



 一名程序员分享了从努力工作到自我提升的心路历程,包括使用DTO、树形结构处理、代码优化、前后端交互、数据库操作及项目管理等实战经验。
一名程序员分享了从努力工作到自我提升的心路历程,包括使用DTO、树形结构处理、代码优化、前后端交互、数据库操作及项目管理等实战经验。
努力工作,好好生活
三月
因为开发时,项目经理提到使用DTO建立与前台交互用实体,我着手了解一下,然后现学现用。
至于DTO是什么我这里就不多做赘述,因为我自己理解都不是很清楚,生怕误人子弟。
下面记录一下,我使用DTO都做了些什么。
我理解的DTO 和 VO 其实没多大区别,所以我直接使用VO给我的类做后缀名。
然后这些类里面就放一些前端需要的字段,像什么delFlag、createUser、createTime、updateUser 这些我就没有放。
然后因为做了树形结构,所以写了一个树形的DTO,话说到这里我才想起来,给子节点排序的功能我还没实现,等下得赶快去完成。
树形结构嘛,就那么几个字段
@Data
public class TreeVo {
private String id;
private String pId;
private String name;
}
因为使用了lombok插件,所以@Data注解代替了get/set方法。插件大法好啊。
因为需要一次性的获取所有的树和节点,所以写了些影响性能的方法,没办法技术太差,就这几棵树就让我难受了很久,之后项目经理看了我的代码之后还是批评了我,如果类型是确定的要用DTO,平时少用什么Object做返回参数,只有在不确定类型的时候才用,我当时就没听太明白,现在写这个博客的时候就更不明白了,还是要多学习,以后经理说了什么不懂得一定要问到懂为止,那句话怎么说的来着:求知若渴,虚心若愚。不懂还不问,我是真的愚啊。
@Override
public List<Object> menuList(List<TreeVo> menu){
List<Object> list = new ArrayList<>();
this.menuCommon = menu;
for (TreeVo treeVo : menu) {
Map<String,Object> mapArr = new LinkedHashMap<String, Object>();
if(treeVo.getPId().equals("0")){
mapArr.put("id", treeVo.getId());
mapArr.put("name", treeVo.getName());
mapArr.put("pid", treeVo.getPId());
mapArr.put("dataList",judge(treeVo.getId()));
mapArr.put("childList", menuChild(treeVo.getId()));
list.add(mapArr);
}
}
return list;
}
public List<Object> menuChild(String id){
List<Object> lists = new ArrayList<Object>();
for(TreeVo a : menuCommon){
Map<String,Object> childArray = new LinkedHashMap<String, Object>();
if(a.getPId().equals(id)){
childArray.put("id", a.getId());
childArray.put("name", a.getName());
childArray.put("pid", a.getPId());
childArray.put("dataList",judge(a.getId()));
childArray.put("childList", menuChild(a.getId()));
lists.add(childArray);
}
}
return lists;
}
查询文件内容的代码就不贴了。
之后呢,又做了一个根据id 和类型查找改文件的全部内容的接口,有点好玩的是我不知道mybatis Plus 的lambdaQuery怎么不跟据条件查询全部表信息,我就写出了这样的代码,希望以后找到更好的方法来重构它。
catalog.ne(ServiceCatalogRecord::getId,"八百标兵奔北坡,炮兵并排北边跑。")
.orderByAsc(ServiceCatalogRecord::getCatalogcode).orderByAsc(ServiceCatalogRecord::getSortindex);
id肯定不会等于 “八百标兵奔北坡”吧…
再然后就是DTO 和PO 之间的转换了,因为感觉一直get/set,写的我头都大了,就上网找一些方法类,找来找去找到了一个BenasUtils,先将就着用吧,感觉还挺好用,但是在找到这个方法的时候看了一眼说是还有一个BeanCopier,还看到说是基于cglib,这几天刚好在看深入java虚拟机,在这本书里也看到了cglib,感觉是很底层的东西,运行速度应该要比反射来的快,因为反射的时候好像还要去虚拟机进行类加载之类的,所以搜了一下两个类的区别:
/**
* BeanUtils.copyProperties(record,districtsCountiesVo);
* beanUtils 是利用反射 进行的copy 耗时12000ms,(调用100万次)
* 而BeanCopier 则是基于 cglib,修改字节码 耗时20ms
* @return
*/
@Override
public List<DistrictsCountiesVo> allDistrictsCounties() {
LambdaQueryWrapper<DistrictsCountiesRecord> districtsCounties = new LambdaQueryWrapper<>();
districtsCounties.ne(DistrictsCountiesRecord::getId,"炮兵怕把标兵碰,标兵怕碰炮兵炮"); //肯定不会等于 所以就是查找全部
List<DistrictsCountiesRecord> recordList = districtsCountiesMapper.selectList(districtsCounties);
List<DistrictsCountiesVo> districtsCountiesVoList = new ArrayList<>();
for (DistrictsCountiesRecord record: recordList) {
DistrictsCountiesVo districtsCountiesVo = new DistrictsCountiesVo();
BeanCopierUtil.copy(record,districtsCountiesVo);//将po 的数据 copy 到 vo(dto)// 中 此处的vo == dto
districtsCountiesVoList.add(districtsCountiesVo);
}
return districtsCountiesVoList;
}
这里又是一段绕口令…
这几天还在看新版的重构,在看书的同时我一边在想自己的代码,感觉我的代码不需要重构,需要重写,我写的这都是什么臭狗屎!
