




 本文深入探讨了机器学习中的误差(loss函数)、偏差与方差的概念。误差分为训练误差和测试误差,偏差表示模型的预测与真实值的平均偏离,方差则衡量模型在不同数据集上的预测稳定性。高偏差可能导致欠拟合,而高方差则可能引发过拟合。理想的模型应该在偏差和方差之间取得平衡,以实现最佳的泛化能力。通过偏差-方差权衡,可以优化模型性能,降低测试误差。
本文深入探讨了机器学习中的误差(loss函数)、偏差与方差的概念。误差分为训练误差和测试误差,偏差表示模型的预测与真实值的平均偏离,方差则衡量模型在不同数据集上的预测稳定性。高偏差可能导致欠拟合,而高方差则可能引发过拟合。理想的模型应该在偏差和方差之间取得平衡,以实现最佳的泛化能力。通过偏差-方差权衡,可以优化模型性能,降低测试误差。
目录
误差(loss函数)
在机器学习语境中,我们可以理解为模型输出的预测值与数据集中的真实值的差距。如下图所示,红色点代表训练集中的真实值,而这些红色点恰好位于模型曲线上,此时模型在训练集的误差为0。
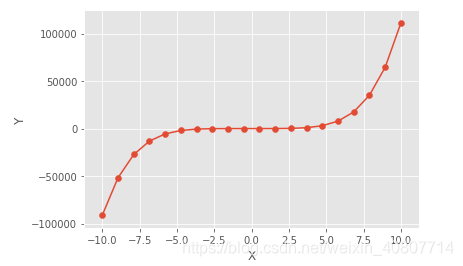
实际上,我们并不真正关心模型在训练集上的表现,我们更关心模型在测试集上的表现,测试集的数据是未知的。道理很简单,模型的功能在于预测未来,而且过于追求模型在训练集上的误差表现很容易造成果泥和过拟合,比如上图的模型。
这就引出了训练误差和测试误差,即模型在训练集上的误差以及模型在测试集上的误差。那么误差从何而来呢?接下来,我们将继续以回归模型为例,说明误差的来源。因此,我们的回归模型将采用MSE均方误差,即:
M S E ( y , y ^ ) = 1 n s a m p l e s ∑ i = 0 n s a m p l e s − 1 ( y i − y ^ i ) 2 MSE(y,ŷ )= \frac{1}{n_{samples}}∑^{n_{samples}−1}_{i=0}(y^i−ŷ ^i)^2 MSE(y,y^)=nsamples1i=0∑n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









