



 本文指导如何使用GitHub上的wikipedia-parallel-titles工具,通过ISO 639-2码下载特定语言的维基百科语料,创建阿拉伯语与英语的平行语料库。过程包括下载、提取和特定语言的过滤。
本文指导如何使用GitHub上的wikipedia-parallel-titles工具,通过ISO 639-2码下载特定语言的维基百科语料,创建阿拉伯语与英语的平行语料库。过程包括下载、提取和特定语言的过滤。
本文辅助有需求人士建立平行语料库。
工具GitHub链接https://github.com/clab/wikipedia-parallel-titles
第一步:从” https://en.wikipedia.org/wiki/List_of_ISO_639-2_codes” 上查看自己选的小语种的639-1码
第二步:假设我要做的是阿拉伯-英语平行语料库,阿拉伯语的639-1码为ar,英文的为en
到http://dumps.wikimedia.org/arwiki下载阿拉伯语的语料文件
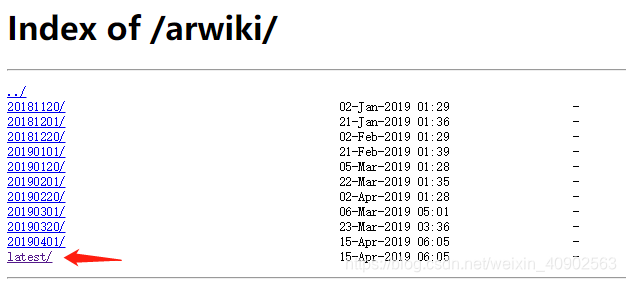
进入到latest,下载后缀名是 -page.sql.gz和 -langlinks.sql.gz的文件,提倡挂VPN下载会比较快
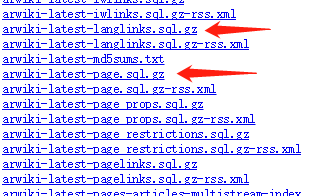
第三步:工具GitHub链接https://github.com/clab/wikipedia-parallel-titles,下载该包,解压之后,在其目录下可看到以下文件
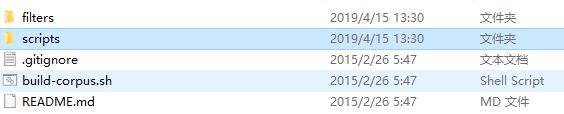
第四步:提取并行语料库,CMD访问该目录,命令为: ./build-corpus.sh en arwiki-latest > titles.txt
PS:特定于语言的过滤
如果该对中的一种语言使用特定的Unicode范围,则可以轻松过滤掉不包含此类字符的行。filters/目录中包含一些脚本的示例过滤器。
例如,以下内容将筛选出不包含至少一个Perso-Arabic字符的对:
./build-corpus.sh en arwiki-20140831 | ./filters/filter-perso-arabic.pl > titles.txt
最后,如果titles.txt是空的,将scripts中的extract.pl和utf8-normalize.sh文件用记事本打开
将所有的iconv -f utf8 -t utf8 -c 换成 iconv -f utf-8 -t utf-8 -c 即可。

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