虽然说是臭狗屎,还是贴一下BeanCopierUtil类的代码以便日后有需要的时候CV:
package org.jeecg.modules.catalogManagement.util;
import org.springframework.cglib.beans.BeanCopier;
import java.util.concurrent.ConcurrentHashMap;
/**
* BeanCopier工具类
* @author suns
*/
public class BeanCopierUtil {
/**
* BeanCopier的缓存
*/
static final ConcurrentHashMap<String, BeanCopier> BEAN_COPIER_CACHE = new ConcurrentHashMap<>();
/**
* BeanCopier的copy
* @param source 源文件的
* @param target 目标文件
*/
public static void copy(Object source, Object target) {
String key = genKey(source.getClass(), target.getClass());
BeanCopier beanCopier;
if (BEAN_COPIER_CACHE.containsKey(key)) {
beanCopier = BEAN_COPIER_CACHE.get(key);
} else {
beanCopier = BeanCopier.create(source.getClass(), target.getClass(), false);
BEAN_COPIER_CACHE.put(key, beanCopier);
}
beanCopier.copy(source, target, null);
}
/**
* 生成key
* @param srcClazz 源文件的class
* @param tgtClazz 目标文件的class
* @return string
*/
private static String genKey(Class<?> srcClazz, Class<?> tgtClazz) {
return srcClazz.getName() + tgtClazz.getName();
}
}
还有一个标签功能:
大致就是从数据中读取标签信息,去重之后返给前台,写到这里我想起了一个问题,前台输入的时候我好像没有判断数据库中有没有这个标签,如果有就不能重复添加,等会儿又多了一个活…
这里用到了Java8的新特性:stream
但是我对这个新特性的了解仅仅来自于 Java菜鸟教程
下面又是一段拙略的代码:
@Override
public List<String> allTag() {
LambdaQueryWrapper<SpaceServiceRecord> spaceService = new LambdaQueryWrapper<>();
spaceService.select(SpaceServiceRecord::getTag);//查找所有的tag
List<Map<String, Object>> selectMaps = spaceServiceMapper.selectMaps(spaceService);
List<String> tags = new ArrayList<>();
for(int i = 0; i < selectMaps.size(); i++){
if(selectMaps.get(i) != null){
String str = selectMaps.get(i).values().toString().replaceAll( "[\\[\\]]" , "");
//在这里对字符串做对比 然后去重
String[] strings = str.split(",");
for(int a = 0; a < strings.length; a++ ){
if(strings.length == 1){//如果只有一个 直接加进去 下一个for会去重
tags.add(strings[a]);
}
for(int b = strings.length - 1; b > a; b--){
if(!strings[a].equals(strings[b])){
tags.add(strings[a]);
tags.add(strings[b]);
}
}
}
}
}//把所有标签都取到 ,并且去除[], 存进list
String string = tags.stream().distinct().collect(Collectors.joining(","));
List<String> strings = new ArrayList<>();
strings.add(string);
List<String> list = strings.stream().distinct().collect(Collectors.toList());
return list;
}
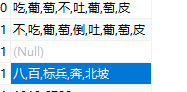
"result": [
"吃,皮,萄,葡,吐,不,倒,八,北坡,奔,标兵,百"
]
交代一下上面这段代码的作用吧,虽然说是已经取出来tag字段了,但是是存在Map里的,还是Object ,只好转成String,转成String 还没完,因为标签是用逗号分隔的,转成String就成了类似这样的“吃,葡,萄,不,吐,葡,萄,皮”,我得挨个把它们取出来,然后去重,然后我又在数据库的字段写了一个“不,吃,葡,萄,倒,吐,葡,萄,皮”所以我又转成了String[],再对数组进行去重。
说实话写这个方法,我还挺难受的,for循环这方面我一直都很弱,这么简单的逻辑,写的我都是生无可恋,真不知道从小数学没及格过的我为什么想学这个,现在却又不得不去恶补一些知识,但是没想到的是学习的时候,我是快乐的。虽然感觉我的话很矛盾,您就理解成痛并快乐着吧。
这周的总结,大概就是这些了,知识点不多,但总比没有好。也算是懂了一万小时定律为什么这么香。
如果您看过这条博客,发现了以上有任何不足之处,欢迎指出,对我有益我必虚心接受,也很乐意和您交朋友,学习之路任重而道远,愿您不吝赐教,先行谢过。
