




 本文针对数据合并过程中出现的记录数量不匹配问题进行了探讨,通过排序、字段调整等手段解决了数据丢失的问题。
本文针对数据合并过程中出现的记录数量不匹配问题进行了探讨,通过排序、字段调整等手段解决了数据丢失的问题。
今天进行数据合并操作遇到这样一个问题:合并记录为207条、输出为206条

参考了其他人的文章 提供的结局思路
1.在操作db时,控制顺序,先delete,后insert,这样数据不会少
2.我猜测,一个修改的数据可能在判断是新增、修改、删除时,在旧数据源没有最快找到记录,就标记成new,后面在旧数据源找到一条数据,在新数据源中(已经过去的数据不考虑)没有找到,就标记成deleted
所以解决方法很简单,将新旧数据源都排序,这样得到了我想要的结果。
我做了四种尝试
1、更改新旧数据源
将新、旧数据源更改即可,并未解决。
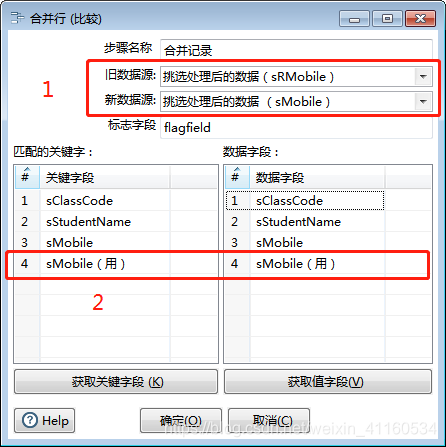
2、改变合并记录的字段设置(结合第一种成功)
新增其他过滤条件,结合第一种成功。
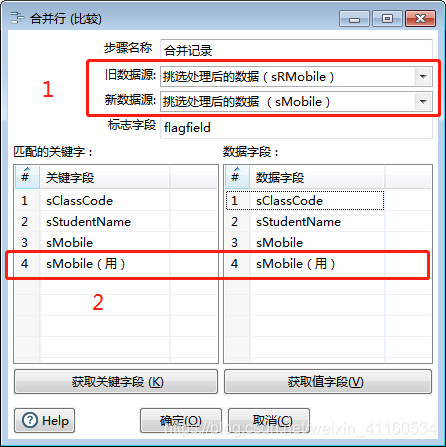
3、排序后合并记录
根据当中的字段sClassCode排序后,反而又少了3条。失败~
4、增加常数序列
增加常数序列后,无任何改变。
上述四种方法,单一很难有用,
结合两种或者多种就能够保持数据量不变。
具体原理我也不是很懂,求指教~~~(c243126035)

















 3127
3127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









