



SENet
论文的核心点在对CNN中的feature channel(特征通道依赖性)利用和创新。普通卷积通常都是在局部感受野上将空间信息和特征维度的信息进行聚合,最后获取全局信息。通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去增强有用的特征并抑制对当前任务用处不大的特征,通俗来讲,就是让网络利用全局信息有选择的增强有益feature通道并抑制无用feature通道,从而能实现feature通道自适应校准。
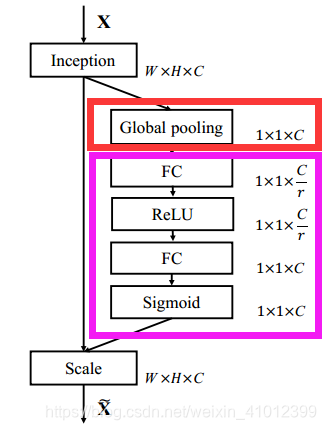
SE block如图1所示,论文的核心就是Squeeze和Excitation(论文牛的地方)两个操作。
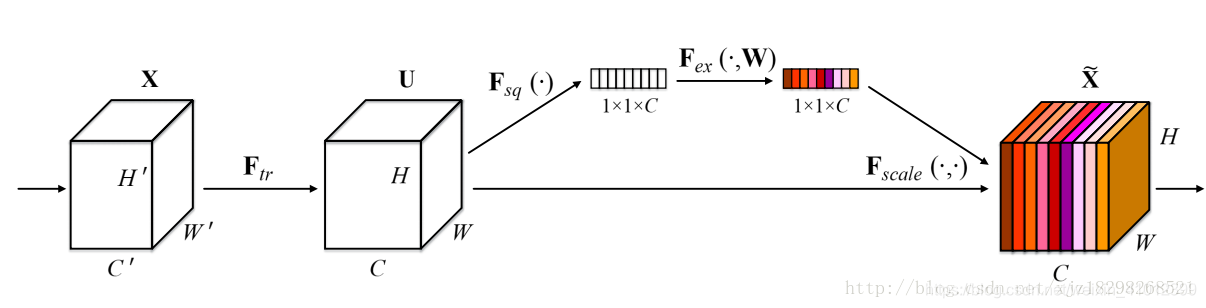
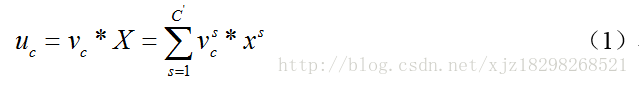
Squeeze(挤压)过程:
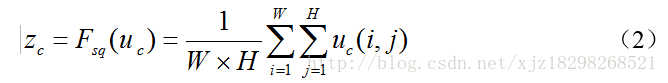
Squeeze操作就是采用全局平均池化操作对每张图进行压缩,挤压成一个点,变成11C,从而使其具有全局的感受野,使得网络低层也能利用全局信息。
Excitation(激励)过程:
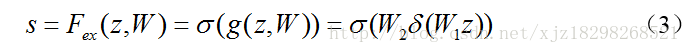
Excitation操作(如图2紫色框标注)利用自己学习到的权值捕获通道间的依赖性。
为了限制模型复杂度,论文引入两个全连接(FC)层(都是11的conv层),先降维,降维比例为r(论文把它设置为16),然后经过一个ReLU,然后是一个参数为W2的升维层。
最后得到11*C的实数数列结合U(原始缝feature map)通过公式4进行Scale操作得到最终的输出。
SENet里的模块可以加在之前的Inception系列和resnet系列等网络中,
部分程序:
class SE_Inception_v4():
def __init__(self, x, training):
self.training = training
self.model = self.Build_SEnet(x)
def Stem(self, x, scope):
with tf.name_scope(scope) :
x = conv_layer(x, filter=32, kernel=[3,3], stride=2, padding='VALID', layer_name=scope+'_conv1')
x = conv_layer(x, filter=32, kernel=[3,3], padding='VALID', layer_name=scope+'_conv2')
block_1 = conv_layer(x, filter=64, kernel=[3,3], layer_name=scope+'_conv3')
split_max_x = Max_pooling(block_1)
split_conv_x = conv_layer(block_1, filter=96, kernel=[3,3], stride=2, padding='VALID', layer_name=scope+'_split_conv1')
x = Concatenation([split_max_x,split_conv_x])
split_conv_x1 = conv_layer(x, filter=64, kernel=[1,1], layer_name=scope+'_split_conv2')
split_conv_x1 = conv_layer(split_conv_x1, filter=96, kernel=[3,3], padding='VALID', layer_name=scope+'_split_conv3')
split_conv_x2 = conv_layer(x, filter=64, kernel=[1,1], layer_name=scope+'_split_conv4')
split_conv_x2 = conv_layer(split_conv_x2, filter=64, kernel=[7,1], layer_name=scope+'_split_conv5')
split_conv_x2 = conv_layer(split_conv_x2, filter=64, kernel=[1,7], layer_name=scope+'_split_conv6')
split_conv_x2 = conv_layer(split_conv_x2, filter=96, kernel=[3,3], padding='VALID', layer_name=scope+'_split_conv7')
x = Concatenation([split_conv_x1,split_conv_x2])
split_conv_x = conv_layer(x, filter=192, kernel=[3,3], stride=2, padding='VALID', layer_name=scope+'_split_conv8')
split_max_x = Max_pooling(x)
x = Concatenation([split_conv_x, split_max_x])
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
return x
def Inception_A(self, x, scope):
with tf.name_scope(scope) :
split_conv_x1 = Avg_pooling(x)
split_conv_x1 = conv_layer(split_conv_x1, filter=96, kernel=[1,1], layer_name=scope+'_split_conv1')
split_conv_x2 = conv_layer(x, filter=96, kernel=[1,1], layer_name=scope+'_split_conv2')
split_conv_x3 = conv_layer(x, filter=64, kernel=[1,1], layer_name=scope+'_split_conv3')
split_conv_x3 = conv_layer(split_conv_x3, filter=96, kernel=[3,3], layer_name=scope+'_split_conv4')
