




 本文深入探讨了进程和线程的概念,阐述了它们之间的区别,包括资源管理、通信方式、调度机制等方面。同时,介绍了线程的数据共享和数据安全问题,以及如何通过锁机制解决这些问题。此外,还讲解了线程的开启方式、守护线程的概念和线程池的使用。
本文深入探讨了进程和线程的概念,阐述了它们之间的区别,包括资源管理、通信方式、调度机制等方面。同时,介绍了线程的数据共享和数据安全问题,以及如何通过锁机制解决这些问题。此外,还讲解了线程的开启方式、守护线程的概念和线程池的使用。
进程的引入
操作系统中,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。
程序和进程的区别就在于:
程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。就是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
进程存在的不足:
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
60年代,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端,一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。
因此在80年代,出现了能独立运行的基本单位——线程(Threads)。
注意:进程是资源分配的最小单位,线程是CPU调度的最小单位.
每一个进程中至少有一个线程。
线程与进程的区别可以归纳为以下4点:
1)地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
2)通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
3)调度和切换:线程上下文切换比进程上下文切换要快得多。
4)在多线程操作系统中,进程不是一个可执行的实体。
线程的特点
在多线程的操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。
1)轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。
2)独立调度和分派的基本单位。
在多线程OS中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
3)共享进程资源。
线程在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的进程id,这意味着,线程可以访问该进程的每一个内存资源;此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
4)可并发执行。
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
线程的数据共享
from threading import Thread
n = 100
def func():
global n
n -= 1
t_l = []
for i in range(100):
t = Thread(target=func,)
t.start()
t_l.append(t)
for t in t_l:
t.join()
print(n)1、线程的数据是共享的
2、线程之间也是存在数据安全的问题,只是当前测试的数据量较小,而线程的执行效率 较高,导致出现的概率很小
线程的数据安全
线程是否存在数据安全问题
数据共享
GIL锁 :能够保证在同一时刻 不可能有两个线程 同时执行 CPU指令
为什么有了GIL还需要手动加锁
为什么append这样的方法和+=这样的方法在数据安全性问题上是不一样
由于append是一个完整的指令过程,执行了就相当于添加,不执行就还没添加
+= 先执行+法,再对结果进行赋值
from threading import Lock
import dis
# append方法
l = []
def func():
l.append(1)
# +=方法
a = 0
def func2():
global a
with lock:
a += 1
lock = Lock()
dis.dis(func2)append方法
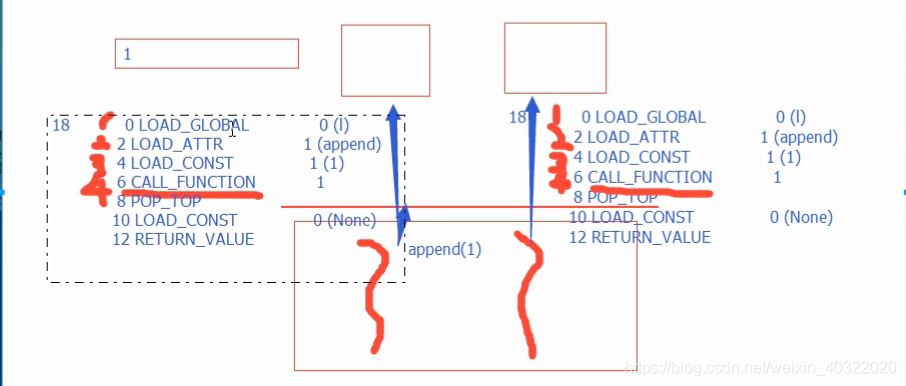
+=方法
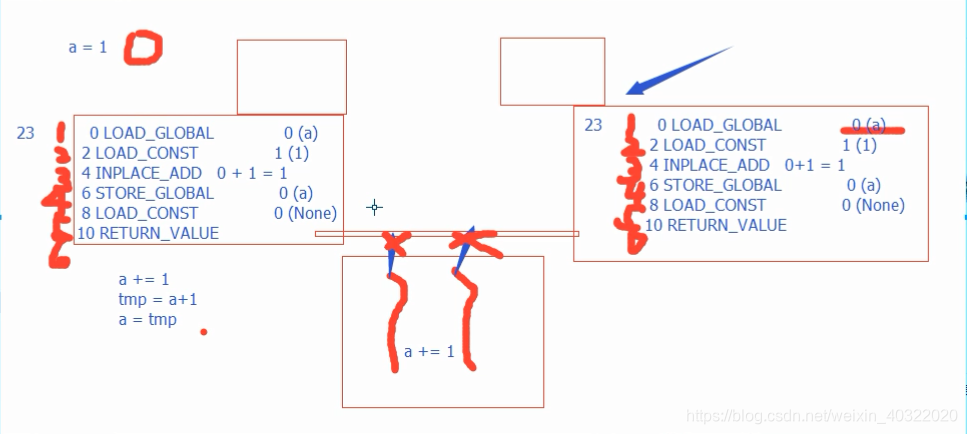
1、死锁现象
由于多个锁对多个变量管理不当 产生的一种现象
连续acquire两次也会出现死锁现象
2、Lock 互斥锁
在一个线程内只能被acquire一次
互斥锁的效率较高
3、RLock 递归锁
在一个线程内可以被acquire多次,必须acquire多少次,release多少次
线程的开启方式
# 使用函数的方式启动线程 在函数内获取当前线程的id
import time
