




 本文介绍了如何使用BeautifulSoup库进行网页爬取,并通过具体实例展示了从指定网站抓取段子的过程。文章包括库的安装、基本使用方法及完整的代码示例。
本文介绍了如何使用BeautifulSoup库进行网页爬取,并通过具体实例展示了从指定网站抓取段子的过程。文章包括库的安装、基本使用方法及完整的代码示例。
本文主要内容:
1.beautifulsoup库安装。
2.beautifulsoup库介绍。
3.爬取段子实例。
1.beautifulsoup库安装。
要使用beautifulsoup库,必须要先安装,安装很简单,使用控制台输入
pip install beautifulsoup4
在使用的时候我们在代码首行输入from bs4 import BeautifulSoup就可以使用了,下面是使用的一个小例子。
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
print(soup.prettify)
main()2.beautifulsoup库介绍。
Beautifulsoup库是解析、遍历、维护“标签树”的功能库。
Beautifulsoup对应一个html/xml文档的全部内容,我们通过Beautifulsoup熬制一锅“汤”,里面包含一个树形结构,方便我们解析,管理,提取信息等。
具体的如库的方法,属性,使用,如何遍历查找等请参照下面文档,里面讲解的十分清楚,此处不做过多解释。
链接:https://pan.baidu.com/s/1X1AWOmAh4qdbdHy5vk-zDw 密码:rzy1
3.爬取段子实例。
了解了Beautifulsoup库之后,我们对该库有了一定的理解,接下来我将带领一步一步去实现爬取网页以及如何解析获得我们要的段子。
1.爬取的整体框架。
def getHTMLText(url):
#使用Requests库获得网页信息
def fillUnivList(ulist, html):
#使用Beautifulsoup库解析网页。
def printUnivList(ulist):
#打印结果
def main():
uinfo = []
u = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo)2.获得网页信息。
此处需要用到Requests库,在前面文章的最后我已经实现了爬取一个段子网站的网页。请参考:
Python爬虫(一):爬虫介绍、Requests库介绍及实例
此处不做详细介绍,直接粘贴出代码:
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""3.解析网页信息。
我们得到网页全部的信息后,需要解析网页,得到想要的数据。此处我们解析的是静态网页,需要查看网站的网页结构,我们打开我们要爬取的段子网站:
http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/
我们查看网页源代码或者用F12打开开发者选项,查看网页结构。
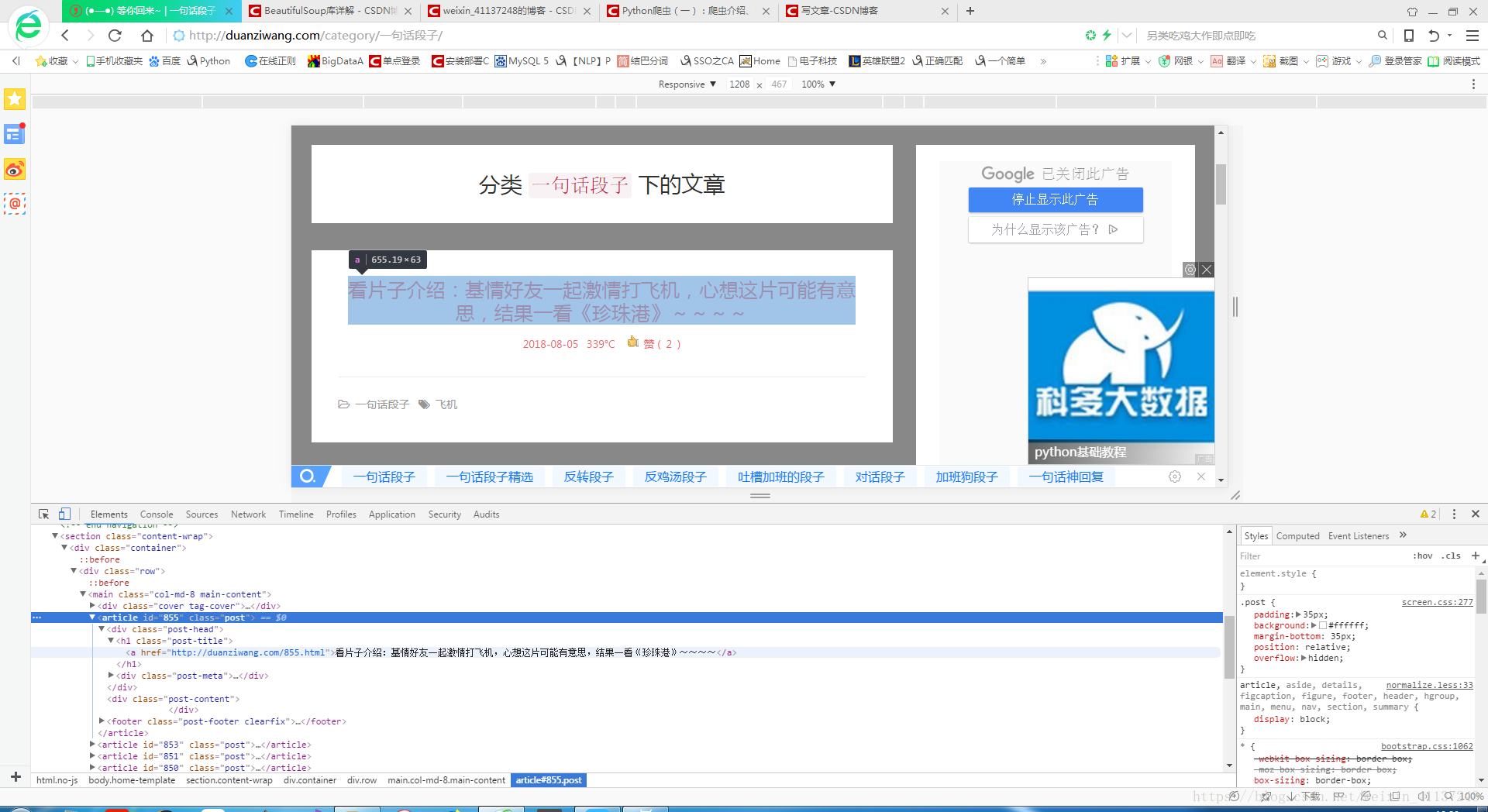
通过查找分析结构,我们发现我们要爬取的段子位于标签位于:<a href=''***********">“我们要的段子”</a>
一个段子模块又由<article id=" ***" class="post"> ..........</article>统一管理,里面有很多个a标签,我们的段子在改模块下的第一个a标签内。
下面贴出代码及注解:
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser") #使用Beautifulsoup库解析HTML文档,获得一锅“汤”
for tr in soup.find_all('article'): #找到所有的article标签,分别对每个article标签做处理
if isinstance(tr, bs4.element.Tag): #判断我们找到的article是否为HTML标签
tds = tr('a') #找到一个article标签下的所有a标签
ulist.append(tds[0].string) #将第一个a标签下的文字加入到ulist,此时即获得一条我们需要的段子3.打印结果。
打印结果即遍历ulist列表,用一个for循环分别打印每一行,如下:
def printUnivList(ulist):
i=0
for u in ulist:
i=i+1
print("{}.{}".format(i,u))
4.完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 8 17:20:34 2018
@author: Administrator
"""
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find_all('article'):
if isinstance(tr, bs4.element.Tag):
tds = tr('a')
ulist.append(tds[0].string)
def printUnivList(ulist):
i=0
for u in ulist:
i=i+1
print("{}.{}".format(i,u))
def main():
uinfo = []
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo)
main()5.运行结果


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









