




 该研究探索了如何有效微调BERT模型以提升文本分类性能。通过任务内预训练、领域内预训练和多任务微调等策略,以及处理长文本、选择层特征和避免灾难性遗忘的技术,实验结果显示这些方法能显著改善模型效果。在多个英文和中文文本分类任务中,这些优化策略达到了SOTA水平。
该研究探索了如何有效微调BERT模型以提升文本分类性能。通过任务内预训练、领域内预训练和多任务微调等策略,以及处理长文本、选择层特征和避免灾难性遗忘的技术,实验结果显示这些方法能显著改善模型效果。在多个英文和中文文本分类任务中,这些优化策略达到了SOTA水平。
简介
How to Fine-Tune BERT for Text Classification
这篇论文主要研究了如何在文本分类任务最大化发掘BERT模型的潜力,探索了几种微调BERT的方案。
- 提供一种常规的微调BERT的解决方案:(1)在任务内数据或者领域内数据进一步预训练BERT;(2)在多个相关任务上进行多任务微调BERT;(3)在目标任务上微调BERT。
- 探索了在目标任务上微调BERT的方法,包含:长文本预处理、层向量的选择、层调节的学习率、灾难性遗忘和小样本学习。
- 在7个广泛学习的英文文本分类任务和一个中文新闻分类数据集实现了SOTA
方法论
黑、蓝、红三种颜色的线代表三种微调BERT的方案。
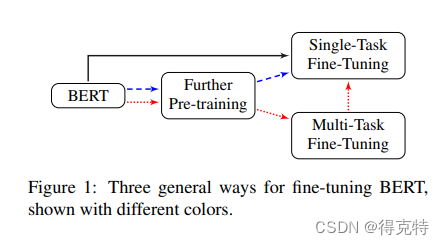
微调策略
长文本预处理、目标任务选择哪一层、优化算法、学习率。
不同层的神经网络可以捕捉不同的句法和语义特征。
进一步预训练
在目标任务领域进一步预训练BERT,考虑到不同领域的数据分布不同,因此可以考虑在指定领域预训练BERT:
- 在目标任务训练集预训练BERT
- 在于目标任务相同领域的数据集预训练BERT
- 交叉领域训练,在目标任务领域和其他领域预训练BERT
多任务预训练
多任务学习有助于探索不同任务的共享知识。所有的任务共享BERT层和编码层,只有最后的分类层不同
实验1结果
超参数:
超参数
参数
模型
BERT-base
隐藏层大小
768
层数
12
\begin{array}{c|c} \hline \text{超参数} & \text{参数} \\ \hline \text{模型} & \text{BERT-base}\\ \text{隐藏层大小} & 768 \\ \text{层数} & 12 \\ \hline \end{array}
超参数模型隐藏层大小层数参数BERT-base76812
预训练超参数
超参数
参数
batch size
32
输入最大长度
128
学习率
5
e
−
5
train steps
10000
warm-up steps
1000
优化器
Adam
β
1
0.9
β
2
0.999
dropout-probability
0.1
