




 本文提出一种新的meta-learning方法,从人类视频中学习技能,解决了系统域唯一的问题和数据需求大的问题。通过学习丰富的先验知识,机器人能从人类示范中快速学习新技能。
本文提出一种新的meta-learning方法,从人类视频中学习技能,解决了系统域唯一的问题和数据需求大的问题。通过学习丰富的先验知识,机器人能从人类示范中快速学习新技能。
-
1. Introduction
- 人类和动物仅仅通过观察别人就能掌握行为的要点,并且能够对形态,背景,和任务细节的变化相当鲁棒。并且人类需要非常少量的示范就可以学会。机器如何获取这种能力?
- 解决“基于视觉输入的skill学习”有两个问题:(1)人类示范和机器人之间的“外貌和行为差异”引入了一个“系统域唯一的问题”,即对应问题。(2)从视觉输入进行学习需要大量的数据。本文中,我们使用meta-learning方法解决了上述两个问题:只从人类的视频数据进行学习。在meta-training阶段,获取了丰富的先验知识。机器人根据这些知识学习:“如何从人类进行学习”。在meta-training后,机器人将先验知识同一个人类演示结合起来,从而获取新的skills。
-
2. Related work
-
3. Preliminaries
- 提出了一种“基于模型不可知的meta-learning算法”的扩展,解决了:provided data和evaluation setting 之间的domain shift 问题。
- Meta-learning目的是快而有效的学习新任务。训练数据来自于一组广泛的meta-learning任务,评估时使用一组新的meta-test任务。meta-learning中假设meta-learning和meta-test采样自相同的分布p(T )。meta-learning可以看做是探索“众多tasks之间存在的结构”,当给出一个新的meta-test任务时,agent可以结合已知的结构快速学习。MAML实现了这一点,具体方式是:优化神经网络的初始参数,使得在几个数据点上进行一个或几个梯度下降步骤,就可以得到有效的泛化。经过meta-training之后,参数根据新的任务进行微调。
- 具体的,考虑一个监督学习问题:损失函数是L(θ, D),θ是模型参数,D是标注好的训练数据。对于小样本学习问题,MAML只能访问许多任务中的小部分数据。在meta-training过程中,对来自任务的数据进行采样,数据分成两个集合Dtr和Dval。假设Dtr有k个样本。MAML优化模型参数θ,使得在Dtr执行几个梯度步骤就可以在Dval上获得很好的性能。这意味着:MAML从k个样本中可以获得很好的泛化性能。使用φT代表被更新的参数,则MAML的目标如下:
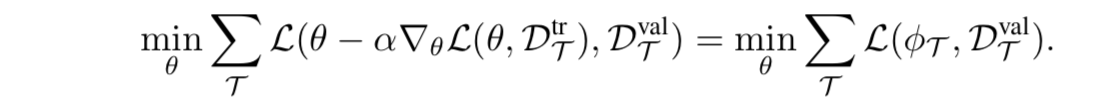
- 其中a是学习率。接下来,我们将把内部损失函数称为adaptation objective(适应性目标),将外部损失函数称为元目标(meta-objective)。然后,在测试阶段,从一个新的任务Ttest中采样K个样本。从参数θ开始,在K个样本上进行梯度下降,从而推断出适合新任务Ttest的参数:
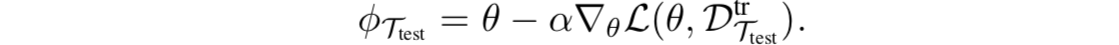
- 接下来,我们的工作是把one-shot imitation learning应用于纯视频输入。
-
4. Learning from humans
- 接下来展示如何从人类进行one-shot imitation learning。我们方法的关键是a learned temporal adaptation objective。
-
A. Problem Overview
