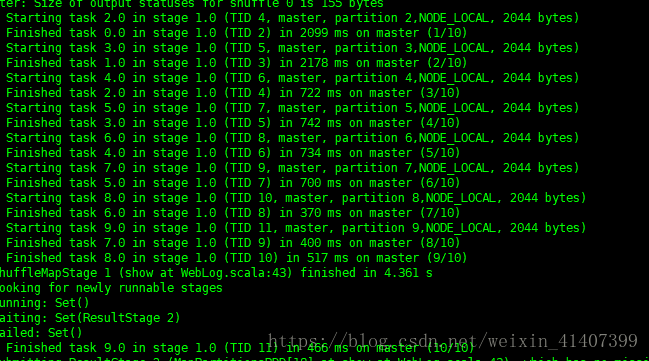
再查看以下日志,分区数也是我们设置的 10个
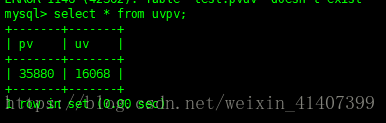
进入mysql 查看uvpv表已经存在

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