\begin{array}{c|c} \hline \text{超参数} & \text{参数} \\ \hline \text{batch size} & 32 \\ \text{输入最大长度} & 128 \\ \text{学习率} & 5e-5 \\ \text{train steps} & 10000 \\ \text{warm-up steps} & 1000 \\ \text{优化器} & \text{Adam} \\ \beta_1 & 0.9 \\ \beta_2 & 0.999 \\ \text{dropout-probability} & 0.1 \\ \hline \end{array}
超参数batch size输入最大长度学习率train stepswarm-up steps优化器β1β2dropout-probability参数321285e−5100001000Adam0.90.9990.1
微调参数
超参数
参数
batch size
24
学习率
2.5
e
−
5
warm-up proportion
0.1
优化器
Adam
β
1
0.9
β
2
0.999
dropout-probability
0.1
epoch
4
\begin{array}{c|c} \hline \text{超参数} & \text{参数} \\ \hline \text{batch size} & 24 \\ \text{学习率} & 2.5e-5 \\ \text{warm-up proportion} & 0.1 \\ \text{优化器} & \text{Adam} \\ \beta_1 & 0.9 \\ \beta_2 & 0.999 \\ \text{dropout-probability} & 0.1 \\ \text{epoch} & 4 \\ \hline \end{array}
超参数batch size学习率warm-up proportion优化器β1β2dropout-probabilityepoch参数242.5e−50.1Adam0.90.9990.14
长文本处理(Dealing with long texts)
截断方案
- 保留前510个字符
- 保留后510个字符
- 保留前128和后382个字符
多项式方案
- 将输入文本划分为 k = L / 510 k=L/510 k=L/510部分,分别计算 [ CLS ] [\text{CLS}] [CLS]特征向量的然后采用mean pooling、max pooling、self-attention组合各个特征向量。
效果如下:
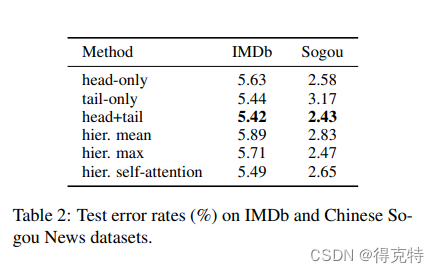
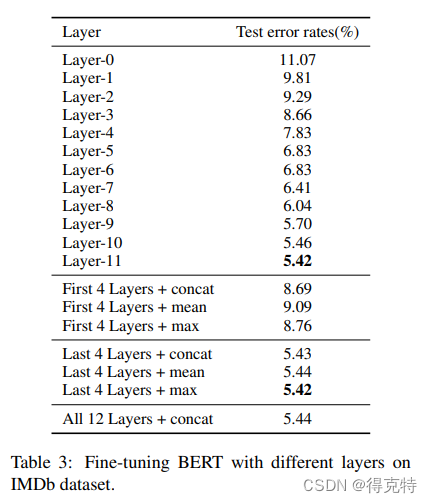
选择某层的特征(Features from different layers)
