




 本文详细介绍了Python数据分析中关于索引的操作,包括`reindex`的使用、层次化索引的转化、数据分组、数据选择以及缺失值处理等。重点讲解了如何通过`reindex`改变索引顺序、填充缺失值,以及如何利用`swaplevel`和`sortlevel`进行层次化索引转换。此外,还讨论了如何插入、删除行和列,以及处理数据的合并和缺失值的方法。
本文详细介绍了Python数据分析中关于索引的操作,包括`reindex`的使用、层次化索引的转化、数据分组、数据选择以及缺失值处理等。重点讲解了如何通过`reindex`改变索引顺序、填充缺失值,以及如何利用`swaplevel`和`sortlevel`进行层次化索引转换。此外,还讨论了如何插入、删除行和列,以及处理数据的合并和缺失值的方法。
索引相关
>>frame.reindex([],method = ,fill_value = ) 参数是一个列表,列表的顺序决定frame的显示顺序。 当reindex的参数列表多于frame原有的index的数目,可以使用method进行填充缺失值,method的取值为ffill(或者pad)、bfill(或者backfill) ,分别表示向前填充、向后填充. Fill_value 是对于缺失值的赋值。 reindex不会改变原有frame的排列方式,如果要改变,需要重新赋值给原frame
>>对于reindex的用法。Frame.reindex(index = [],columns = [].method = ).如果只有一个列表,默认改变索引行,同时改变行索引和列索引,添加index和columns的参数即可

>>层次化索引 内外索引的转化
1)Frame.swaplevel(),括号的参数可以跟具体的index的轴标签的名字(index.name),下图是‘key1’,‘key2’,也可以跟(0,1) 如果是对列索引的层次化索引进行内外索引的转化,在swaplevel的参数中axis =1 即可,axis = 0表示行索引。
2)Frame.sortlevel(),参数为0或1,默认为0,按照第一个轴标签排序,如果为1,按照第二个轴标签排序(如下图参数为1时,带有箭头标志的输出结果)

>>行列索引转置交换:重新生成新的dataframe转化原本dataframe的行列索引。 对原df的values转置,然后进行行列索引的变换。

>>dataframe一般是是默认axis = 0,也即是对列属性进行操作。如使用apply函数时见下图

>>dataframe的元素级别应用函数 map
>>Argmin 和 idxmin的区别:
对于series: idxmin和argmin是相同的
对于dataframe:只有idxmin(axis = )参数为0是返回每列最小值的索引,参数为1 是返回每行最小值的索引
