



首先看一下原始数据
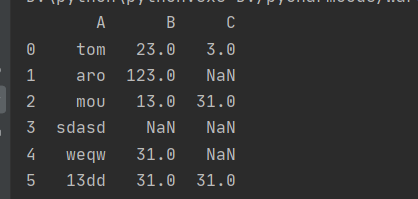
下面使用pandas中的方法去掉带有空值的行
import pandas as pd
data=pd.read_excel('文档目录\\test.xlsx')
pds=pd.DataFrame(data=data)
print(pds)
###去除空值行方法
pddrop=pds.dropna()
print(pddrop)
##重新生成新的表格
pddrop.to_csv('文档目录\\test1.csv',index=False)
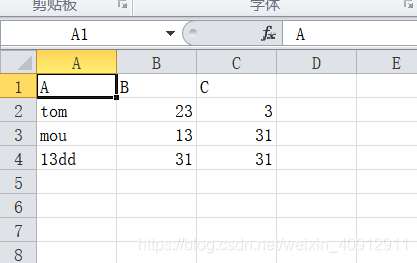
 这段内容展示了如何使用pandas库读取Excel文件,并通过dropna()方法删除含有空值的行,然后将处理后的数据保存为新的CSV文件。
这段内容展示了如何使用pandas库读取Excel文件,并通过dropna()方法删除含有空值的行,然后将处理后的数据保存为新的CSV文件。
首先看一下原始数据
下面使用pandas中的方法去掉带有空值的行
import pandas as pd
data=pd.read_excel('文档目录\\test.xlsx')
pds=pd.DataFrame(data=data)
print(pds)
###去除空值行方法
pddrop=pds.dropna()
print(pddrop)
##重新生成新的表格
pddrop.to_csv('文档目录\\test1.csv',index=False)
 898
2085
8507
898
2085
8507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