- 从human video进行学习可以看做是一个inference problem。学习的目标是:把prior knowledge结合少量的evidence(human demonstration),从而推断出策略参数φTi,成功的完成任务Ti。为了能从human video中进行有效的学习,我们需要充足的先验知识(包括:对真实世界在视觉上/物理上的理解/人类想要获得什么样的结果/机器人采取什么的动作才能取得这些结果)。手工对先验知识进行编码很花时间,并且因具体任务而异。本文中,我们研究使用机器人和人类的demonstration数据,从先验知识中自动进行学习。
- 我们定义从人类获得的demonstration为observation图像序列 dh:o1 , ..., oT。从机器人获得的demonstration为observation-state-action序列 dr :o1, s1, a1, ..., oT , sT , aT 。其中,机器人state包括机器人的身体参数,但不包括目标参数,因为目标参数必须从图像osbervation中进行推断。我们不对人类demonstration和机器人demonstration进行任何相似或者差异的假设。这包含了大量的domain shift问题,比如:手臂的出现,背景的杂乱,以及相机的角度的差异。
- 我们的方法有两个阶段组成:
- (1)在meta-training阶段:目标是使用人类和机器人的demonstration来获取一个先验。使用这个先验,基于人类demonstration,快速模仿新任务。假设任务分布是p(T),从任务分布中获取的任务集合是{Ti}。对于每个任务,获取两个数据集分别包含human demonstration和robot demonstrations,记为(Dh Ti,Dr Ti)。
- (2)从任务分布中p(T )采样一个新任务T,并该任务中采样一个human demonstration。把上一步学到的先验,结合这个demonstration,推断出策略参数φT,从而成功解决任务T。
-
B. Domain-Adaptive Meta-Learning
- 我们提出domain-adaptive meta-learning方法,解决了从人类demonstration video中进行学习的问题。我们学习一组初始化参数,接下来只需要在 human demonstration上进行一或几个梯度步骤,模型就可以在新任务中获得较好的性能。Dtr T包含一个任务T的human demonstration,Dval T包含一个或多个任务T的robot demonstration。
- 我们无法直接获取人类demonstration中的action,所以在训练过程中我们无法把standard imitation learning loss直接应用于inner adaptation objective,即无法使用“机器人动作和human demnstration中的动作的差分”来进行反向传播。即使我们知道了人类的动作,但是我们无法获得人类动作和机器人动作的映射关系。因此,我们提出了用meta-learning的方法学习一个adaptation objective:这个方法不依赖policy输出的action进行BP,只需要在policy的activations上进行操作。这种“通过meta-learning的方法学习一个loss-function”,背后的灵感是:既然我们无法获取action来进行loss function的设计,那我们就基于“目前已有的输入”来获得一个损失函数,用activations产生梯度并对参数进行更新,在参数更新后就可以产生有效的action。尽管这看起来像是不可能的任务,但别忘了在meta-training阶段,我们依赖robot demonstration中的robot action进行了监督学习。我们这样解释这种“adaptation loss”:这种loss引导网络的参数更新,从而能够发现场景中正确的视觉线索,最终使得经过meta-training训练的“action-output”能够输出正确的动作。这种loss function叫做 L ψ 。