加油狗剩儿。
四月
2020.4.5日开发记录以及上个礼拜的代码修改
4.5这个礼拜,是比较难受的一个礼拜,因为需求理解错了,导致我前面几天写的代码都成了鸡肋,周五的时候再次被项目经理批评了,但是我肯定也要自我安慰自己一下,没有需求文档就给我个原型图,我理解能力有差,出错正常(我这可怜的阿Q精神)。
但是这确实是我的锅,虽然我觉得委屈,但是我自己在不明确需求(以为自己明确了)的情况下就开始写代码,肯定是不行,就此问题我在接受批评之后跟项目经理提成,以后谈完需求我自己再跟他复述一遍,已确保我理解的就是他想表达的,因为他周五的语气确实吓到我了,感觉他随时可能发飙,我只能一怂再怂,毕竟非常时期,工作没那么好找。
更新代码:
上礼拜的那种树虽然说是只操作了一次数据查询,但是我没做到给子节点排序的功能,然后就用了这种:
@Data
public class ServiceCatalogTreeVo {
private String id;
private String pid;
private String name;
private String type;
private Integer sortindex;
private String catalogcode;
@TableField(exist = false)
private List<ServiceCatalogTreeVo> childList;
@TableField(exist = false)
List<SpaceServiceVoForTree> dataList;
}
@Override
public List<ServiceCatalogTreeVo> tree() {
LambdaQueryWrapper<ServiceCatalogTreeVo> serviceCatalog = new LambdaQueryWrapper<>();
serviceCatalog.ne(ServiceCatalogTreeVo::getPid,"0").orderByAsc(ServiceCatalogTreeVo::getSortindex);
List<ServiceCatalogTreeVo> childList = serviceCatalogTreeVoMapper.selectList(serviceCatalog);//子集
LambdaQueryWrapper<ServiceCatalogTreeVo> catalog = new LambdaQueryWrapper<>();
catalog.eq(ServiceCatalogTreeVo::getPid,"0").orderByAsc(ServiceCatalogTreeVo::getCatalogcode);
List<ServiceCatalogTreeVo> topList = serviceCatalogTreeVoMapper.selectList(catalog);//顶集
if(topList.size() > 0){
Set<String> set = Sets.newHashSetWithExpectedSize(childList.size());//过滤条件set,指定set预期大小为非顶级类目集合的size
topList.forEach(c -> {
getChild(c,childList,set);//获取子集
c.setDataList(getService(c.getId()));//获取服务 并添加到serviceList
});//foreach 遍历查询的整个树结构
return topList;//返回整个树
}
return null;
}
/**
* 递归获得子目录
* @param serviceCatalogTreeVo 顶集
* @param childList 子集
* @param set 已循环过的id集合
*/
private void getChild(ServiceCatalogTreeVo serviceCatalogTreeVo,List<ServiceCatalogTreeVo> childList,Set<String> set){
List<ServiceCatalogTreeVo> list = Lists.newArrayList();
if(childList.size() > 0){
childList.stream()
.filter(c -> !set.contains(c.getId()))//判断是否已经循环过当前对象
.filter(c -> c.getPid().equals(serviceCatalogTreeVo.getId()))//判断是否父子关系
.forEach(c ->{
set.add(c.getId());//放入set,递归循环时跳过这个子集,提高循环效率
getChild(c,childList,set);//获取当前父级的子集
c.setDataList(getService(c.getId()));//遍历子节点中的数据并加入到子节点下面
list.add(c);//加入子集的集合
});
}
serviceCatalogTreeVo.setChildList(list);
}
public List<SpaceServiceVoForTree> getService(Serializable id){
LambdaQueryWrapper<SpaceServiceRecord> serviceTree = new LambdaQueryWrapper<>();
serviceTree.eq(SpaceServiceRecord::getPid, id).orderByAsc(SpaceServiceRecord::getSortindex);//根据上级id判断同级是否存在服务,并排序输出
List<SpaceServiceRecord> serviceList = spaceServiceMapper.selectList(serviceTree);
List<SpaceServiceVoForTree> list = new ArrayList<>();
if(serviceList.size() < 1){ return null; }
for(SpaceServiceRecord c :serviceList){
