




 本文详细介绍了操作系统如何支持多进程,包括进程设计思路、进程状态转换及实际的进程切换案例。通过Linux0.11内核,阐述了fork函数创建进程、schedule函数调度进程以及进程状态图。在进程切换中,使用了时间片机制,并通过修改PC指针和保存恢复进程状态来实现代换。同时,讨论了进程的不同状态,如就绪态、阻塞态和运行态等。
本文详细介绍了操作系统如何支持多进程,包括进程设计思路、进程状态转换及实际的进程切换案例。通过Linux0.11内核,阐述了fork函数创建进程、schedule函数调度进程以及进程状态图。在进程切换中,使用了时间片机制,并通过修改PC指针和保存恢复进程状态来实现代换。同时,讨论了进程的不同状态,如就绪态、阻塞态和运行态等。
多进程图像
所谓多进程图像就是:多道程序,交替执行。本章主要介绍操作系统为支持多进程图像做了哪些工作。
1 多进程设计
CPU 作为计算机最关键的设备,使用好 CPU 自然而然成为了操作系统的重中之重。CPU 是一个“取指执行”的设备(设置好 PC 指针的初值,然后每次执行一条指令CPU会让“PC加1”)。如果CPU只需要处理单个任务(单进程),那么一条一条的“取指执行”是毫无问题的,因为就算遇到了 IO 指令,那也没办法,只能等着,不能跳过。
那如果有多个任务需要处理呢?当一个进程需要等待资源(如等待磁盘数据),可不可以切换到其他进程呢?这样才能提高CPU的使用率。操作系统支持多进程图像的设计由此开始。
2 一个大概的设计思路
让 CPU 切换到另一个进程去执行,可以通过修改 PC 指针实现。可是怎么切回来呢?为了保证切回来时是接着上次的状态继续执行,因此切换前,应该先记录好切换前进程的“样子”(包括切换前各个寄存器的值,进程执行的状态等),然后再修改PC 指针。Linux0.11 设计了一个结构体:struct task_struct{...},用于记录进程的“样子”,每个进程都有一个该结构体的对象——PCB(进程控制块)。
如何选择下一个要运行的进程呢?一个简单又实用的办法就是利用队列,将所有进程的PCB指针存放在队列中,然后用先进先出的方式安排下一个要运行的进程。Linux0.11 中设计了一个这样的队列 task :
struct task_struct * task[NR_TASKS] = {&(init_task.task), }; //定义任务指针数组
Linux0.11中编写了 schedule 函数用来选择下一个要运行的进程,并且在schedule中调用了 switch_to 函数实现切换到下一个进程的功能。task 队列中有各种状态的进程的PCB,所以在switch_to 函数切换前可以先判断一下,下一个要切换到的进程是不是阻塞态的,如果是的话就先跳过。
谁来执行切换的工作呢?其实也很好猜,因为进程要不断且快速的切来切去,才能让用户感觉所有任务都不卡,因此用定时器中断来切换再合适不过,此外也可以在当进程阻塞的时候就直接切出去。在 Linux0.11 中定义了一个 do_time 函数,该函数在 timer_interrupt(系统时钟中断,每10ms发生一次时钟中断)中 被调用的。do_time 函数最后调用了 schedule函数。
前面提到了阻塞态。一个进程在其生命周期内,可以存在多个状态,当进程在内核执行时需要读磁盘,此时进程会要进入阻塞态,等待资源;当进程等到资源时,就可以进入就绪态了;如果之后进程抢到了CPU,那么进程又进入了运行态。因此可以设计一个进程状态图,用来描述进程的各种状态之间的转换关系。在struct task_struct中就有一个成员变量 state,用于记录进程当前的运行状态。
最后还有一个问题,并发时如何保证各个进程不相互干扰?比如说进程1执行了 mov [100], ax ,而内存地址[100]处恰好有进程2存放的重要数据,如果让进程1执行了该指令,那进程2的重要数据就被破坏了。一种办法是将各个进程的地址空间分离开来,比如进程3、进程4都调用了mov [200], ax,那就把进程3的[200]映射到物理内存的 7000H 处,而将进程4的[200]映射到物理内存的 8000H 处。利用映射表(实际上也就是MMU)将各个进程的地址空间分离。这部分属于操作系统内存管理的部分,之后再分析。
3 一个实际的进程切换案例
本节主要分析Linux0.11中进程切换的过程。Linux中使用PCB来描述一个进程,实际上PCB就是一个结构体对象,下面列出了本节会用的的该结构体的几个重要字段:
struct task_struct {
long state; //进程当前运行状态,有TASK_RUNNING(就绪态)、TASK_INTERRUPTIBLE等几种取值
long counter; //任务运行时间计数,即运行时间片。采用递减方式,counter越大表明任务已经运行的时间越短
long priority;//运行优先数,用于给counter赋初值。一个进程刚被创建时counter = priority。
...
