




 本文作者分享了近期参加的几场大数据相关面试的经历,包括面试的公司、面试过程中的技术问题,涉及Hadoop生态圈、排序、Kafka、Storm、Zookeeper、Hbase等技术。此外,还分享了不同公司的面试风格和待遇,为读者提供了宝贵的面试经验和知识点汇总。
本文作者分享了近期参加的几场大数据相关面试的经历,包括面试的公司、面试过程中的技术问题,涉及Hadoop生态圈、排序、Kafka、Storm、Zookeeper、Hbase等技术。此外,还分享了不同公司的面试风格和待遇,为读者提供了宝贵的面试经验和知识点汇总。
1 总体情况
现在我面试了三家
第一家:***技术股份有限公司,已经得到复试通知
第二家:***第一研究所,面试成功,给的待遇是18万~20万/年。他们在等待我的回复。
第三家:电话面试,面得不好,这个部门主要不是开发,他需要熟悉各组件,做架构推荐的。
下面是面试题汇总,我自己做了一些,有些正在看。
2 ***技术股份有限公司
2.1 面试题
2.1.1 介绍自己,讲讲自己的项目
2.1.2 hadoop的生态圈
请查看网址:http://cqwjfck.blog.chinaunix.net/uid-22312037-id-3969789.html
一张图看懂生态圈:
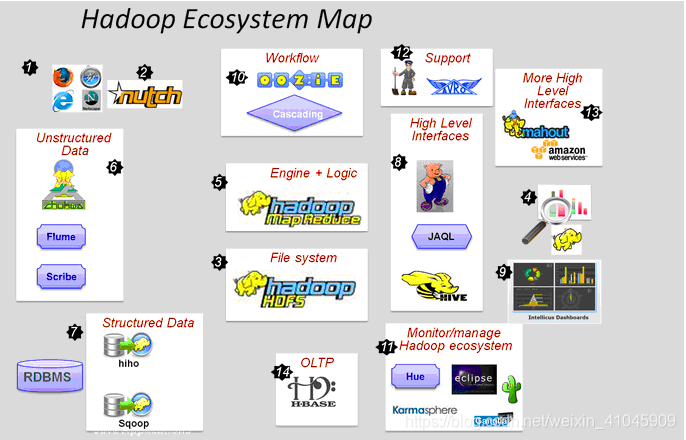
Hadoop生态系统的图谱,详细的列举了在Hadoop这个生态系统中出现的各种数据工具。
-
这一切,都起源自Web数据爆炸时代的来临
-
数据抓取系统 - Nutch
-
海量数据怎么存,当然是用分布式文件系统 - HDFS
-
数据怎么用呢,分析,处理
-
MapReduce框架,让你编写代码来实现对大数据的分析工作
-
非结构化数据(日志)收集处理 - fuse,webdav, chukwa, flume, Scribe
-
数据导入到HDFS中,至此RDBSM也可以加入HDFS的狂欢了 - Hiho, sqoop
-
MapReduce太麻烦,好吧,让你用熟悉的方式来操作Hadoop里的数据 – Pig, Hive, Jaql
-
让你的数据可见 - drilldown, Intellicus用高级语言管理你的任务流 – oozie, Cascading
-
Hadoop当然也有自己的监控管理工具 – Hue, karmasphere, eclipse plugin, cacti, ganglia
-
数据序列化处理与任务调度 – Avro, Zookeeper
-
更多构建在Hadoop上层的服务 – Mahout, Elastic map Reduce
-
OLTP存储系统 – Hbase
-
How did it a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2707
2707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









