




最近在看文件上传&下载的相关知识,简单的做一下笔记
FIle & Blob 对象
浏览器中,文件通常以File对象的方式保存,File类继承自Blob类,Blob即 Binary Large Object 即 二进制大对象,表示一个存储二进制数据的对象。
Blob & File 对象一旦创建不能修改,你只能通过创建新的Blob & File对象的方式对其进行 "修改"
Blob&FIle对象也不能直接读取,你需要通过创建一个FileReader的对象,通过readAXXX的方式将其转换成其他类型之后才能读取。
const blob = new Blob(["hello wrold"])
const fileReader = new FileReader()
fileReader.readAsText(blob)
fileReader.onload = () => {
console.log(fileReader.result) // hello wrold
}需要注意,readAsXXX是个同步的函数,不返回任何值,你需要监听onload事件并且从 fileReader本身上获取解析后的内容。
fileReader 必须在完成一次转换之后(onload之后)才能开启下一次转换,但是一般建议每次转换一个blob对象都创建一个新的 FIleReader对象
你可以对FileReader进行简单的Promise封装
// 封装 fileReader
async function readBlob(blob) {
const fileReader = new FileReader()
fileReader.readAsText(blob)
return new Promise((resolve) => {
fileReader.onload = () => {
resolve(fileReader.result)
}
})
};
// 使用
(async function () {
console.log(await readBlob(blob))
})();fileReader 一般包含以下几种方法,都以 readAsType的方式命名,即把blob的内容转换为各种格式:
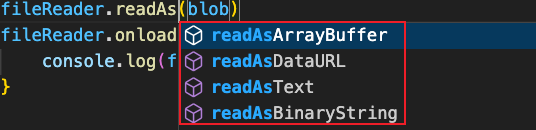
其含义分别为:
- readAsArrayBuffer: 转换成ArrayBuffer的形式,即原始的二进制数组的形式,每个数组项为一个字节。
- readAsText: 转换成 UTF-8 字符串
- readAsBinaryString: 把每个字节通过ASCII (0-255范围)的形式转换出来,你可以理解为把ArrayBuffer中每一项通过ASCII转换展示出来,对于本就是ASCII的内容,结果同ReadAsText
- readAsDataUrl: 把内容进行base64转码后返回
对于以下字符串
const blob = new Blob(["hello wrold 哈哈"])readAsArrayBuffer 的结果为:
ArrayBuffer(18) : [ 104, 101, 108, 108, 111, 32, 119, 114, 111, 108, 100, 32, 229, 147, 136, 229, 147, 136 ];
hello world 哈哈 长度为 18字节,一个中文占3个字节
readAsText结果为: "hello wrold 哈哈"
readAsBinaryString结果为: "hello wrold åå" 可以看到,对于 hello world 由于其本就是ASCII的内容,所以转换结果和readAstext一样,但是对于 哈哈 中文,转换到 ascii区间就是乱码
readAsDataURL 转换的结果为base64字符串:
"data:application/octet-stream;base64,aGVsbG8gd3JvbGQg5ZOI5ZOI"
说了半天Blob,其实File本质就是Blob对象,只不过在继承Blob的基础上,增加了文件名称,修改时间等描述信息。
可以看到,file的创建,也要比blob增加文件名称的参数
const f = new File(['hello world 哈哈'],'myFile.txt')
const b = new Blob(['hello world 哈哈'])
console.log('file',f)
console.log('blob',b)
其区别如下:

File对象的获取
file对象一般有两类获取方式,一种就是我们上面说的用 new File([content],name)的方式创建
一种是通过用户选择文件获取
我们知道,出于安全考虑 Javascript 在浏览器中是跑在沙箱内的,其无法直接读写宿主机的文件系统,如果需要上传文件,需要给用户提供一个文件选择框,让用户选择授权之后,才能拿到文件数据。
一般情况下,我们可以通过 Input 选择框 或者 区域拖拽的方式 获取用户选择的文件
Input框获取文件
最常用的方式,我们可以使用 <Input type="file"/> 的方式生成一个文件选择框,如图
<input type="file" id="base-upload" />如果想上传多个文件,通常加入 multiple属性
<input type="file" id="multiple-upload" multiple />效果如图所示:
![]()
