




 本文深入探讨了标准模板库(STL)中的多种容器类型及其应用特性,特别是哈希表的内部机制与应用场景。从空间适配器如stack、queue到关联容器如unordered_map的介绍,详细解析了红黑树与哈希表这两种数据结构的特点及它们如何提升数据操作效率。
本文深入探讨了标准模板库(STL)中的多种容器类型及其应用特性,特别是哈希表的内部机制与应用场景。从空间适配器如stack、queue到关联容器如unordered_map的介绍,详细解析了红黑树与哈希表这两种数据结构的特点及它们如何提升数据操作效率。
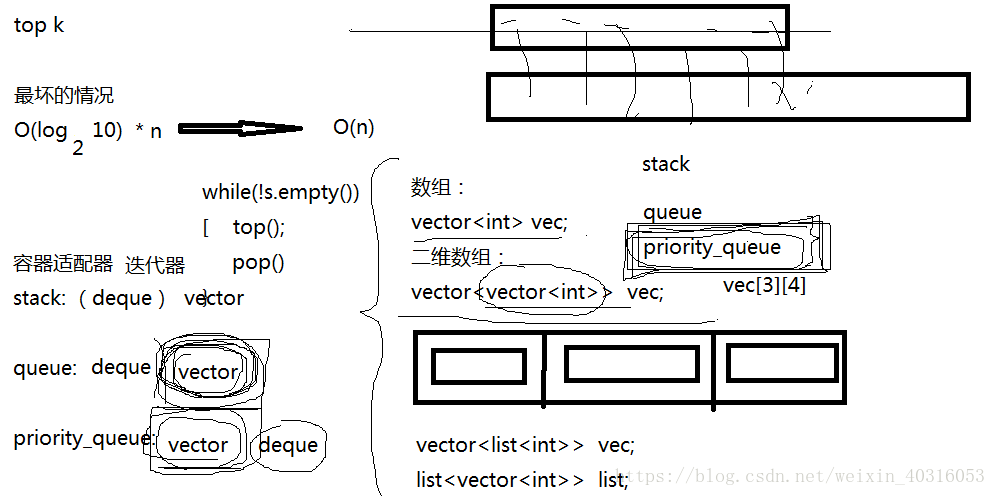
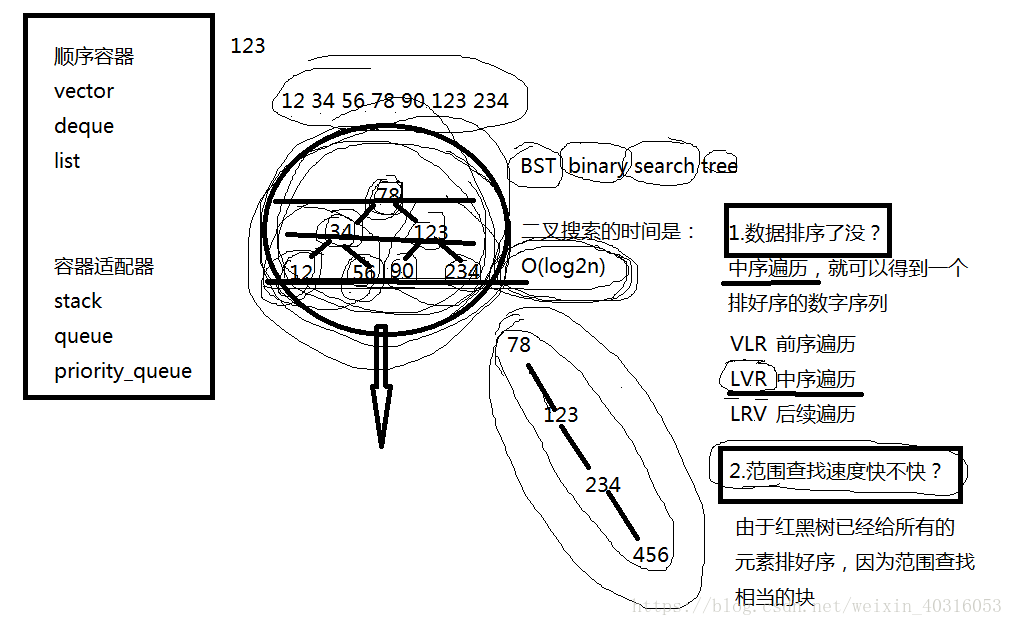
空间适配器:stack、queue(底层是二维数组)、priority_queue(在容器上建立了一个堆结构)在数组上建堆。
多维数组本身也是一维的。vector<vector<int>>
list<vector<int>>list
容器适配器没有提供迭代器。因为它底层就没有提供数据结构。
关联容器:#include <unorderered_set>
#include <unordered_map>
有序关联容器:底层用红黑树实现。
无序的关联容器:
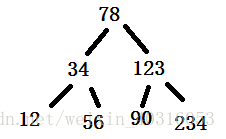
BST树(红黑树)
二分查找就是红黑树的查找。
O(log2n)
红黑树的数据是经过排序的。