实验表明,对于分类任务,最后一层或最后四层取max的效果最优。
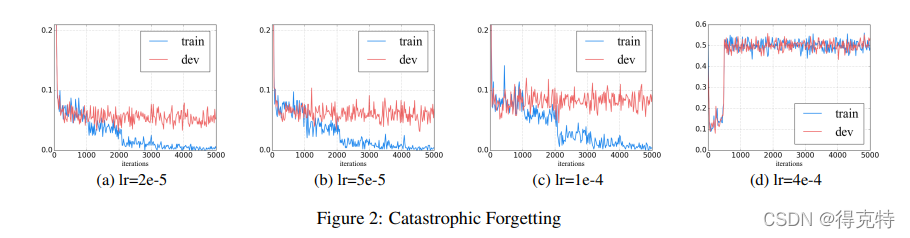
灾难性遗忘(Catastrophic Forgetting)
灾难性遗忘是指预训练模型在学习新知识的过程,预训练的知识会消退的现象。
作者发现,采用一个较小的学习率例如
2
e
−
5
2e-5
2e−5可以使BERT克服灾难性遗忘问题;采用学习率
4
e
−
5
4e-5
4e−5训练集不能收敛。
逐层衰减的比率(Layer-wise Decreasing Layer Rate)
设置一个基础学习率和逐层衰减的系数,作者发现,低层的网络适合较低的学习率。
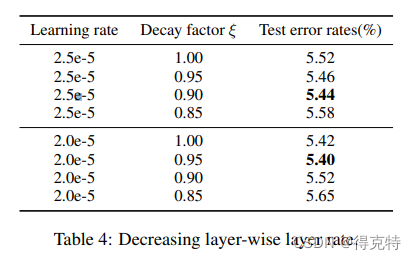
实验2结果
任务内数据预训练(Within-Task Further Pre-Training)
为了探索任务内学习的有效性,在任务内数据集预训练了不同step,然后再分类任务上微调。
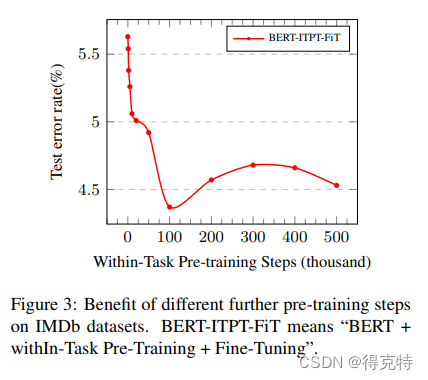
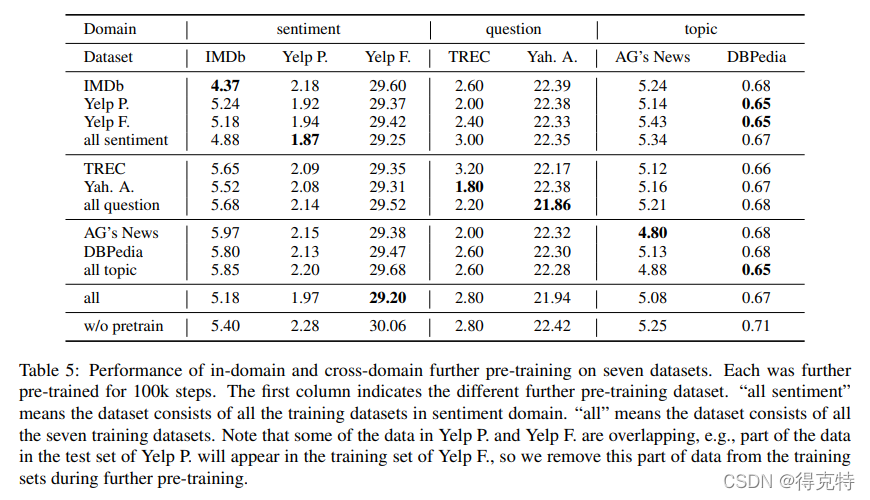
领域内和交叉领域进一步预训练(In-Domain and Cross-Domain Futher Pre-training)
作者将英文数据集分为topic、sentiment、question三个领域。
- 几乎所有的预训练任务都优于直接微调BERT。
- 领域内的预训练相比于任务内的预训练效果更优。
- 交叉领域的预训练并未带来整体的效果提升。
与之前模型的效果比较
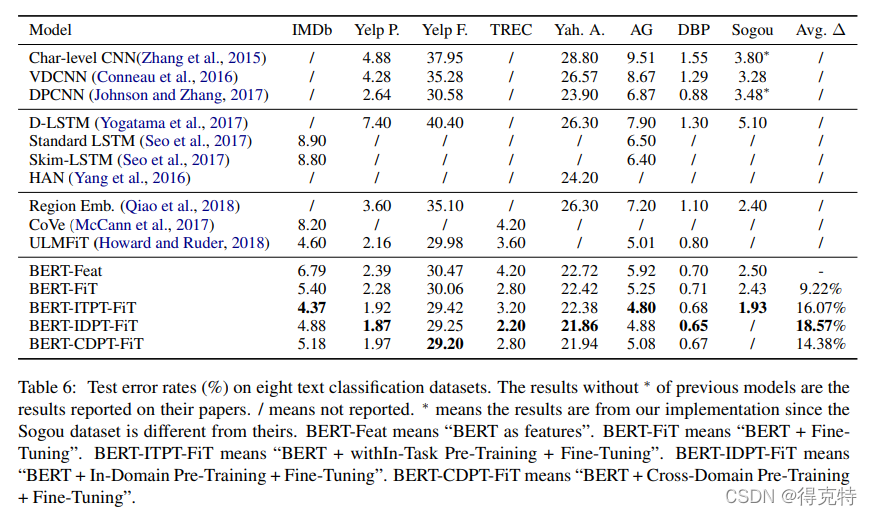
实验3结果
多任务微调(Multi-task Fine-Tuning)
多个任务共享BERT编码层,每个单一任务只有分类层不同。
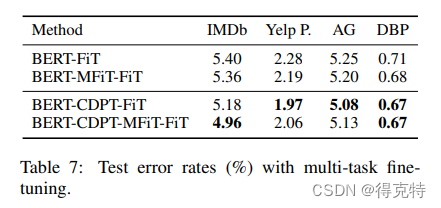
实验4结果
小样本学习
预训练在0.4%的训练样本,将test error rate从17.26%降到9.23%。
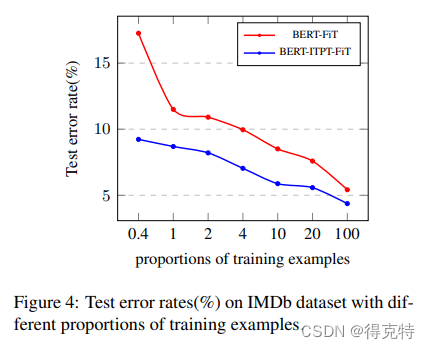
实验5结果
进一步预训练BERT Large
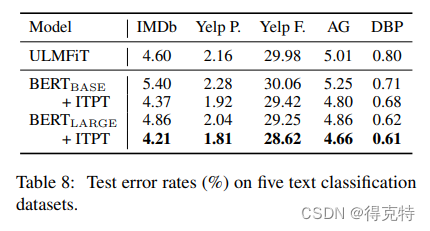
结论
- BERT顶层的特征向量对于分类任务是最优的。
- 按层衰减的学习率可以克服灾难性遗忘问题。
- 任务内和领域内预训练能显著提升效果。
- 单一任务微调前增加一个多任务微调也有提升,但提升程度不如预训练。
- BERT可以提升小样本学习的效果。

















 7016
7016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