我们需要通过设置input的onchange函数,监听文件的上传操作 如下:
const baseUplaoder = document.getElementById('base-upload')
baseUplaoder.onchange = () => {
console.log(baseUplaoder.files)
}
const muliUploader = document.getElementById('multiple-upload')
muliUploader.onchange = () => {
console.log(muliUploader.files)
}可以看到,通过Input.files 即可获得选择的文件数组 [单一文件模式也是数组]

设置内容拖拽区域
第二种方式就是设置一个内容拖拽区域,并且禁用其 dragover drop的浏览器默认事件,我们知道,当你拖拽一个文件到浏览器中,其默认操作就是下载当前的文件,我们需要禁用这个操作,才能获取当前拖拽的内容。
我们可以在drop事件中,读取 event.dataTransfes.files的方式,获取文件对象
<div id="drag-upload" style="width:300px;height:200px;border:2px dashed #aaa;line-height:200px;text-align:center;">
拖拽文件到此区域上传
</div>
<script>
//如果不阻止 dragover,浏览器压根不让你放文件,直接下载。
dragUplaoder.addEventListener('dragover', (e) => {
e.stopPropagation()
e.preventDefault() // 阻止默认行为 【浏览器打开文件】
})
dragUplaoder.addEventListener('drop', (e) => {
e.stopPropagation()
e.preventDefault() // 阻止默认行为 【浏览器打开文件】
console.log(e.dataTransfer.files);
})
</script>效果如下:
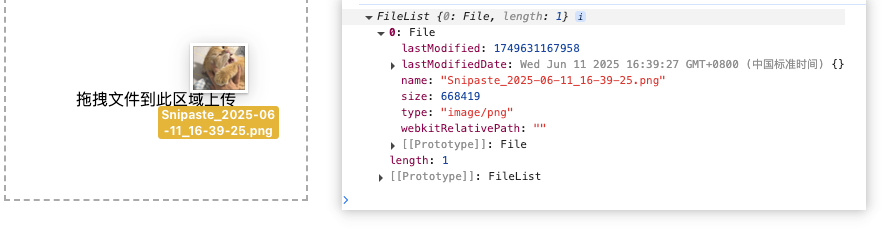
通过这两种方式,我们就可以获取文件系统中的文件。
需要注意一个区别
当我们使用 File选择的方式获取用户文件系统中的文件时,File对象只会保存文件的基本信息,文件的内容还是保存在文件系统中,不读取到内存中,也就是说,再大的文件,用户选择完都不会读取到内存中去。
当使用 new File / new Blob 的方式创建时,其内容都保存在内存中,只有当发起下载的时候,才能写入到文件系统中。
所以需要注意, new File的方式,不能保存太大的数据,否则浏览器的内存会爆满。
文件的上传格式
http请求携带请求体的时候,通常会在请求头中携带 Content-Type字段,表示当前请求体内容类型的MIME Type
上传文件的时候,我们通常使用以下两种MIME TYPE
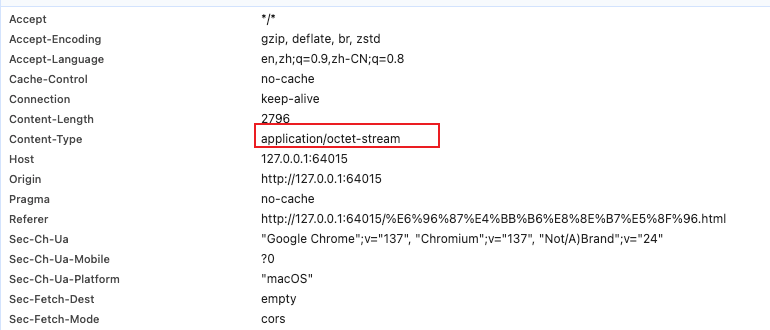
application/octet-stream 八位二进制流
application/octet-stream 标准 MIME 类型,代表任意二进制数据流
octet指的是 8 位字节 这个MIME TYPE表示请求体的内容是纯二进制,服务器接收到请求后看到其Content-Type是该属性,就可以调用对应处理纯二进制文件的方法进行处理了。
multipart/form-data
这是表单上传常用的一种MIME TYPE
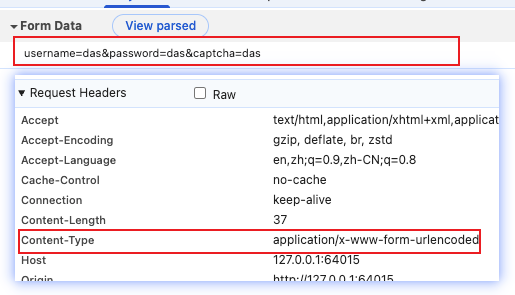
默认情况下, 当我们创建一个表单上传的请求,其默认的Content-Type 为:
application/x-www-url-encoded 也就是使用 ? a=xxx & b = xxx 的编码形式 [ url -encoded ] 将内容保存在请求体内,注意 这个是在请求体内,虽然和url采用类似的编码方式,但是其存储位置不在url中,也没有url的ASCII编码限制。
<form method="POST" action="/login">
<input name="username"></input>
<input name="password"></input>
<input name="captcha"></input>
<button type="submit">Submit</button>
</form>默认情况下的表单发送Post请求,可以看到其Content-Type和body内容的编码形式,如下
url-encoded的编码方式很简单,但是问题就是无法携带文件,只能携带内容比较少的文本文件。
当我们把文件选择加入表单,就会发现,其最终url-encoded编码携带的文件内容只有文件的名称,因为文件内容无法使用url-encoded的方式编码
<form method="POST" action="/login">
<input name="username"></input>
<input name="password"></input>
<input name="captcha"></input>
<button type="submit">Submit</button>
</form>如下,只带了文件的名称,无内容

为什么url-encoded无法携带文件?
