







一、Flink算子实操(图文)
https://zhangboyi.blog.youkuaiyun.com/article/details/114288304
二、flink处理数据倾斜
1. keyBy
keyBy有两个主要的应用,数据分发(处理数据倾斜、平衡数据),上下游算子异步处理
1.1 数据分发
这个算子作为一个数据分发策略【分发还有还有的策略,例如:reblance(轮询),partitionCustom(自定义)】,
keyBy是根据key的hashcode对分区数取模,根据某个字段作为key进行分组,key相同的会被分到一起,如下图示例,相同颜色的正方形分配到一起。
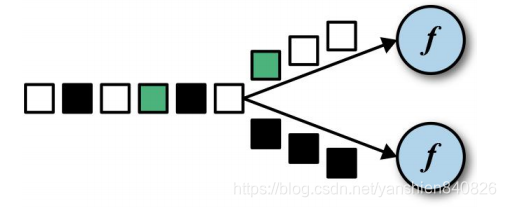
当DataStream的并行分区中数据发生倾斜时,我们会想要在这些分区中,重新平衡这些数据。这时我们可以通过一种方式来实现,使所有task会收到相同的数据。可以使用的分区策略有:
- keyBy,根据key的hashCode对分区数取模(hashCode%partitionNum,产生的是keyedStream)
- shuffle分区策略(random,产生的还是dataStream)
- rebalance分区策略(Round-Robin<询调度>,产生的还是dataStream)
- resclae,和rebalance类似,只是做了更细粒度的划分
1.2 异步处理
在DataStream中,经过keyBy后悔编程KeyedStream,这时会将被KeyBy分割的上下游算子 异步计算。具体示例请参考这篇文章

















 8903
8903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