- 在meta-training阶段,我们学习了adaptation objective Lψ 的 初始化θ 和 参数ψ。θ和ψ在被不断的优化,从而输出“在 DvalT中 和 robot demonstration相符合的action”。
- meta-training阶段结束后,θ和ψ被保留,之前的数据被丢弃。一个新任务T的human demonstration dh被提供。为了推断出适合新任务的策略参数,我们把之前的参数θ作为初始状态,使用已经学习到的loss function Lψ ,和human demonstration dh,来进行梯度下降:
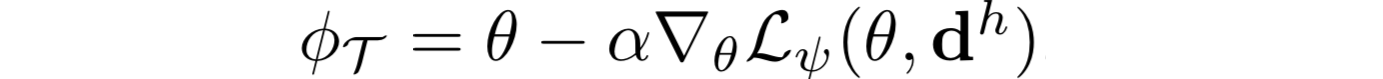
- 我们使用behavioral cloning objective来在meta-training阶段,优化任务的表现,从而最大化“Dval中的专家动作”出现的概率。实际上,参数为φ的策略输出动作的分布πφ (·|o, s)。具体的,the behavioral cloning objective如下:
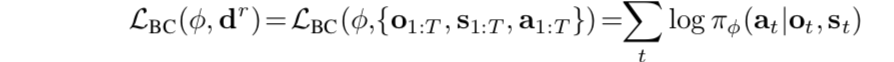
- 把上式和inner gradient descent adaptation结合在一起,得到meta-training objective:
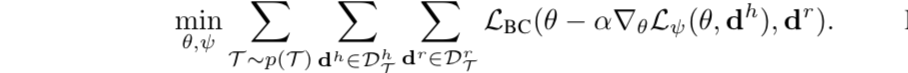
- 优化meta-objective的算法在Algorithm 1中。在meta-test阶段,从human demonstration进行学习的算法如Algorithm 2所示 。


-
C. Learned Temporal Adaptation Objectives
- 为了从 human video中学习,我们需要adaptation objective来捕捉相关信息。尽管每个时间步都使用了标准的behavior cloning loss,学习到的adaptation objective必须解决更困难的任务,因为adaptation objective必须在接触不到真实action的情况下给policy提供合适的梯度。这不是不可能,就像之前说的,policy在meta-training阶段被训练到可以输出足够好的action。梯度不断地更新参数,使得policy的感官组件不断更新,能够成功注意到环境中正确的目标,从而输出正确的目标。然而,明确“哪一个行为正在被demonstrated 以及 哪一个目标是相关的”,经常需要在同一时刻检查多个frames,从而决定human的motion。为了组合这些暂时的信息,学习到的adaptation objective连接多个时间步,具体实施方法是:“来自多个时间步的policy activations”。
- 因为时间卷积(temporal convolutions)在处理时间序列问题上被证明很有效,我们基于时间卷积来设计adaptation objective Lψ ,使用了多个1D卷积。我们在循环神经网络的基础上使用时间卷积,图2是结构图的可视化。
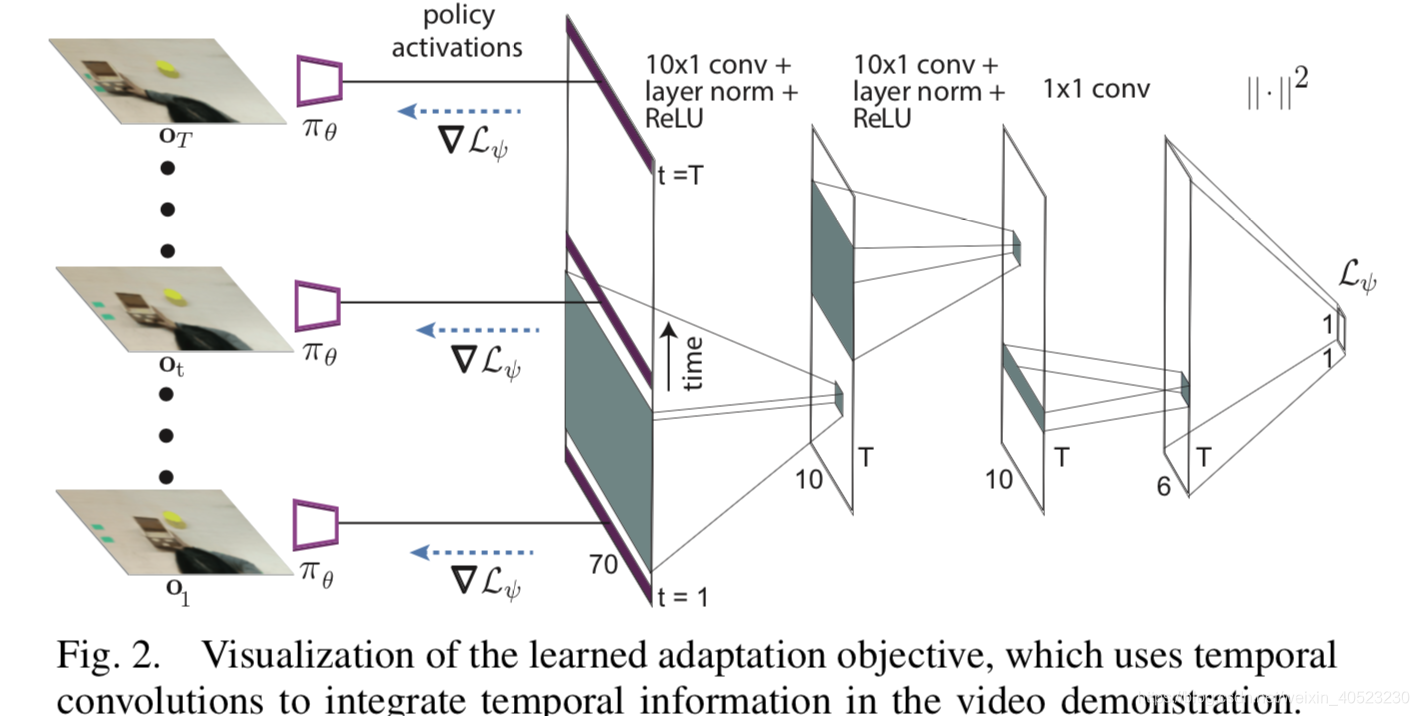