我们知道 url中无法携带非ASCII的数据,对于非ASCII的数据,我们通常会用
encodeUriComponent方法对其进行 百分号编码。 百分号编码用三个字节的ASCII表示一个被编码的字节,这就导致其效率低下。
对于很大的二进制文件,使用该方式编码,会使请求携带数据的效率低下 ,所以当下的浏览器普遍不支持用 application/x-www-uri-encoded方式携带二进制文件。
为了解决 application/x-www-url-encoded无法携带文件的问题,出现了formData的编码格式
如果需要携带文件内容,就需要设置entrypt="multipart/form-data" 如下
<form method="POST" enctype="multipart/form-data" action="/login">
<input name="username"></input>
<input name="password"></input>
<input name="captcha"></input>
<input name="file" type="file" id="base-upload" />
<button type="submit">Submit</button>
</form>可以看到,其Content-type: multipart/formData; boundary= XXXXXXX
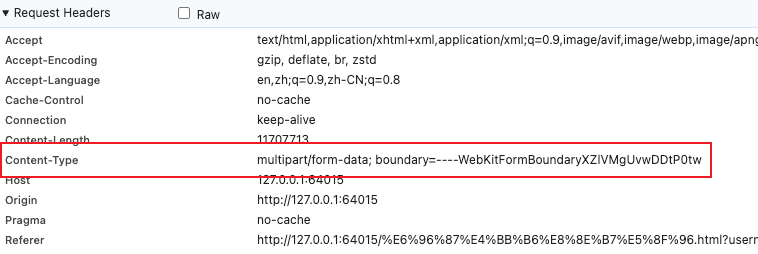
Boundary是什么意思? 我们可以观察一下请求体的内容:
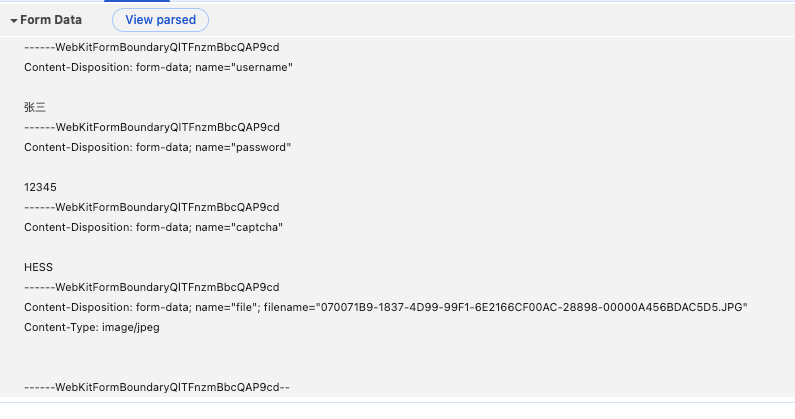
可以看到,ContentType中的boundary就是作为请求体内分割每块内容的分割线,每个区域内部,包含Content-Dispostion , name ,如果是文件 还有 filename 以及文件的Content-Type 如下
----------------- Boundary -----------------
Content-Disposition: form-data; name=username
用户名内容
----------------- Boundary -----------------
Content-Disposition: form-data; name=password
密码内容
----------------- Boundary -----------------
Content-Disposition: form-data; name=captcha
验证码内容
----------------- Boundary -----------------
Content-Disposition: form-data; name=file; filename="文件名称"
Content-type: image/jpeg
文件二进制内容...