L永远在R前面
VLR前序遍历
LVR中序遍历
LRV后序遍历
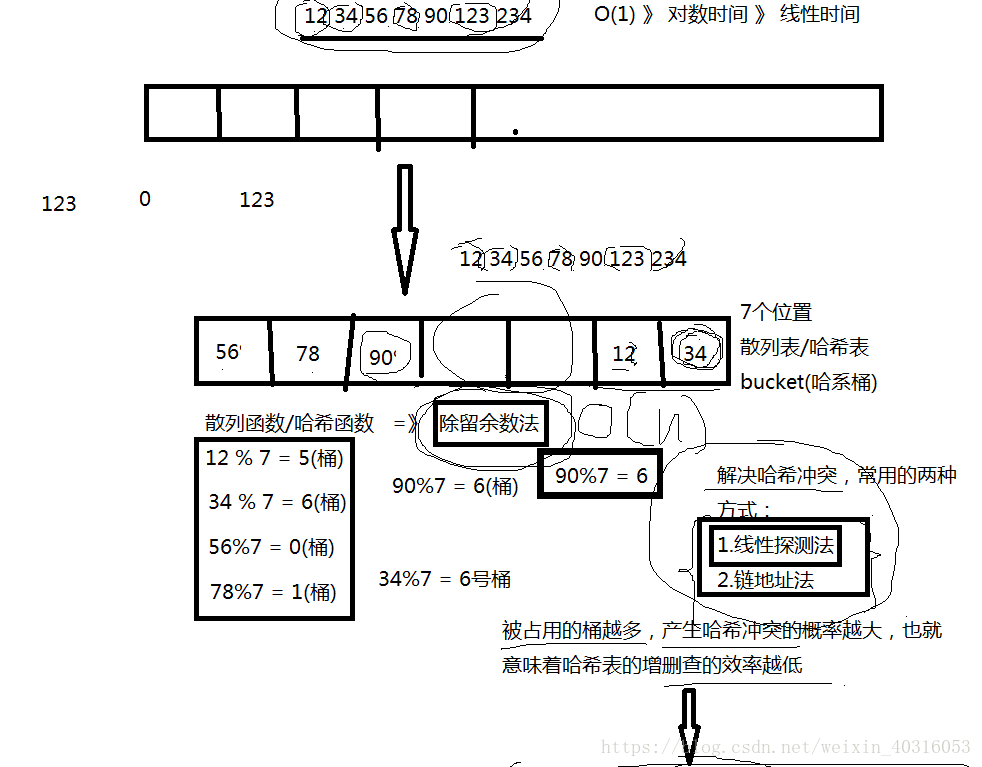
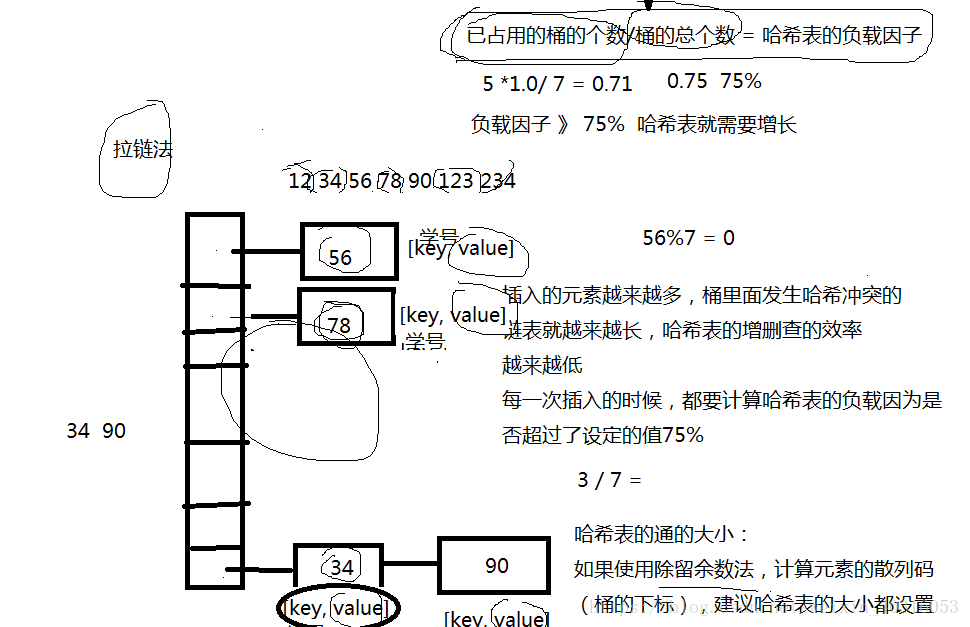
无序的关联容器,底层是哈希表(链地址法、拉链法)增删查的时间复杂度:接近O(1)。一下子就能找到他。
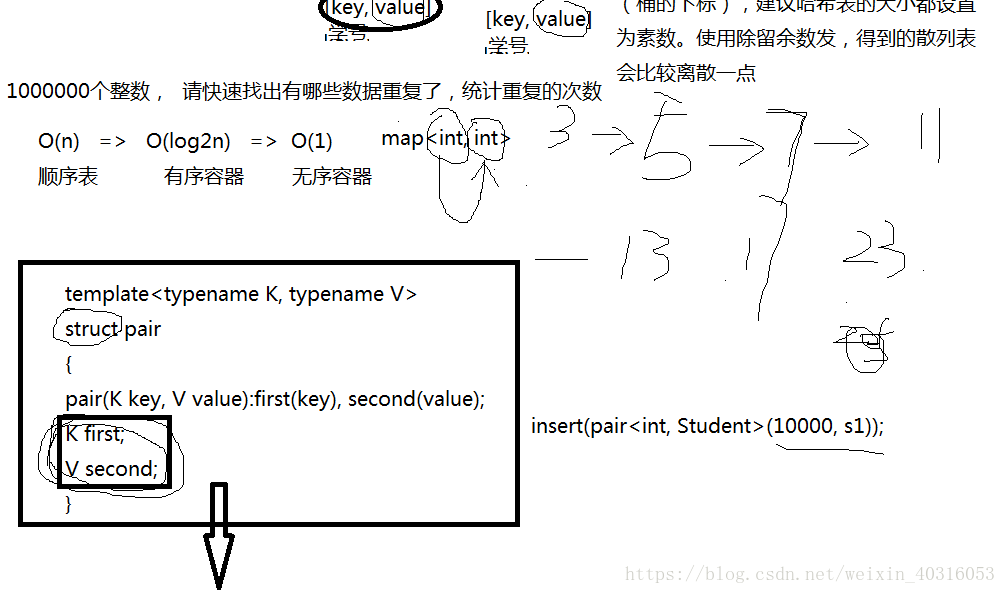
素数:只有1和本身能整除。不能被其他数这整除。
哈希表的数据结构。(快速的增删查),但数据无序,非常不适合范围查找。
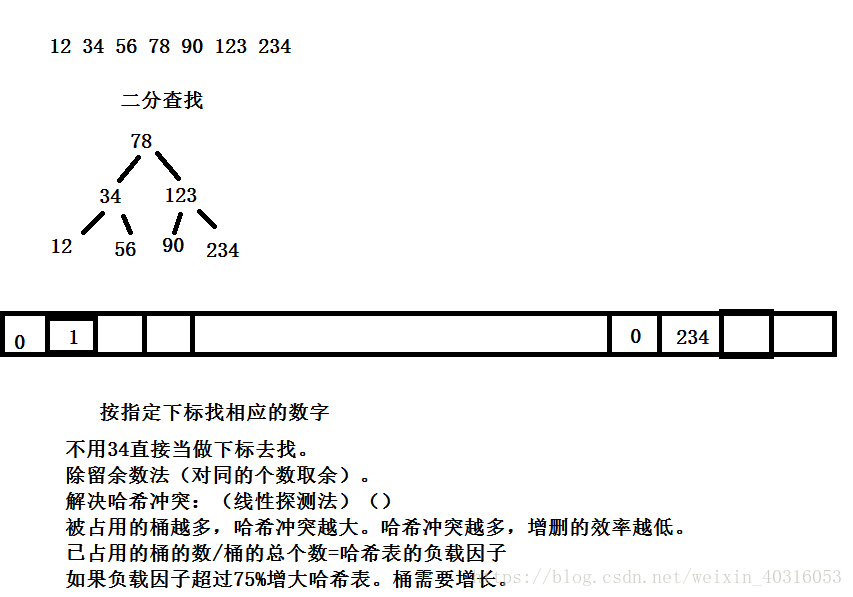
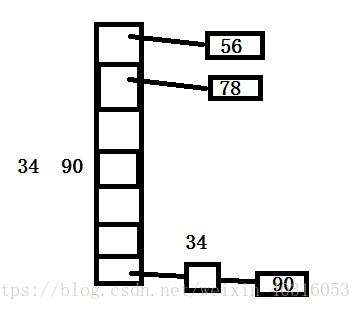
哈希表无序容器。
数据离散一点。解决哈希冲突。
unordered_map:映射表
求散列,
map<int(数),int(重复次数)>:键值
只读没有写操作。定义成常方法。
键值对,用pair打包到一起了。pair对象。需要用户事先将键值对打包好。

类模板会提供函数模板,自动推演这些类型。
函数模板自动推演,自动实例化类对象,返回回来。
定义迭代器:
遍历的顺序和插入的顺序无关,因为哈希表本来就是无序的。
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
class Student
{
public:
Student() {}