- 前人的工作介绍了一种two-head architecture for one-shot imitation,一个head用来pre-update demonstration,另一个head用来post-update policy。这种two-head架构可以这么解释:一个“经过学习得到的线性损失函数”,在特定的时间步,作用于policy network的最后一层线性层。损失和梯度根据demonstration中所有的时间步进行平均来计算。就像我们之前说的,在video demonstration中一个单独的时间步里单独的observation,在没有提供action的情况下,不足以学习。因此,简单的“平均方案”在处理时间信息是没有效率的。在第6节,我们证明:学习到的temporal loss可以从demonstration中进行有效率的学习,并且不需要action。
-
D. Probabilistic Interpretation
- “具有学习到的adaptation objective的meta-learning”有这么一种解释:概率图形模型框架。我们可以在前人提出的推导的基础上完成这一工作。前人的工作是:MAML也就是,基于先验参数θ和evidence DtrT = dhT,推断出后验——策略参数φ。之前的工作说明了:从φ = θ开始,在log p(Dtr T|φ)上几个梯度步就可以得到一个近似最大化的后验(MAP) inference on log p(φ|Dtr T, θ),where θ induces a Gaussian prior on the weights with mean θ and a covariance that depends on the step size and number of gradient steps。
- 在我们的方法中:adaptation涉及到在学习到的损失函数Lψ(φ,Dtr T)上进行梯度下降,而不是log p(Dtr T|φ)。我们任然从θ开始,执行几个梯度下降步骤,之前的工作说明了我们约等于是imposing the Gaussian prior log p(φ|θ)。因此,我们按照以下分布做了一个近似的MAP 推断:
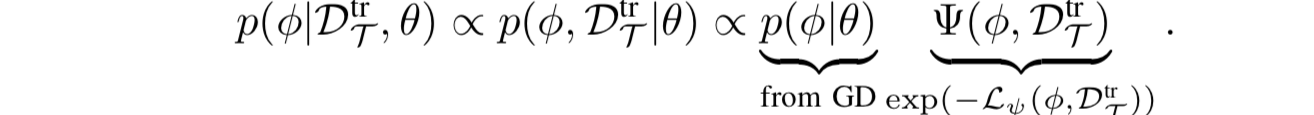
- 这是一个部分有向因子图,具有一个“基于φ和Dtr”学习到地权重Ψ,具有log-energy Lψ(φ,Dtr T)。贝叶斯inference需要集成φ,但是MAP inference提供了一种更容易处理的解决方案。通过最大化LBC(φT ,Dtr T )来进行训练,其中φT是φ的MAP inference。因为在高斯混合策略下,behavior cloning loss和action的对数似然相一致,所以我们直接训练先验θ和log-energy Lψ,这样MAP inference就可以最大化期望的动作输出的对数概率。注意,尽管我们在训练阶段使用MAP inference,模型没必要提供精确校准的概率。然而,概率解释仍然有助于阐明“学习到的adaptation objective Lψ”的作用:从“DT中的observation”和“策略参数φ”中一起归纳出一个联合因素。对应的图形化的解释说明如下所示:
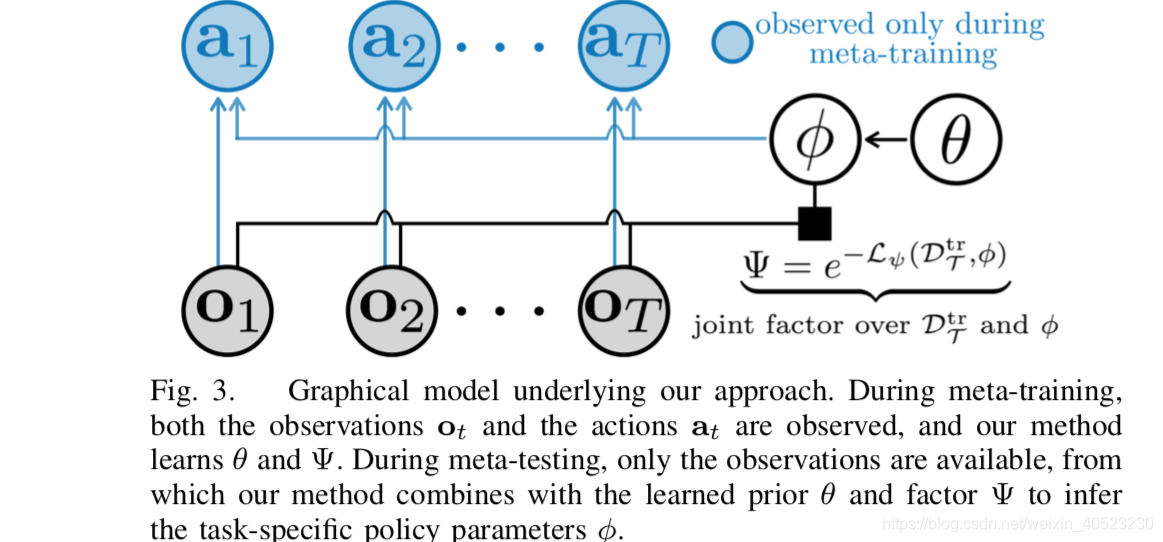
-
5. Network Architecture
-
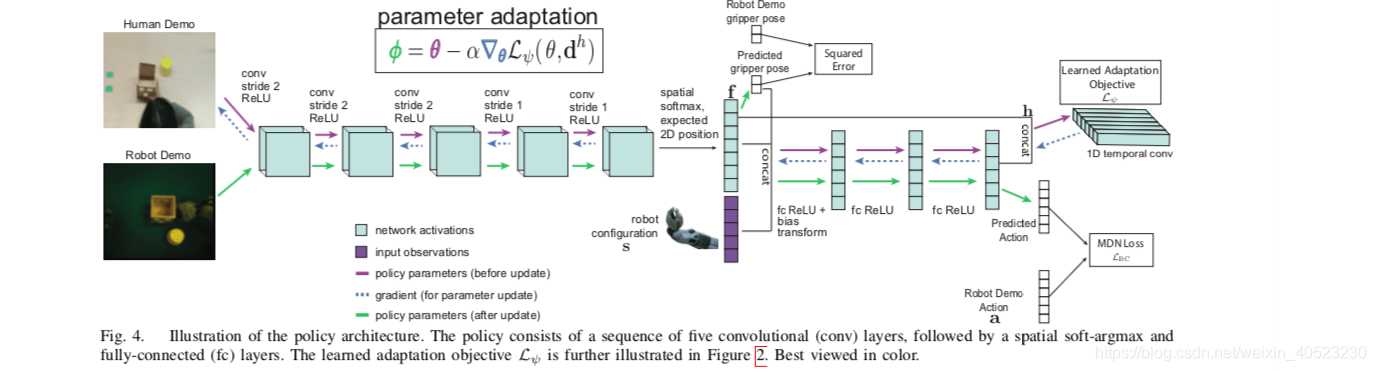
-
A. Policy Architecture