SpaceServiceVoForTree spaceServiceVoForTree = new SpaceServiceVoForTree();
BeanCopierUtil.copy(c,spaceServiceVoForTree);//数据装换
list.add(spaceServiceVoForTree);
}
return list;
}
春风吹来了四月的尾声,吹来了夏天的味道。也吹来了五一小长假,虽然2020的假期已经够多的了,但是我还是盼望着假期的到来。
这个礼拜,都是些简简单单的crud,值得一提的就是今天遇到的一个问题了。
以下是报错信息,我只贴了caused by:
2020-04-26 19:38:38.580 [http-nio-8086-exec-1] ERROR org.jeecg.modules.controller.TbSpeciesController:79 - nested exception is org.apache.ibatis.builder.BuilderException: Error evaluating expression 'ew.sqlSegment != null and ew.sqlSegment != '' and ew.nonEmptyOfWhere'. Cause: org.apache.ibatis.ognl.OgnlException: sqlSegment [com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: your property named speciesId cannot find the corresponding database column name!]
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.builder.BuilderException: Error evaluating expression 'ew.sqlSegment != null and ew.sqlSegment != '' and ew.nonEmptyOfWhere'. Cause: org.apache.ibatis.ognl.OgnlException: sqlSegment [com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: your property named speciesId cannot find the corresponding database column name!]
Caused by: org.apache.ibatis.builder.BuilderException: Error evaluating expression 'ew.sqlSegment != null and ew.sqlSegment != '' and ew.nonEmptyOfWhere'. Cause: org.apache.ibatis.ognl.OgnlException: sqlSegment [com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: your property named speciesId cannot find the corresponding database column name!]
Caused by: org.apache.ibatis.ognl.OgnlException: sqlSegment
Caused by: com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: your property named speciesId cannot find the corresponding database column name!
就是这么一段让人挠头的提示信息,我面向百度编程了半小时,这类错误少之又少,仅有的几个高赞博客都让我替换一下mybatis-plus的版本,我替换了,无果。只好去stack Overflow 和SegmentFault 搜索一下,没想到去这些我认为的高端博客问答网站,也一无所获。
我只好根据报错信息一一比对我的代码:
LambdaQueryWrapper<Tbxxxx> tbSeas = new LambdaQueryWrapper<>();
tbSeas.eq(Tbxxxx::getSpeciesId,tb.getId());
List<Tbxxxx> area = TbxxxxMapper.selectList(tbSeas);
看过来看过去,这段代码没问题。
又仔细看我的报错信息:
Caused by: com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: your property named speciesId cannot find the corresponding database column name!
说找不到我这个speciesId ,那么我去看看我的实体类:
@ApiModelProperty (value = "物种标识")
private String SpeciesId;
我的字段名,第一个单词写成了大写!
制造问题,发现问题,解决问题,制造问题,发现问题,解决问题,制造问题,发现问题,解决问题,制造问题,发现问题,解决问题,制造问题,发现问题,解决问题,制造问题,发现问题,解决问题…
这个问题可不是一般的低级,希望以后我不会再出现这种错误。
五月
不知不觉,五月底了,这个月忙的浑天暗地,每天加班到十点。
虽然看起来也不是很晚,但是我家离公司的路程一个半小时,到家就十二点了。
这个项目快要完结了,我也要被释放了,做外包的第一年,第一次解放。
今天知道这个消息的时候,还有一点儿不知所措。
不过也好,有几天休息时间,我也累了。
这个月都没啥时间记录我遇到的问题,只记得遇到了一个比较棘手的问题,我总结成了文档等着闲下来的时候上传一下
就在刚刚我打开公司电脑遇到一个这样的问题
cheaking file system on c: the type of the file system id NTFS
xxxxxxxxxxx.......
