




 本文介绍了XPath,一种用于定位XML文档中节点的语言,并详细解释了其在Python爬虫中的应用。文章提供了XPath的基本语法,节点操作示例,以及如何在Python中使用第三方库lxml进行安装和操作。通过一个具体的爬虫案例,展示了如何利用XPath抓取和处理网页内容。
本文介绍了XPath,一种用于定位XML文档中节点的语言,并详细解释了其在Python爬虫中的应用。文章提供了XPath的基本语法,节点操作示例,以及如何在Python中使用第三方库lxml进行安装和操作。通过一个具体的爬虫案例,展示了如何利用XPath抓取和处理网页内容。
XPath介绍
XPath 即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath节点操作
XPath语法
它使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
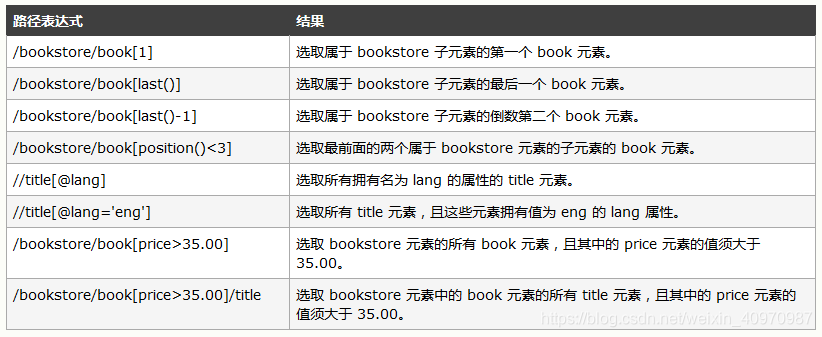
下面列出了最有用的路径表达式:
 实例
实例
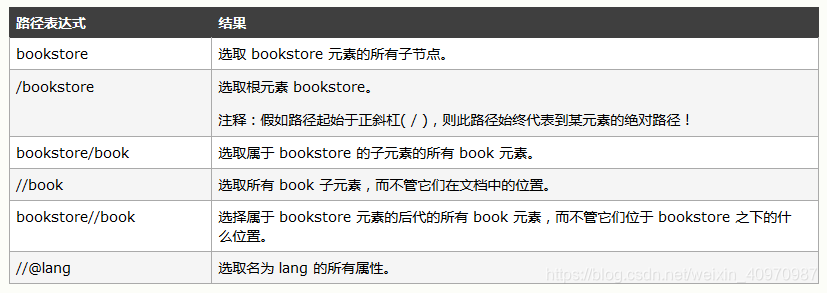 用谓语来查找某个特定的节点或者包含某个指定的值的节点,嵌在方括号中。
用谓语来查找某个特定的节点或者包含某个指定的值的节点,嵌在方括号中。
实例
XPath在Python爬虫中的应用
xpath的安装
xpath在Python中有一个第三方库,支持~ lxml
pip install wheel
pip install lxml
xpath的使用
获取文本内容用 text(),string()
获取注释用 comment()
获取其它任何属性用@xx,如
@href
@src
@value
其中text()和string略有不同,text()它仅仅返回所指元素的文本内容,string()函数会得到所指元素的所有节点文本内容,这些文本讲会被拼接成一个字符串。string(.)表示当前节点。
爬取小说案例
import urllib,urllib.request,re
from urllib.request import Request
from lxml import etree
#爬取数据
def getText(url,file_name):
print('开始爬取第%s章的内容'%file_name)
#伪装请求头
my_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36'
}
request = urllib.request.Request(url,headers=my_headers)
content = urllib.request.urlopen(request).read()
return content
#保存数据
def save(content):
xml = etree.HTML(content)
'''
xpath路径获取:
浏览器打开页面,选中要爬取部分标签,选择copy->cope xpath
'''
datas = xml.xpath('/html/body/div[@id="main"]/h1 | /html/body/div[@id="main"]/p')
data = datas[2].xpath('string(.)').encode('utf-8')
name = datas[0].xpath('string(.)')
print(name)
print('第%s章的内容爬取完成'%file_name)
with open('txt/%s'%name+'.txt','wb') as f:
f.write(data)
#定义主程序接口
if __name__ == '__main__':
x = 41277
while x<x+50:
url = 'http://www.ty2016.net/net/zhuxian/'+str(x)+'.html'
x+=1
file_name = str(x-41278)
try:
content = getText(url,file_name)
save(content)
except Exception as a:
print(a)
结果:
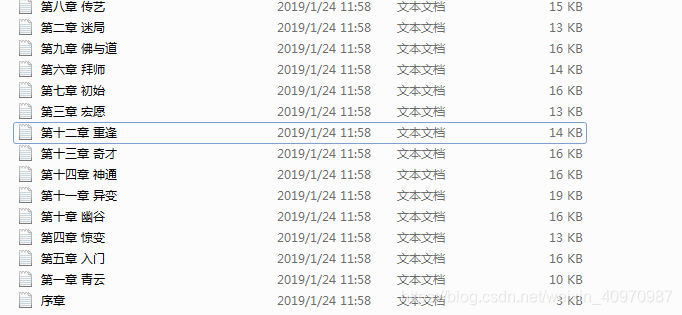

















 7580
7580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