总结:为保证使用正确,尽量使用idxmin idxmax
>>替换修改特定元素:
1) replace只能根据数值进行替换,不能进行定位操作即不能根据行里索引确定值并替换。 2)set_value可以已知行列索引替换值。
3)使用map函数。
>>>>修改单个元素:Series:obj.set_value(index,columns,value) 注意参数index和colums必须是索引的名称,不能是数字( 在默认情况下不设定索引值时,可以使用) dataframe:frame.set_value(index,columns,value) 或者 frame.ix[index,column] = n
>>>>修改多个元素: 参考: https://www.cnblogs.com/cgmcoding/p/13362539.html
>>>>复杂修改:使用map函数

>>数据分组
>>>>对数据不同范围内进行分割和分组:pd.cut(data1,data2,labels = ,right =False or True,left =False or True) data1是要进行分组的数据, data2是分割各组的临界点,(如果data2是标量n,会自动按照数据的最大最小值分为长度相等的n个分组,返回data1数据的属于的各个分组) labels是分组后各组的名称. Right 和left 是报名左右边界是否包括,返回data1 属于的各个组别的名(labels)
>>>>分位数分组: Pd.qcut(data,q) 按照分为数进行分割分组,q = 4 按照四分位数分组,q也可以是列表,自己设定分位数
>>>>查看各个分组的范围:cat.categories。转化为列表形式: group.cat.categories.to_list()

>>>>分位数分组应用: 组合应用: 先使用p =pd.cut()或者p = pd.qcut() 进行分组,然后使用pd.value_counts(p)检查各组内的数值。 注:pd.cut 和pd.qcut 一般适用于Series
>>groupby方法:
按照分类的属性分类生成元组组成的列表,每个元组的第一个元素是分类属性的值,在下图中即为公司的名称,元组的第二个元素为公司名称为该公司的所有数据行的其他数据。
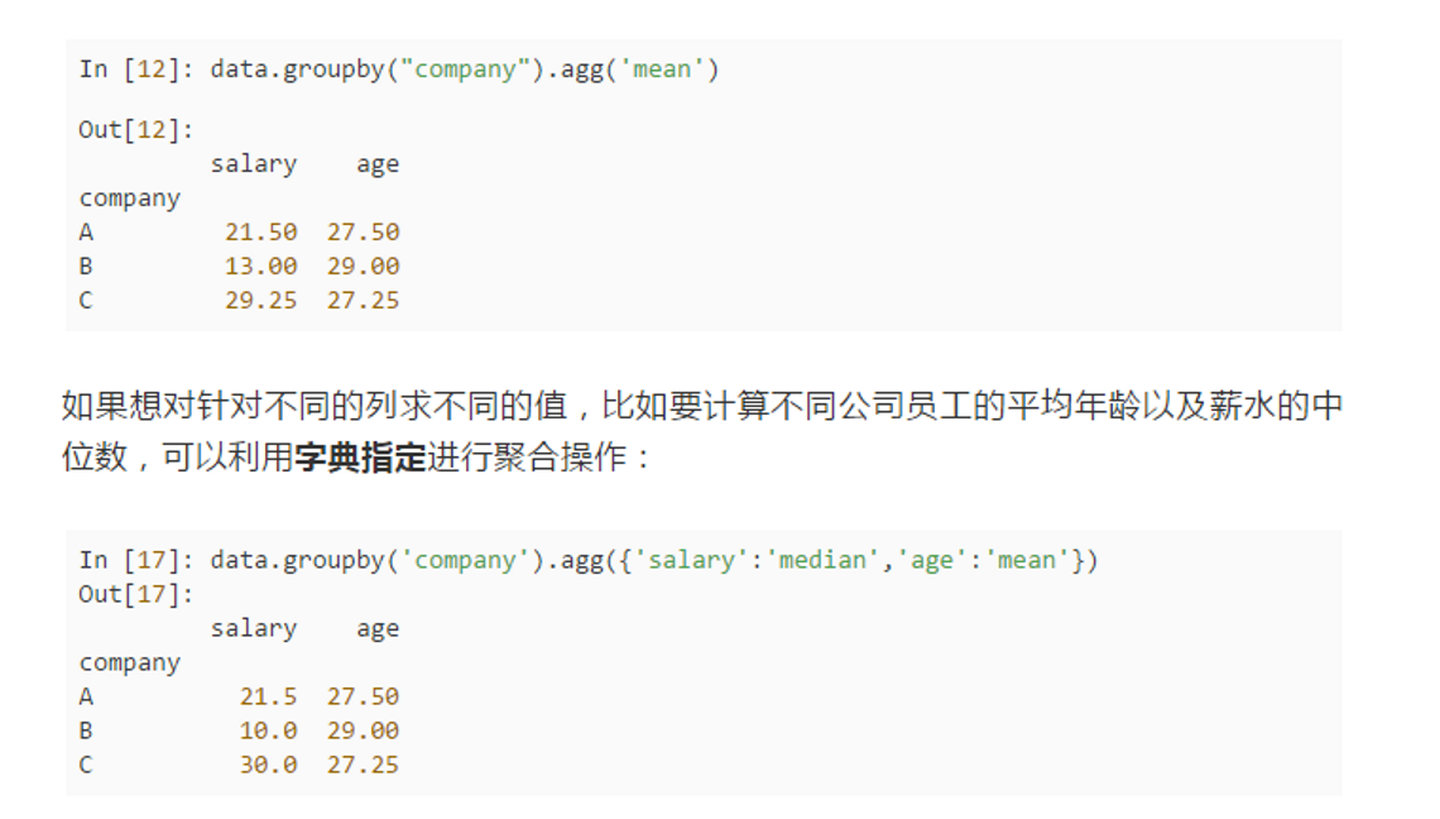
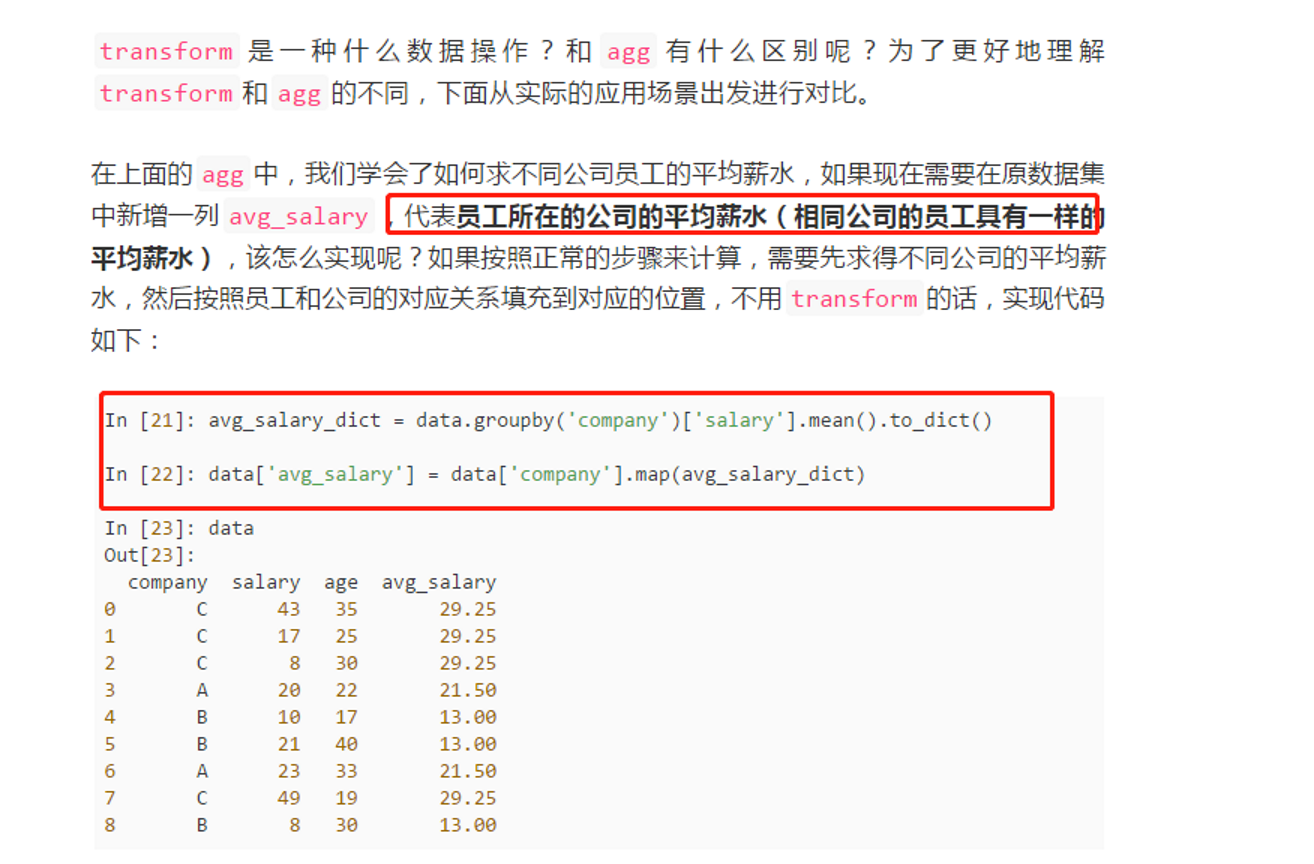
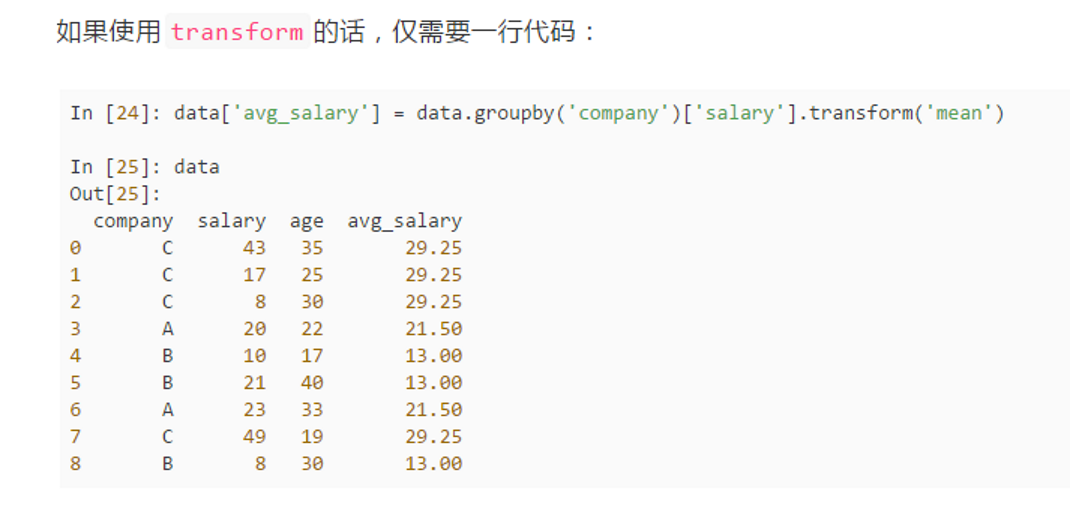
>>>>groupby后的agg和transform方法
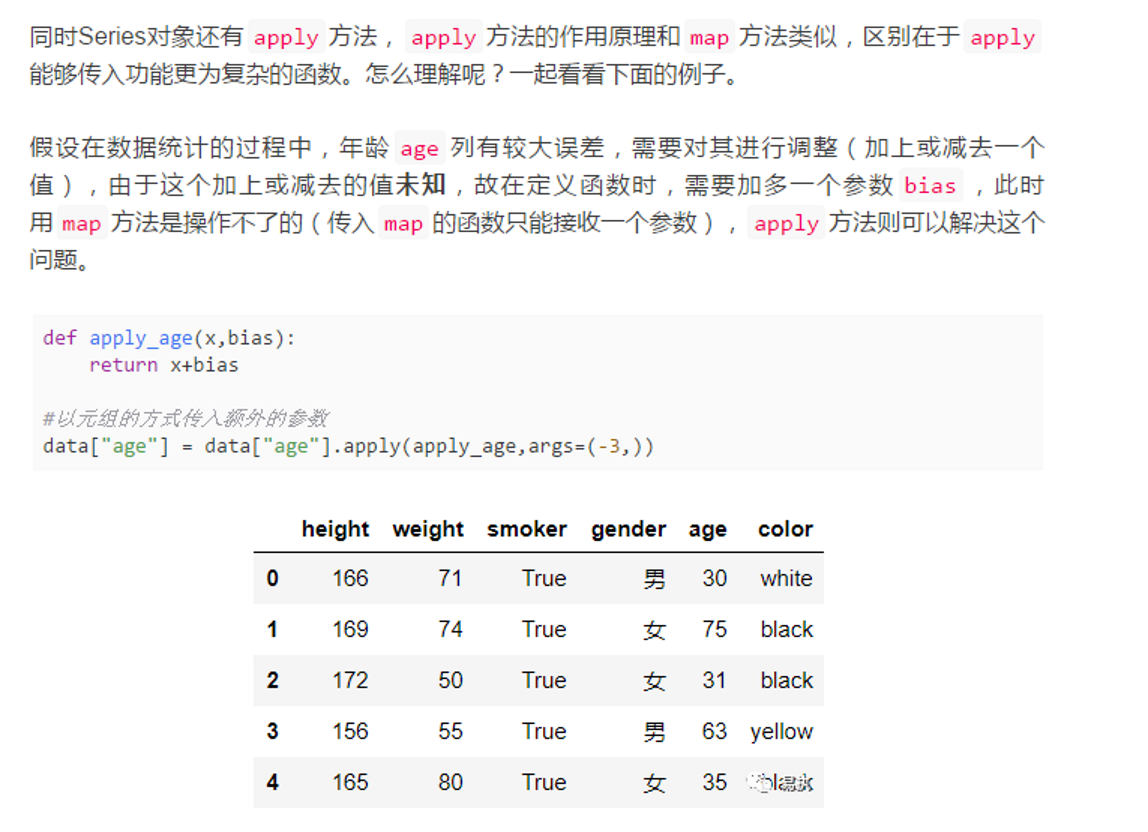
>>Map 方法、apply方法和applymap方法:
map方法的参数为一个字典,键值对表示进行相对应的替换数据