----------------- Boundary -----------------用这种方式,就能分割多个区域,并且把文件的二进制数据单独放在一个boundary包围的区域内上传。同时文件以外的文本内容也可以携带,服务器只需要通过 header中的 Content-Type的边界boundray内容,就可以切分请求体,解析出表单的key value。
手动创建FormData
除了使用表单自动发送FormData,你也可以手动的创建FormData对象并且发送。这就让我们上传文件更为灵活。如下:
const baseUplaoder = document.getElementById('base-upload')
baseUplaoder.onchange = () => {
const formData = new FormData()
formData.set('fileHash', 'WIUDSJIOJWOKQJWUDGH#&*DUWD')
formData.set('fileContent', baseUplaoder.files[0])
fetch('/upload', {
method: 'POST',
body: formData
});
}我们使用 FormData类,实例化一个formData对象出来,通过set(name, value)的形式即可把文件类型的value传入formData对象里。
如上例子,将Input读取到的File对象存入formData,并且将整个formData对象作为body发出,此时不需要设置header中的Content-Type , fetch会自动设置其类型为 multipart/form-data 并且自动设置分割线。
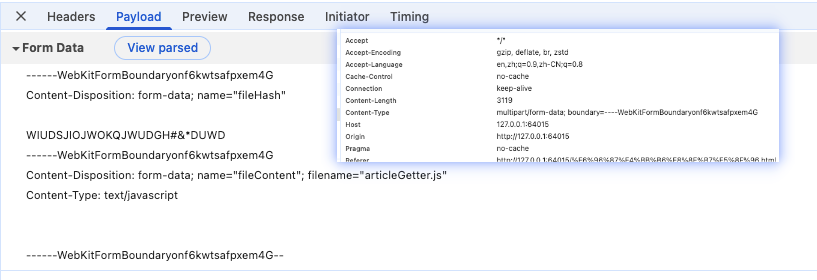
在服务端,通过检查Content-Type类型,并且对formData格式进行拆分即可,比如nodejs中可以使用 formidable 等。
如何选?
一般情况下, application/octet-stream 用在请求体只携带一个二进制文件的情况,而multipart/form-data通常用于还要携带其他数据的情况,比如表单中需要上传一个文件,比如大文件切分上传,处了携带文件chunk本身,还需要携带文件的索引号Index。
文件下载
我们知道,浏览器是不允许Javascript直接访问文件系统的,所以一般我们下载文件,都是借助浏览器来帮我们创建一个下载任务,而不是通过Js直接将数据写入文件系统。
浏览器提供的下载方式一般有两种 一个是通过window.open的方式,一个是通过a标签并且设置href为下载的地址,用户点击a标签之后即可下载。
<a href="data:application/octet-stream;base64,aGVsbG8gd3JvbGQg5ZOI5ZOI">download</a>
window.open("data:application/octet-stream;base64,aGVsbG8gd3JvbGQg5ZOI5ZOI")Content-Disposition
服务器返回的响应头中,一般会携带这个字段,这个字段的作用是告诉浏览器,当前请求体的内容是直接在浏览器内展示,还是作为附件下载。
默认情况下,comtent-dispoition: inline 当我们下载一个pdf或者图片这些浏览器可以展示的资源时,如果响应头不设置该字段或者设置为 inline,那么浏览器会自动打开并且展示pdf或者图片资源的内容。
如果我们需要强制下载,就需要使用
content-disposition: attachment; filename = "Encoded File Name"的方式, 表示当前内容的处理方式是作为附件的形式下载。
当我们使用 window.open 打开链接并且下载的时候,就会自动以filename作为文件名称下载。
如果你想下载的时候不用Content-Disposition的filename 或者响应头中就没有提供content-disposition, 那么可以使用a标签的 download属性,强制把响应体作为附件下载,并且自定义下载文件的名称,如下:
<a href="data:application/octet-stream;base64,aGVsbG8gd3JvbGQg5ZOI5ZOI" download="rename.txt">download</a>Javascript下载文件
除了使用浏览器提供的下载方式,Javascirpt也可以通过Ajax请求获取文件的请求体内容,如下:
async function readFile() {
const response = await fetch(
`/download`,
{ method: "GET" }
);
const reader = response.body.getReader()
let fileChunks = []
while (1) {
const { done, value } = await reader.read()
if (done) {
// 读取完成
const fileBlob = new Blob(fileChunks)
const objectUrl = URL.createObjectURL(fileBlob)
window.open(objectUrl)
break;
} else {
fileChunks.push(value)
}
}
}这种方式通过 fetch方法获取到响应头 response,fetch区别于XHR的实现方式是,其可以不在相应体完全发送回来之后才决策,而是在相应头发送回来后,就可以决策了。
后续可以通过 res.body 获取到一个ReadableStream流,并且通过流的方式渐进式的获取数据。
stream.getReader获取到reader对象,reader上存在read方法,其本质上是个异步的生成器函数,每次调用都会返回一个Promise,Promise决策之后会返回一个 { done, value }对象,包含是否读取完成以及读取到的内容。
使用while循环调用read,read的value是一个UInt8Array类型,也就是一个8位二进制作为一个字节的数组,我们每次将这个数组推入到一个chunks数组内,在读取完成后,chunks数组的内容应该为: chunks [ UInt8Array, UInt8Array, UInt8Array ...]