检查系统文件,百度了一下说是上一次没有正常关机所以导致的,对自己的电脑好点儿。
结果我就没管它,让它自己检查完,然后正常重启了。
遇到事情不要慌,即使赶时间也别表现得慌张,成年男人别像个小孩似的。
五月的收获总结为一段冗长的sql:
<select id="speciesPageBySearch" resultType="org.jeecg.modules.entityVo.SpeciesSearchVo">
SELECT
SPS.ID as id,SPS.CHN_NAME as chnName,
(SELECT NAME FROM tc_type WHERE ID = sps.reliability) AS RELIABILITY,
(SELECT NAME FROM tc_type WHERE ID = sps.PROTECTION_LEVEL) AS PROTECTION_LEVEL,
(SELECT name_path FROM tb_species_type WHERE ID = sps.species_type_id) AS typeName
FROM
TB_SPECIES SPS
<if test="dto.speciesTypeId != null">
,( SELECT SPT.ID FROM TB_SPECIES_TYPE SPT CONNECT BY SPT.PARENT_ID = PRIOR SPT.ID START WITH SPT.ID = '1' ) PT
</if>
<if test="dto.xzqId != null">
,TB_SPECIES_XZQ SX
,TB_XZQ XZQ
</if>
<if test="dto.areaId != null">
,TB_SPECIES_ECOLOGICAL_AREA SEA
,TB_ECOLOGICAL_AREA EA
</if>
WHERE 1=1
<if test="dto.speciesTypeId != null">
AND SPS.SPECIES_TYPE_ID = PT.ID
</if>
<if test="dto.xzqId != null">
AND SX.SPECIES_ID = SPS.ID
AND SX.XZQ_ID = XZQ.ID
AND XZQ.id = #{dto.xzqId}
</if>
<if test="dto.areaId != null">
AND SEA.SPECIES_ID = SPS.ID
AND SEA.AREA_ID = EA.ID
AND EA.id = #{dto.areaId}
</if>
<if test="dto.name != null">
<bind name="name" value="'%'+dto.name+'%'"/>
AND SPS.CHN_NAME LIKE #{name}
</if>
<if test="dto.speciesTypeId != null">
AND SPS.SPECIES_TYPE_ID = #{dto.speciesTypeId}
</if>
<if test="protection != null">
and
<foreach collection="protection" item="protection" index="index"
open="(" separator=" or " close=")" >
SPS.PROTECTION_LEVEL = #{protection}
</foreach>
</if>
<if test="reliability != null">
and
<foreach collection="reliability" item="reliability" index="index1"
open="(" separator=" or " close=")" >
SPS.reliability = #{reliability}
</foreach>
</if>
</select>
六月
这个月同上个月比较轻松的多得多,从外派公司回来之后我单独带了一个项目,还给了两个小朋友打下手,但是他们并没有减轻我的工作量,道理都会懂得。
前些日子项目组的前端小朋友离职了,我又写起了前端,不知道啥时候会再给我一个前端,全栈党政就更累的,这个月贴一些前端代码,刚刚接触vue,用了一下之后发现确实很好用,但是我肯定属于那种入门级的。
下面是一个下拉列表的二级联查:
<div >
出警人员:
<el-select v-model="departs" @change="selectConfig" placeholder="请选择部门:">
<el-option v-for="item in depList "
:key="item.id"
:label="item.departName"
:value="item.departName">
</el-option>
</el-select>
<el-select v-model="add_data.ids" filterable remote multiple
placeholder="请选择警员:" @change="selectLocalSelectConfig(copList.id)">
<el-option v-for="cop in copList"
:key="cop.id"
:label="cop.name"
:value="cop.name">
</el-option>
</el-select>
</div>
data() {
return {
departs:'',
depList:[],
departName:"",
cops:'',
copList:[],
}
},
mounted(){
this.getDeparts();
},
methods: {
selectConfig(departName){
this.getCops(departName);
},
getDeparts(){
this.$http.get('/sys/sysDepart/queryList')
.then(res =>{
let data=res.result
for (let v of data){
v.key=v.id
this.depList.push(
v
)
}
}).catch(err=>{
console.log(err);
})
},
getCops(departName){
getAction("/sys/cops/queryCopList",{departName:departName}).then(
(res)=>{
let data=res.result
if(data == undefined || data.length <= 0){
this.copList =[];
}else{
for (let v of data){
v.key=v.id
this.copList.push(
v
)
}
}
}
)
}
}
七月(实际上更新已经是2021年1月28号了。。。)
剩下这几个月,从外包团队回公司带项目了没什么时间更博客,现在没那么忙了,要重新开启一章新的博客,更一下2021,希望2021我能更上一层楼。

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