apply的参数为方法和方法对应的参数
Applymap方法应用于每个单元格,如果对dataframe的所有数据进行操作,则使用该方法,
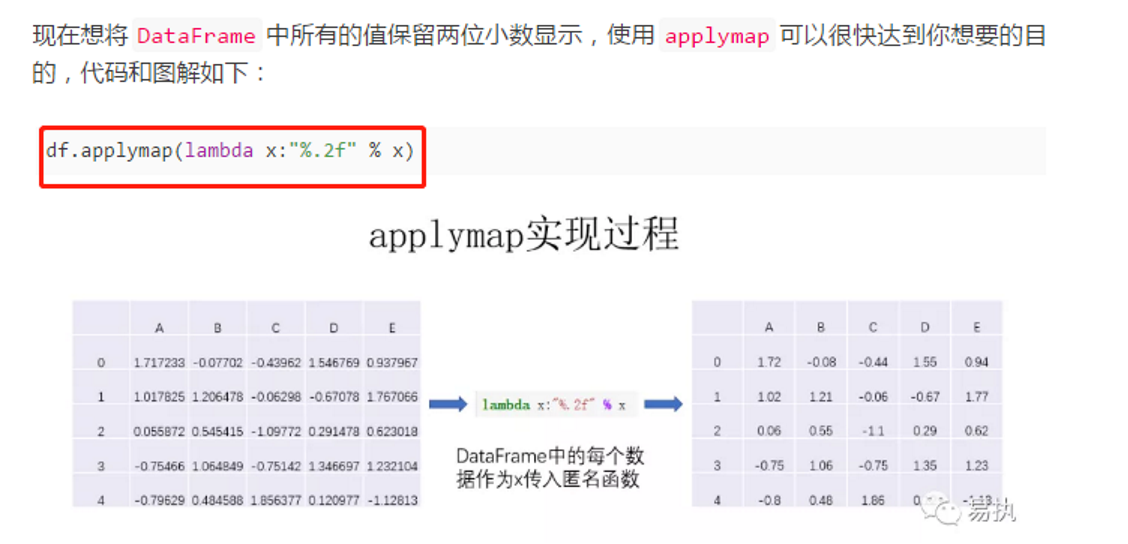
>>pandas数据选取操作:主要是使用iloc和loc
-
iloc方法的参数只能为数字,适用于选取第几行第几列,或者多行多列的位置的情况. Df.iat 适用于选取单个值,参数为第几行第几列的数字
-
loc方法的参数可以为只能为索引值和属性值,一般情况下索引值也为数字。Df.at 适用于选取单个值,参数为 列属性名和行索引值
>>插入行
1 )如果是在最后位置添加一行,则直接用frame.loc[index值],index是新的一行的行索引,注意必须使用loc,后面要跟参数行索引
2 )如果是在特定位置添加一行,则首先新建列表 l = list(frame.index),然后在最后位置插入数据frame.ix[index] = list or series 。然后 l.insert(weizhi, index) index即新插入行的行名,weizhi即要把index插入到第几个位置, 最后 frame.reindex(l) 即可得到数据
>>插入列
1 )如果是在最后位置添加,直接frame[属性名] = list or Series