将其传递个Blob的构造函数,即可组合这些UInt8Array成一个Blob对象,这个对象可以使用
URL.createObjectUrl( blob ) 的方式,创建一个临时的下载链接,将其传入a标签或者window.open 即可完成下载!
这种方式的好处是可以实现流式下载,我们甚至可以对其进度进行监控,如下:
async function readFile() {
const response = await fetch(
`/download`,
{ method: "GET", headers, signal: controller.signal }
);
// 获取相应体总长度
const contentLength = response.headers.get('content-length') || 0
// 定义已经接受的长度
let loaded = 0
const reader = response.body.getReader()
let fileChunks = []
while (1) {
const { done, value } = await reader.read()
if (done) {
// 读取完成
const fileBlob = new Blob(fileChunks)
const objectUrl = URL.createObjectURL(fileBlob)
window.open(objectUrl)
break;
} else {
fileChunks.push(value)
loaded += value.length
console.log("当前进度为 : "+ 100* (loaded / contentLength) + '%')
}
}
}
这种方式看上去很好,但是有巨大的隐患,我们上面说过,通过javascript下载的方式实际上是要将文件保存在内存中的,也就是fileChunks的内容。 如果文件很大 几十G 几百G 浏览器根本没有那么大的内存来存储这些数据。
但是,使用浏览器直接下载的方式,比如a标签或者window.open的方式,浏览器就仅仅作为一个中间人,下载的数据会直接通过浏览器转交给文件系统,浏览器本身不会存储文件内容,不会占用内存。
所以,如果你需要下载的文件很大, 建议你还是触发浏览器的下载行为,不要让Js参与。
fileSaver 下载文件
或许你会问,啊? 按你这么说,如果我想用JS监听文件的下载进度,展示在页面上,又担心文件很大 咋办?
这就要用 fileSaver这个库了,fileSaver的原理其实很简单,其本质上是创建了一个Service Work进行数据中转,你可以理解Service Worker为一个在浏览器内部的代理服务器。
我们在下载开始前创建一个Service Worker 同时创建一个隐形的 iframe对象,将其url指向这个service Worker 相当于让iframe请求 Service Worker的数据。
iframe本质上也是个浏览器页面,所以其会触发浏览器默认的下载行为。
但是,我们可以在拿到数据之后,先计算一下进度,再发送给 service worker , service worker 再发送数据给iframe的下载任务,这样一层中转之后,我们就达到了用Js拦截下载过程的目的。
我们可以通过NPM或者CDN的方式,获取 file-saver - npm
使用方式也很简单,如下:
// 创建filesaver的writableStream
const writeStream = streamSaver.createWriteStream(name, {
size: totalSize,
});
// 获取writer
const writer = writeStream.getWriter()
// 写入数据
writer.write(data)
// 写入完成 关闭writer 完成下载
writer.close() 改造我们前面的例子,如下
async function readFile() {
const response = await fetch(
`/download`,
{ method: "GET", headers, signal: controller.signal }
);
// 获取相应体总长度
const contentLength = response.headers.get('content-length') || 0
const contentDisposition = response.headers.get('content-disposition')
const filename = /filename="?([^"]+)"?/.exec(contentDisposition)[1]
// 创建writableStream
const writableStream = filesaver.createWriteStream(filename,{
size: contentLength
})
// 创建writer
const writer = writableStream.getWriter()
// 定义已经接受的长度
let loaded = 0
const reader = response.body.getReader()
while (1) {
const { done, value } = await reader.read()
if (done) {
// 读取完成
writer.close()
break;
} else {
writer.write(data)
loaded += value.length
console.log("当前进度为 : "+ 100* (loaded / contentLength) + '%')
}
}
}就可以达到,触发浏览器下载行为的同时 触发监听下载状态。
当然了,文件的上传下载还要考虑很多东西 比如大文件的切片下载上传,断点续传,秒传的问题,后面有时间我再写一篇笔记

















 3656
3656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









