






 本文介绍了由Kaiming团队提出的Focal Loss,一种旨在解决分类问题中类别不平衡及分类难度差异的损失函数。作者探讨了其在NLP领域的应用潜力,并通过与一个自定义的硬截断损失函数进行比较,揭示了Focal Loss的独特之处。
本文介绍了由Kaiming团队提出的Focal Loss,一种旨在解决分类问题中类别不平衡及分类难度差异的损失函数。作者探讨了其在NLP领域的应用潜力,并通过与一个自定义的硬截断损失函数进行比较,揭示了Focal Loss的独特之处。
前言
今天在 QQ 群里的讨论中看到了 Focal Loss,经搜索它是 Kaiming 大神团队在他们的论文Focal Loss for Dense Object Detection 提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。
本质上讲,Focal Loss 就是一个解决分类问题中类别不平衡、分类难度差异的一个 loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:如何评价 Kaiming 的 Focal Loss for Dense Object Detection?[1]
看到这个 loss,开始感觉很神奇,感觉大有用途。因为在 NLP 中,也存在大量的类别不平衡的任务。
最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好 loss。
接着我再仔细对比了一下,我发现这个 loss 跟我昨晚构思的一个 loss 具有异曲同工之理。这就促使我写这篇文章了。我将从我自己的思考角度出发,来分析这个问题,最后得到 Focal Loss,也给出我昨晚得到的类似的 loss。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
硬截断
整篇文章都是从二分类问题出发,同样的思想可以用于多分类问题。二分类问题的标准 loss 是交叉熵。
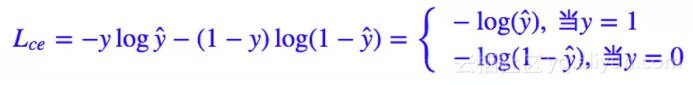
其中 y∈{0,1} 是真实标签,ŷ 是预测值。当然,对于二分类我们几乎都是用 sigmoid 函数激活 ŷ =σ(x),所以相当于:
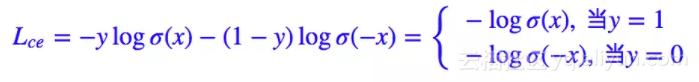
我们有 1−σ(x)=σ(−x)。
我在上半年写过的文章「文本情感分类(四):更好的损失函数」[2]中,曾经针对“集中精力关注难分样本”这个想法提出了一个“硬截断”的 loss,形式为:
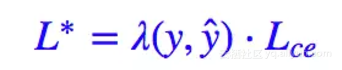
其中:

这样的做法就是:正样本的预测值大于 0.5 的,或者负样本的预测值小于 0.5 的,我都不更新了,把注意力集中在预测不准的那些样本,当然这个阈值可以调整。这样做能部分地达到目的,但是所需要的迭代次数会大大增加。

















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