2 )如果是在特定位置添加,则frame.insert(添加位置,‘属性名’,列数据),添加位置为数字索引,从0开始。列数据如果为列表 ,必须长度相等,如果为Series,也必须长度相等
>>删除重复行或列:
>>>>删除重复行 df.drop_duplicates(subset = [],keep = ,inplace = ) subset是指明哪几个列属性值相同时,删除重复的行,即Dataframe中的每一行是一条记录,代表一个数据集。如果默认为空,则删除所有列属性相同的两行中的一行。
>>>>删除重复列:df.T.drop_duplicates([]).T 先转置,然后删除重复行,再转置即可
>>查看缺失值
>>>>查看行列是否有缺失值:
行:df.isnull().any(axis = 1)
列:df.isnull().any(axis = 0)
>>>>查看行列有多少个缺失值:
列:Df.isnull().sum(axis = 0)
行:Df.isnull().sum(axis = 1)
>>数据合并
pd.merge参考:https://blog.youkuaiyun.com/Asher117/article/details/84725199
pd.concat参考: https://blog.youkuaiyun.com/Asher117/article/details/84799845
>>数据分组
>>>>Groupby对象的迭代遍历:
1: for value,groupdata in df.groupby(value)(对单个属性分组遍历)
2 for ( value1,value2 ) , groupdata in df,groupby([value1,value2]) (对多个属性分组的遍历)
>>>>groupby对象的agg方法
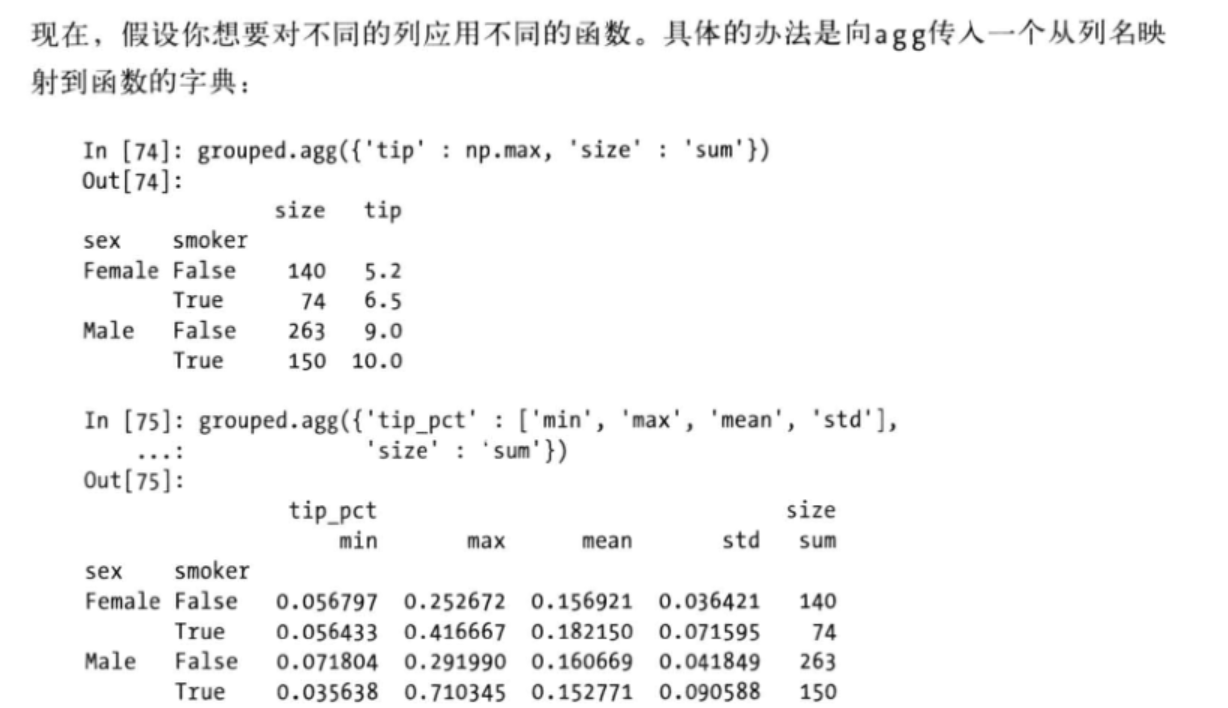
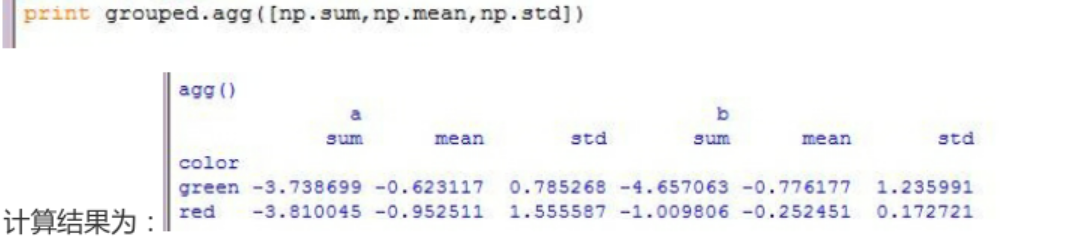
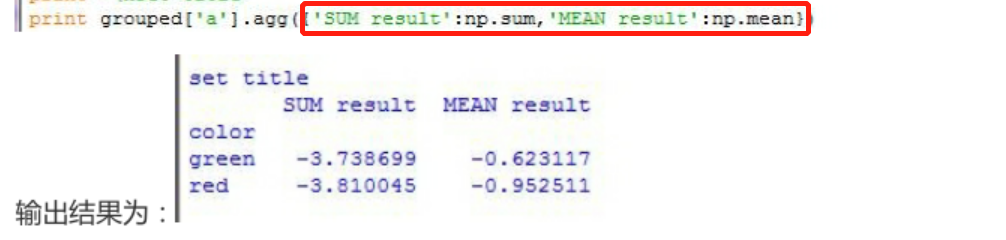
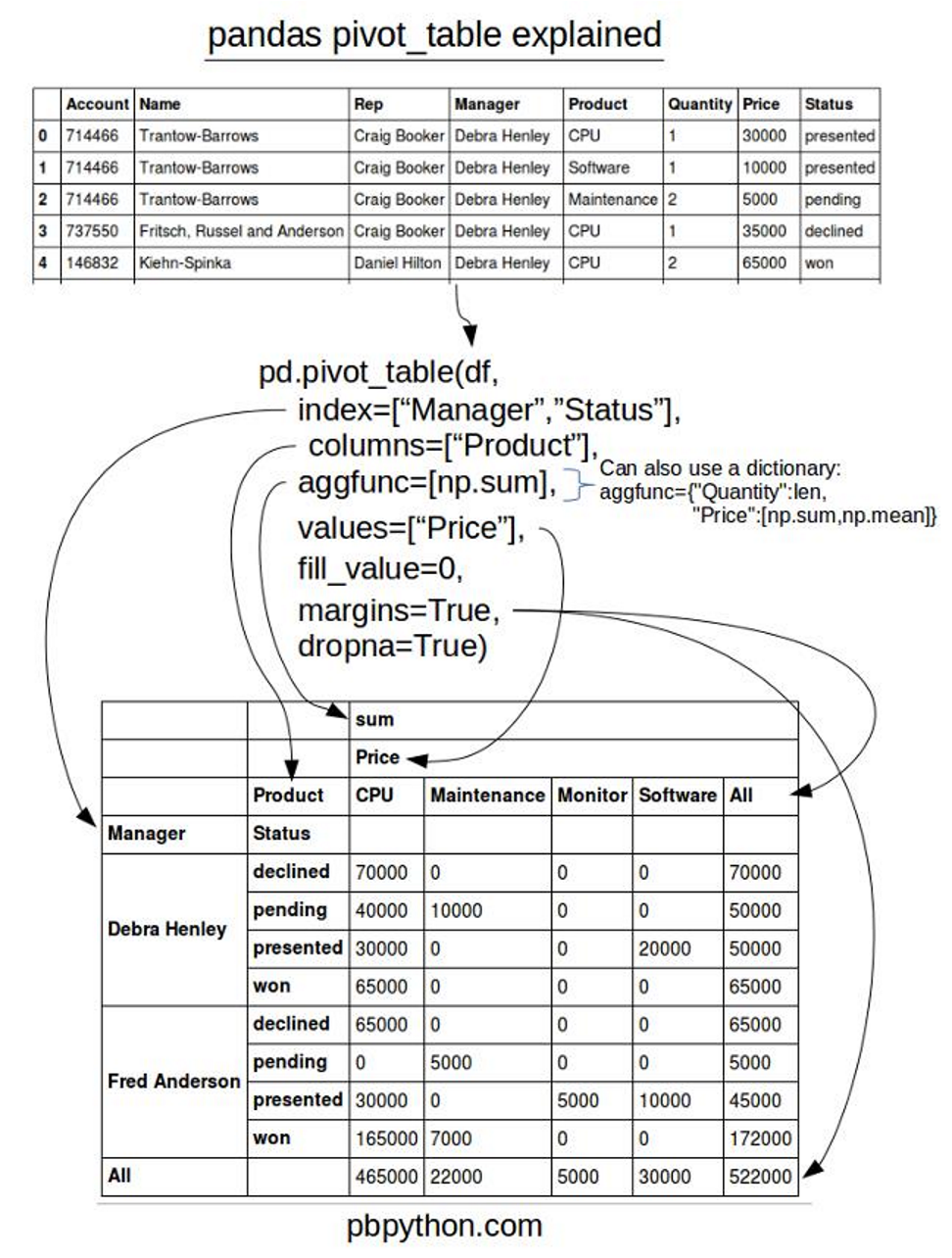
>>pivot_table:参考:
https://www.cnblogs.com/Yanjy-OnlyOne/p/11195621.html
https://www.cnblogs.com/onemorepoint/p/8425300.html
>>缺失值处理:
>>>>判断缺失值:判断某个具体数值是否为缺失值,pd.isna(),pd.isna()可以对math.nan np.nan和np.NAN都可以使用
参考: https://www.cnblogs.com/oceanicstar/p/10869725.html
>>>>处理方法参考:
https://blog.youkuaiyun.com/Katherine_hsr/article/details/80279963
https://blog.youkuaiyun.com/qq_42374697/article/details/108481645
>>排序:
>>>>简单排序:sortvalues和sort_index 参考: pandas 数据排序.sort_index()和.sort_values()
>>>>按照数值排序返回排序后的序号 rank:obj.rank(axis,method,ascending) 。返回的是各个元素按照一定顺序(ascending = True or False 升序或降序)排序后的每个元素的排名次序,最小的名次为1(在升序排名的情况下)。Method默认为平均排名,使用序列中存在相同元素时,相同元素的排名返回 所有相同元素排名的均值排名。 Method的其余参数(first、min、max都是适用于存在元素相同情况下,各个元素的排名)参数axis = 0(默认)是按照每列数值排序,axis =1 是按照每行数据排列然后返回排列后的名次(axis= 1 仅存在与dataframe情况下使用)

















 4289
4289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