Student(int id, string name, int age, string sex)
:mId(id), mName(name), mAge(age), mSex(sex) {}
int getId()const { return mId; }
private:
int mId;
string mName;
int mAge;
string mSex;
friend ostream& operator<<(ostream &out, const Student &stu);
};
ostream& operator<<(ostream &out, const Student &stu)
{
out << "id:" << stu.mId << endl;
out << "name:" << stu.mName << endl;
out << "age:" << stu.mAge << endl;
out << "sex:" << stu.mSex << endl;
return out;
}
int main()
{
/*
unordered_map : 映射表
Person
vector<Person> vec; O(n)
unordered_map<int, Person> 哈希表 int(学号)O(1)
*/
//1.创建一组学生对象
Student s1(10000, "刘洋洋", 20, "男");
Student s2(10010, "李鑫", 21, "女");
Student s3(10030, "宁天浩", 19, "男");
unordered_map<int, Student> stuMap;
//2.映射表的插入
stuMap.insert(make_pair(10010, s2));
stuMap.insert(make_pair(10000, s1));
stuMap.insert(make_pair(10030, s3));
//3.遍历映射表
unordered_map<int, Student>::iterator it = stuMap.begin();
for (; it != stuMap.end(); ++it)
{
cout << "key:" << (*it).first << " value:" << it->second << endl;
}
cout << stuMap[10010] << endl;
return 0;
}

在map表中it永远迭代的是pair对象。
关联容器都是通过键值来进行增删改查,把键值组织在红黑树或哈希表中,提高增删改查的效率。
大数据的查重,都离不开哈希表。
写代码一定不能边想边写。(效率太低)一定要先把思路想清楚了再写。
思路还是不清楚啊。
每次写代码前,先将思路在注释里面吧思路写写,不要一上来就写代码,效率太低了。
map表,
写点伪代码。
pair两个变量,一个键值,一个成员值。
打印哈希表肯定是无序的。哈希表本身就是无序的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