from threading import currentThread
def func():
time.sleep(1)
print('in func',currentThread().name,currentThread().ident)
t = Thread(target=func)
t.start()
print(t.ident) # 线程id
print(t.name) # 线程名
currentThread().name # 在函数内获取当前线程的名字
currentThread().ident # 在函数内获取当前线程的id# 使用面向对象的方式开启线程
import time
class MyThread(Thread):
def __init__(self,i): # 传参
self.i = i
super().__init__()
def run(self):
time.sleep(1)
print('in mythread',self.i)
for i in range(10):
t = MyThread(i)
t.start()
self.name 线程名
self.ident 线程ID
守护线程
# 守护线程
import time
from threading import Thread
def func():
while True:
time.sleep(1)
print('in func')
def son():
print('son start')
time.sleep(8)
print('son end')
t = Thread(target=func)
t.setDaemon(True)
t.start()
Thread(target=son).start()
time.sleep(5)守护进程 会等待主进程的代码结束而结束
守护线程 会等待主线程的结束而结束
如果主线程还开启了其他子线程,那么守护线程会守护到最后
主进程必须后结束,回收子进程的资源
线程是属于进程的,主线程如果结束了,那么整个进程就结束了
过程
主线程结束依赖两个事儿 (自己的代码执行完毕,非守护的子线程执行完毕)
-->主线程结束,进程也结束了
-->这个进程中的所有线程都结束了
线程队列
队列是一种非常重要的数据结构
1、保证队列中数据的安全
2、严密的维护了一个稳定的顺序
# fifo 先进先出
q = queue.Queue()
q.get()
q.get_nowait() # 不会阻塞,直接报错,提示queue empty
q.put()
q.put_nowait() # 不会阻塞,直接丢弃数据,提示queue full# lifoqueue 后进先出的队列 = 栈 --> 算法 栈比递归效率要高
lifoq = queue.LifoQueue()
lifoq.put(1)
lifoq.put(3)
lifoq.put(2)
lifoq.put(0)
print(lifoq.get())
print(lifoq.get())# 优先级队列
pq = queue.PriorityQueue()
pq.put((2,'wusir'))
pq.put((1,'yuan'))
pq.put((1,'alex'))
pq.put((3,'太亮'))
print(pq.get())
print(pq.get())
print(pq.get())线程池
# 最简单的模型
import time
from concurrent.futures import ThreadPoolExecutor
def func(i):
time.sleep(1)
print('in son thread',i)
tp = ThreadPoolExecutor(4)
for i in range(20)
tp.submit(func,i)
tp.shutdown()
print('所有的任务都执行完了')# 1 介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface,
which is defined by the abstract Executor class.
# 2 基本方法
# submit(fn, *args, **kwargs) 异步提交任务
# map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作
# shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕,但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
# result(timeout=None) 取得结果
# add_done_callback(fn) 回调函数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