split_conv_x4 = conv_layer(x, filter=64, kernel=[1,1], layer_name=scope+'_split_conv5')
split_conv_x4 = conv_layer(split_conv_x4, filter=96, kernel=[3,3], layer_name=scope+'_split_conv6')
split_conv_x4 = conv_layer(split_conv_x4, filter=96, kernel=[3,3], layer_name=scope+'_split_conv7')
x = Concatenation([split_conv_x1, split_conv_x2, split_conv_x3, split_conv_x4])
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
return x
def Reduction_A(self, x, scope):
with tf.name_scope(scope) :
k = 256
l = 256
m = 384
n = 384
split_max_x = Max_pooling(x)
split_conv_x1 = conv_layer(x, filter=n, kernel=[3,3], stride=2, padding='VALID', layer_name=scope+'_split_conv1')
split_conv_x2 = conv_layer(x, filter=k, kernel=[1,1], layer_name=scope+'_split_conv2')
split_conv_x2 = conv_layer(split_conv_x2, filter=l, kernel=[3,3], layer_name=scope+'_split_conv3')
split_conv_x2 = conv_layer(split_conv_x2, filter=m, kernel=[3,3], stride=2, padding='VALID', layer_name=scope+'_split_conv4')
x = Concatenation([split_max_x, split_conv_x1, split_conv_x2])
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
return x
def Squeeze_excitation_layer(self, input_x, out_dim, ratio, layer_name):
with tf.name_scope(layer_name) :
squeeze = Global_Average_Pooling(input_x)
excitation = Fully_connected(squeeze, units=out_dim / ratio, layer_name=layer_name+'_fully_connected1')
excitation = Relu(excitation)
excitation = Fully_connected(excitation, units=out_dim, layer_name=layer_name+'_fully_connected2')
excitation = Sigmoid(excitation)
excitation = tf.reshape(excitation, [-1,1,1,out_dim])
scale = input_x * excitation
return scale
def Build_SEnet(self, input_x):
x = self.Stem(input_x, scope='stem')
for i in range(4) :
x = self.Inception_A(x, scope='Inception_A'+str(i))
channel = int(np.shape(x)[-1])
x = self.Squeeze_excitation_layer(x, out_dim=channel, ratio=reduction_ratio, layer_name='SE_A'+str(i))
x = self.Reduction_A(x, scope='Reduction_A')
for i in range(7) :
x = self.Inception_B(x, scope='Inception_B'+str(i))
channel = int(np.shape(x)[-1])
x = self.Squeeze_excitation_layer(x, out_dim=channel, ratio=reduction_ratio, layer_name='SE_B'+str(i))
x = self.Reduction_B(x, scope='Reduction_B')
for i in range(3) :
x = self.Inception_C(x, scope='Inception_C'+str(i))
channel = int(np.shape(x)[-1])
x = self.Squeeze_excitation_layer(x, out_dim=channel, ratio=reduction_ratio, layer_name='SE_C'+str(i))
x = Global_Average_Pooling(x)
x = Dropout(x, rate=0.2, training=self.training)
x = flatten(x)
x = Fully_connected(x, layer_name='final_fully_connected')
return x
参考:https://blog.youkuaiyun.com/xjz18298268521/article/details/79078551
参考:https://github.com/taki0112/SENet-Tensorflow

















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