}
3.1 进程的创建 - fork函数
调用 fork() 时会创建一个子进程,因此分析进程切换应该从 fork() 开始。 fork() 的执行过程如下:
- fork()内执行
int 0x80指令,进入内核 - 执行
system_call:程序(汇编程序) - 执行
sys_fork:程序(汇编程序) - 执行
copy_process()函数(C程序)
copy_process()才是真正创建子进程的地方。"sys_fork:"程序调用"copy_process()"是汇编调用C函数的过程,copy_process()中的那一大堆形参都是通过在汇编程序中压栈传递的,可以看出在copy_process()前面的汇编程序将许多寄存器进行了压栈。copy_process()的工作内容如下(程序内容进行了裁剪):
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
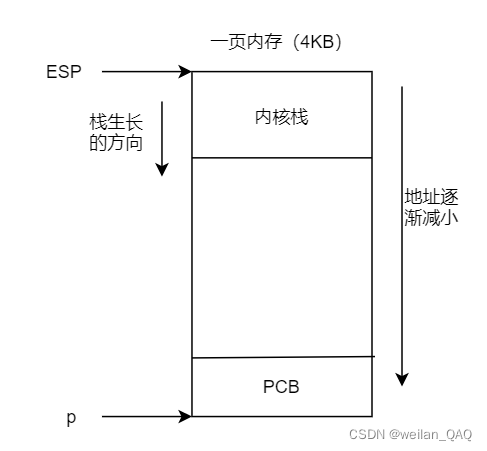
//1、为子进程的PCB分配空间,注意这里分配了一页内存(4KB),
//其实这里连同内核栈的空间一起分配了
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
//2、将子进程加入到总调度队列中。nr指向了task[]中的一个空位置
task[nr] = p;
//3、将父进程(current:当前进程)的PCB复制给子进程,然后修改子进程PCB的部分字段
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
//这样做不会复制堆栈部分,只复制结构体
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;/* last_pid是最新进程号,也就是子进程的pid */
p->father = current->pid;
p->counter = p->priority;
...
//4、设置子进程内核栈的栈顶指针指向"p"这一页内存的最高处(地址最大处)
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10; //0x10为内核数据段的选择符
p->tss.eip = eip;/* 让子进程和父进程执行相同的程序。注意这里的eip是在执行 int 0x80 压入的eip,也就是说
子进程在下次被调度执行的的时候(也就是第一次被调度的时候),是从 int 0x80
后面一句指令开始执行的,而不是从copy_process()开始执行*/
p->tss.eflags = eflags;
p->tss.eax = 0;/* 子进程fork()完后返回0的原因所在*/
...
//5、设置子进程的用户栈,让子进程与父进程共用一个用户栈
p->tss.esp = esp;
p->tss.ss = ss & 0xffff;
...
//6、将子进程设置为就绪态,然后父进程返回
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid;/* return会让返回值(last_pid)保存在eax中。这里是父进程在fork()完后要返回的子进程的pid。
那么子进程fork()完后要返回的0在哪里返回的呢?在 _syscall0(int,fork) 函数的那个return返回。*/
}
在执行完copy_process()后,子进程的内核栈就被创建成了如下模样:
3.2 进程的切换 - schedule函数
本节主要分析定时器中的进程切换,即do_time()中的进程切换。其实schedule()除了在do_time()中被调用外,在其他地方也有被调用。
Linux0.11中有一个定时器中断,每10ms进入一次,在这个中断中调用了do_time()。这个定时器中断主要做了如下工作:
timer_interrupt:
...
#1、让jiffies加1。jiffies为全局变量,表示从开机时到现在发生的时钟中断次数,这个数也被称为“滴答数”。
incl jiffies
...
#2、调用do_timer(), 其中eax为do_timer()的传入参数,当前特权级。
movl CS(%esp),%eax
andl $3,%eax # %eax is CPL (0 or 3, 0=supervisor)
pushl %eax
call do_timer # 'do_timer(long CPL)' does everything from
...
do_timer()主要工作如下:
void do_timer(long cpl)
{
...
