






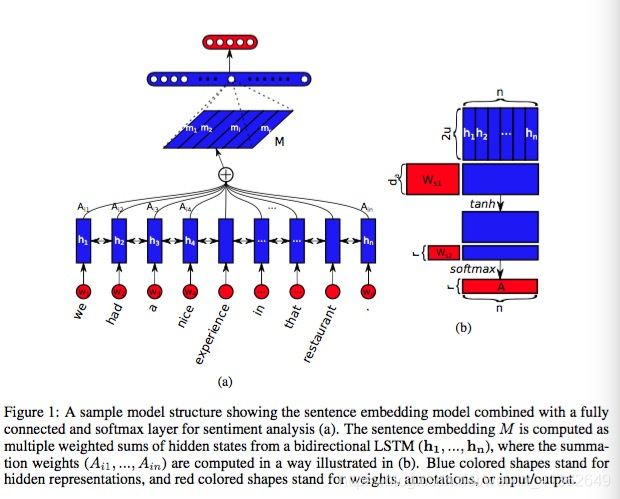
本文利用self-attention的方式去学习句子的embedding,表示为二维矩阵,而不是一个向量,矩阵中的每一行都表示句子中的不同部分。模型中使用了self-attention机制和一个特殊的regularization term


总结
以往论文中常用的句子表示为一维向量,但是这只能表达句子的一部分信息,为此作者提处一种self-attentive机制,并基于此机制,将句子表示为一个2维矩阵,使得句子的信息尽可能多的得到保留,同时为了使得句子的信息尽可能多的保留,即行与行之间尽可能差异化,作者使用了Frobenius范数惩罚项
参考连接:
https://www.jianshu.com/p/87108d836c63
https://blog.youkuaiyun.com/john_xyz/article/details/80650677
https://blog.youkuaiyun.com/guoyuhaoaaa/article/details/78701768

















 9363
9363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