- policy network是一个卷积神经网络,把RGB images映射到动作分布。卷积神经网络从几个卷积层开始,输入channel- wise spatial soft-argmax(作用是:extracts 2D feature points f for each channel of the last convolution layer)。前人的工作已经说明了:spatial soft-argmax在机器人领域学习目标位置的表征是很有效的。追随前人的工作,我们把这些feature points和机器人的configuration串联起来(机器人configuration由末端执行器的位姿组成,具体来说是:夹具上3个非轴向点的三维位置)。然后把串联起来的“特征点和机器人位姿”输入多个全连接层。从最后一个隐藏层h中输出action的分布。我们用imagnet训练的网络初始化第一个卷积层。
- 在我们的实验中,我们在“机器人抓手的线速度和角速度”上使用一个连续的动作空间,在“抓手的开/闭动作”上使用一个离散的动作空间。与Gaussian distributions相比,Gaussian mixtures可以更好地模拟多模态动作分布。因此,对于连续动作,我们使用mixture density network来输出动作上的分布。对于打开或关闭夹持器的离散动作,我们输出时候使用的随机sigmod函数搭配cross-entropy loss。
- 追随之前的工作,我们额外预测“抓手接触到目标时候的位姿”。这是outer meta- objective的一部分,并且我们可以通过机器人demonstration提供监督学习。注意,当机器人从human video进行学习的时候,这个监督过程不需要meta-test。对于placing and pick-and-place任务,target container位于最终末端执行器的位置。因此,我们使用最后一个末端执行器姿势进行监督学习。对于pushing and pick-and-place任务,demonstration人工标记了抓手接触到目标的时间,并且使用了终端执行器在那一时刻的位姿。模型基于特征点f来预测intermediate gripper pose,同时预测的位姿传回policy。
-
B. Learned Adaptation Objective Architecture
- 因为我们需要更新策略的感知模块和控制模块,adaptation objective将会作用于predicted feature points, f(at the end of the perception layers)和the final hidden layer of the policy, h (at the end of the control layers)。这使得学习到的loss可以绕过控制层,直接调整卷积层的权重。使用temporal adaptation objective计算任务参数:
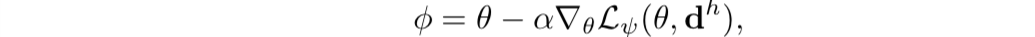
- 其中,我们把目标分解为两个部分:
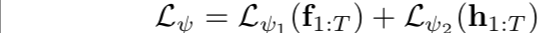
- 我们对Lψ1和Lψ2使用相同的架构,学习到的目标由三层temporal convolutions组成,前两个具有10 × 1 filters ,第三具有 1 × 1 filters。
-
【论文翻译】One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
最新推荐文章于 2022-04-20 09:26:35 发布

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