#1、当前任务运行计数值减1,若计数值不为0(即时间片还未用完),则继续运行当前线程。
if ((--current->counter)>0) return;
current->counter=0;
if (!cpl) return;#若是内核代码则不进行调度,因为内核代码不参与调度。
#2、若时间片用完了,则进行调度,切换到下一个任务
schedule();
}
从do_timer()可以看出,Linux0.11中采用了时间片的机制来切换进程,即:给每个进程分配一个时间片,若时间片用完了则调用schedule()函数。schedule()会重新分配各个进程的时间片,并在 task 队列中找到下一个需要运行的进程,然后调用switch_to。switch_to将当前进程的寄存器状态保存起来(保存在当前进程的 tss 中),然后将下一个进程的tss中的内容扣在CPU的寄存器中(包括PC指针)从而实现了进程的切换。关于schedule()的详细注释可以参考实验4:基于内核栈切换的进程切换
3.3 进程状态转换图
本节主要介绍几个与状态切换相关的函数。进程状态图如下:
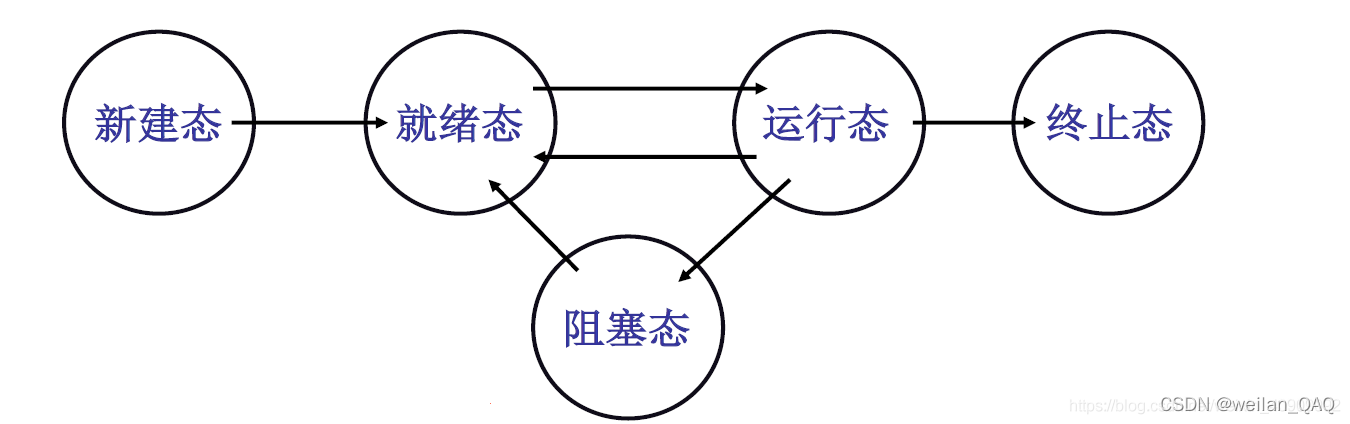
顺便贴上一个进程状态表:
| 内核表示 | 含义 |
|---|---|
| TASK_RUNNING | 可运行(就绪态或运行态) |
| TASK_INTERRUPTIBLE | 可中断的等待状态,是阻塞态的一种 |
| TASK_UNINTERRUPTIBLE | 不可中断的等待状态,是阻塞态的一种 |
| TASK_ZOMBIE | 僵尸态(图中的终止态) |
| TASK_STOPPED | 暂停 |
下面列出几个有改变进程状态功能的函数,帮助理解进程状态转换图:
do_exit():由sys_exit()函数调用。会将当前进程置为僵尸态,然后调用schedule()切换到下一个进程;sys_waitpid():回收子进程,若子进程还未变为僵尸态,则该函数会将当前进程变为阻塞态(TASK_INTERRUPTIBLE),然后调用schedule()切换到下一个进程;copy_process():创建子进程,创建前子进程为新建态,创建结束后会将子进程设置为就绪态;schedule():调度函数。首先进行信号处理,可能会将一些阻塞态的进程变为就绪态。然后找到下一个需要运行的进程,并执行它(此时该进程就变为运行态了);sys_pause():将当前进程变为阻塞态(TASK_INTERRUPTIBLE),然后调用schedule()切换到下一个进程;wake_up():将进程置为就绪态;
3.4 如何执行我们自己的代码
子进程在被创建之后默认执行的是父进程的代码,通常子进程可以调用execve()来加载执行自己的代码。execve()是一个系统调用,真正实现其功能的是do_execve()函数,这两个函数的原型如下:
int execve(const char * filename, char ** argv, char ** envp);
int do_execve(unsigned long * eip,long tmp,char * filename,char ** argv, char ** envp)
应用程序调用 execve() 函数,可以进入内核。当一个任务进入内核态运行时,就会使用其 TSS 段给出的特权级0的堆栈指针:tss.ss0、tss.esp0,即内核栈。 也就是说进程进入内核态后,硬件自动帮进程由用户栈切换到内核栈。
和其他系统调用一样,execve()也是通过压栈的方式向内核传递参数。从调用execve(),到执行do_execve()前,内核栈的被压入了如下内容:

可以看出此时的内核栈中有子进程的PC指针和用户栈指针。为了能让子进程能去执行新的程序,do_execve()会替换掉栈中的PC指针和用户栈指针,将原来的PC指针替换为新执行程序的运行地址。当中断返回,执行“iret”指令后,栈中的PC指针和用户栈指针就会被弹出,并赋值到对应的寄存器中,从而让子进程切换到新的程序去执行。
关于内核栈和用户栈之间切换的方式在《Linux内核完全剖析——基于0.12内核》的第5.8节:Linux系统中堆栈的使用方法,中有详细介绍。
参考资料
图3.2 进程状态图截取自哈工大操作系统课程的课件。
[1] 操作系统-哈尔滨工业大学-中国大学MOOC
[2] 哈工大操作系统实验手册
[3] Linux内核完全剖析——基于0.12内核

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









