




 本文详细解析了fork函数的工作原理,包括其在父进程和子进程中的返回值差异、进程标识符的作用及获取方式,并介绍了进程状态标记及Linux内核中task_struct数据结构的内容。
本文详细解析了fork函数的工作原理,包括其在父进程和子进程中的返回值差异、进程标识符的作用及获取方式,并介绍了进程状态标记及Linux内核中task_struct数据结构的内容。
从经典函数fork()引出
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
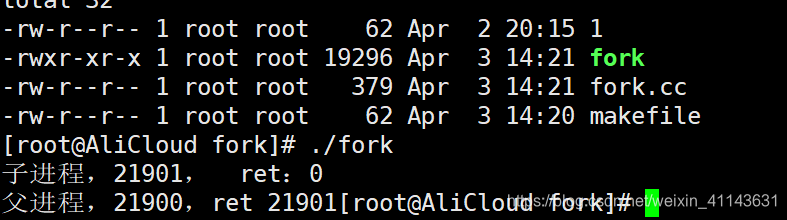
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,
fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id,
因为子进程没有子进程,所以其fpid为0.
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程。
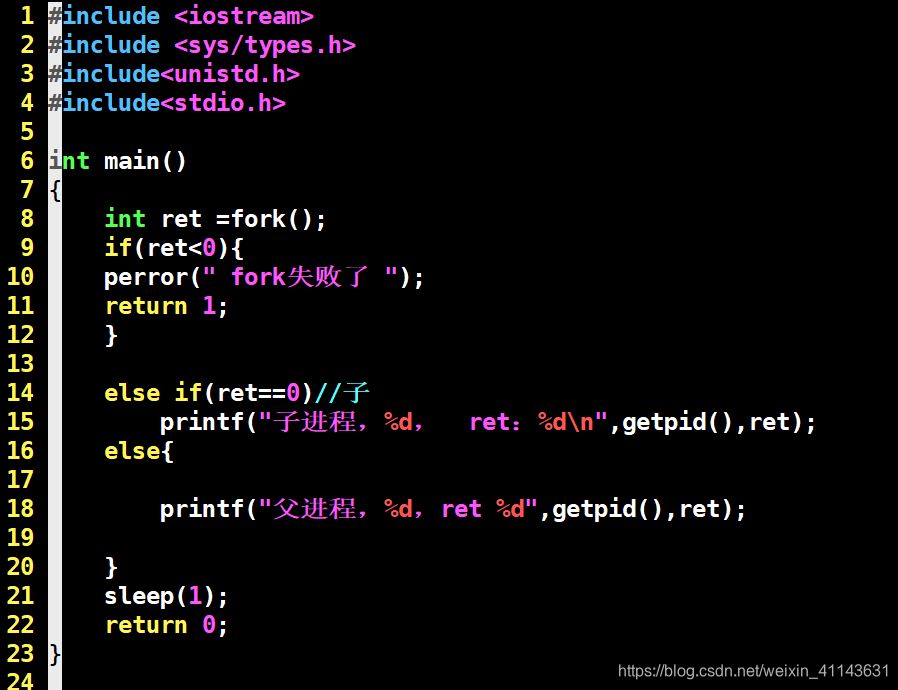
这是理论部分,我总结了一下,摘抄自《UNIX编程》
顺便使用一下哥们买的阿里云,在上面敲一下代码,hhhh,美滋滋。
task_struct是Linux内核的一种数据结构,它会被装载到RAM中并且包含着进程的信息。每个进程都把它的信息放在 task_struct 这个数据结构体,task_struct 包含了这些内容:
(1)标示符 : 描述本进程的唯一标识符,用来区别其他进程。
(2)状态 :任务状态,退出代码,退出信号等。
(3)优先级 :相对于其他进程的优先级。
(4)程序计数器:程序中即将被执行的下一条指令的地址。
(5)内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
(6)上下文数据:进程执行时处理器的寄存器中的数据。
(7) I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
(8) 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
在linux中每一个进程都由task_struct 数据结构来定义.task_struct就是我们通常所说的PCB。 ta是对进程控制的唯一手段也是最有效的手段. 当我们调用fork() 时,系统会为我们产生一个task_struct结构。然后从父进程,那里继承一些数据, 并把新的进程插入到进程树中,以待进行进程管理。因此了解task_struct的结构对于我们理解任务调度(在linux 中任务和进程是同一概念)的关键。
每一个进程的状态可以记录
#define TASK_RUNNING 0//进程要么正在执行,要么准备执行
#define TASK_INTERRUPTIBLE 1 //可中断的睡眠,可以通过一个信号唤醒
#define TASK_UNINTERRUPTIBLE 2 //不可中断睡眠,不可以通过信号进行唤醒
#define __TASK_STOPPED 4 //进程停止执行
#define __TASK_TRACED 8 //进程被追踪
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16 //僵尸状态的进程,表示进程被终止,但是父进程还没有获取它的终止信息,比如进程有没有执行完等信息。
#define EXIT_DEAD 32 //进程的最终状态,进程死亡
/* in tsk->state again */
#define TASK_DEAD 64 //死亡
#define TASK_WAKEKILL 128 //唤醒并杀死的进程
#define TASK_WAKING 256 //唤醒进程
linux把不同的pid与系统中每个进程或轻量级线程关联,而unix程序员希望同一组线程具有共同的pid,遵照这个标准linux引入线程组的概念。一个线程组所有线程与领头线程具有相同的pid,存入tgid字段,getpid()返回当前进程的tgid值而不是pid的值。

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









