




 这篇博客介绍了如何使用正则表达式去除字符串中的空白字符,以及判断字符串中是否含有中文字符。示例代码包括使用replace和replaceAll方法,以及正则表达式的修饰符和元字符的解释,如全局匹配(g)和大小写不敏感(i)等。同时,文章详细列举了正则表达式的量词和方括号用法,帮助读者更好地理解和应用正则表达式。
这篇博客介绍了如何使用正则表达式去除字符串中的空白字符,以及判断字符串中是否含有中文字符。示例代码包括使用replace和replaceAll方法,以及正则表达式的修饰符和元字符的解释,如全局匹配(g)和大小写不敏感(i)等。同时,文章详细列举了正则表达式的量词和方括号用法,帮助读者更好地理解和应用正则表达式。
正则表达,经常记不住,写下记录!
字符串中含有{{}}内容填充实现
将字符串“你好,我的名字{{name}},年龄{{}}岁”,依据let obj = {name:'jane, age:18},返回“你好,我的名字jane,年龄18岁”。
function replacePlaceholders(str, obj) {
// 正则表达式:/\{\{([^}]+)\}\}/g 用于匹配所有被 {{}} 包裹的占位符。([^}]+) 是一个捕获组,用于捕获 {{}} 内的内容。
// /([^}]+)/ 这个正则表达式可以匹配一个或多个非右花括号的字符,并将匹配到的内容作为一个捕获组。
return str.replace(/\{\{([^}]+)\}\}/g, (match, key) => {
// 在替换函数中,match 是整个匹配到的字符串(如 {{name}}),key 是捕获组中的内容(如 name)。如果 obj 中存在该键,则返回对应的值;否则返回空字符串。
return obj[key]!== undefined? obj[key] : '';
});
}
let str = "你好,我的名字{{name}},年龄{{age}}岁";
let obj = { name: 'jane', age: 18 };
let result = replacePlaceholders(str, obj);
console.log(result);
const regex = /\{\{([^}]+)\}\}/g;
const str1 = "{{hello}},世界!{{good}}棒";
while ((match = regex.exec(str1)) !== null) {
console.log(match);
console.log("完整匹配:", match[0]);
console.log("捕获组内容:", match[1]);
}
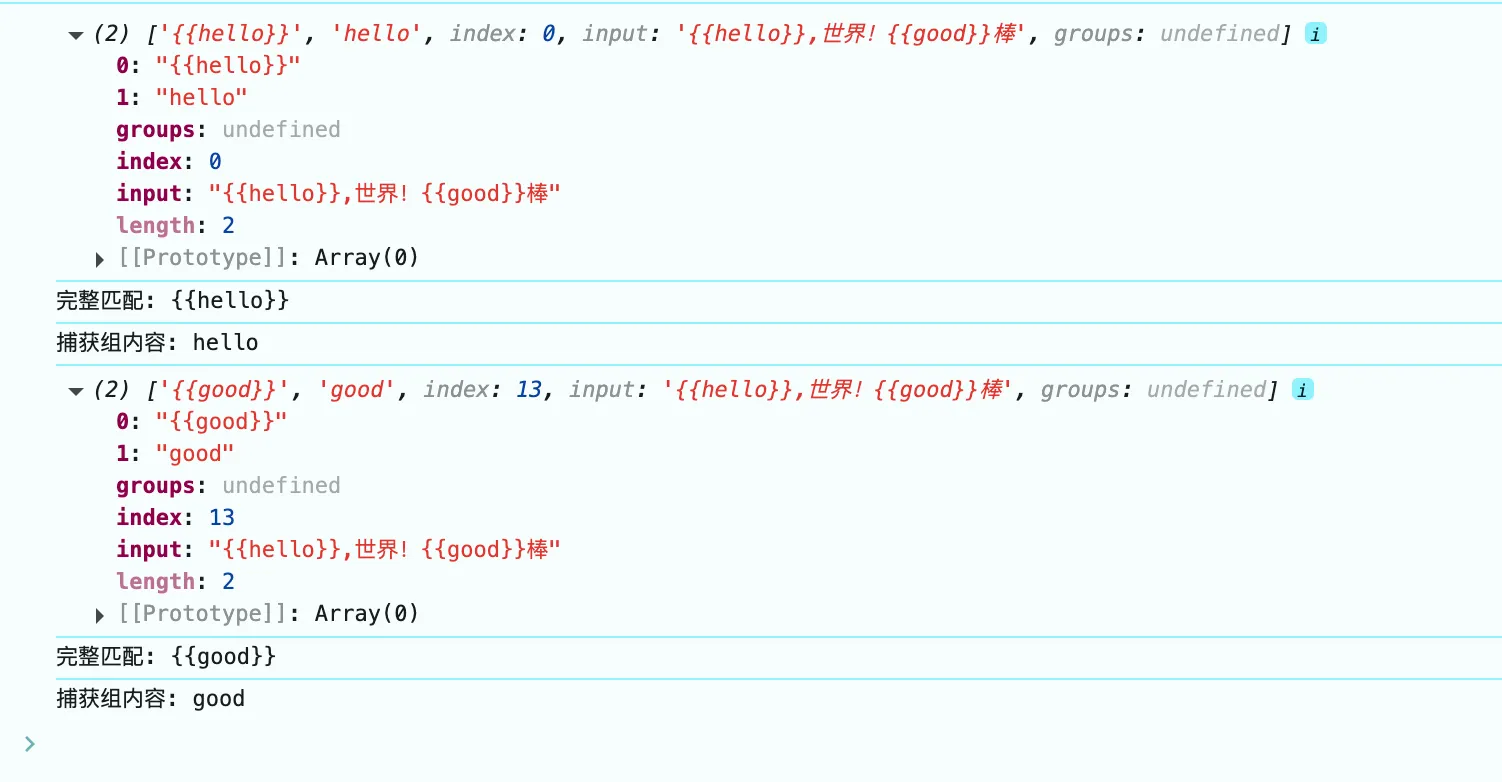
捕获组是什么?
捕获组是通过在正则表达式里使用括号 () 来定义的。每一对括号会创建一个捕获组,正则表达式引擎会在匹配字符串时记录每个捕获组匹配的内容。
捕获组编号:捕获组是按照左括号出现的顺序从 1 开始编号的。编号 0 代表的是整个正则表达式匹配的内容。
什么是命名捕获组?
从 ES2018 开始,JavaScript 支持命名捕获组,它允许为捕获组指定一个名称,这样在引用捕获组时会更加直观。
命名捕获组使用 (?<name>pattern) 的语法来定义,其中 name 是你为捕获组指定的名称,pattern 是要匹配的正则表达式模式。
const regex = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const str = '2024-10-01';
const result = regex.exec(str);
console.log('result', result);
if (result) {
console.log('完整匹配:', result[0]);
console.log('年:', result.groups.year);
console.log('月:', result.groups.month);
console.log('日:', result.groups.day);
}

正则表达式如何支持传入变量
正则表达式有两种
- 字面量表达式:这种方法无法传递变量
- 构造函数式表达式:可以使用变量
// 限制为3个数值
export const regNum = /^\d{3}$/;
//正则表达式中加入变量
const validKeyFun = (projectId) => {
const re = new RegExp(`^${projectId}\\d{2}$`);
return re;
};
console.log('flag', validKeyFun('3444').test('344412'));//true
实现去掉字符串中所有的空白字符
let testString = ' kpo op d 0 ';
console.log(testString)
let needString = testString.replace(/\s+/g, '')
console.log(needString);
let testString = ' kpo op d 0 ';
console.log(testString)
let needString = testString.replaceAll(' ', '')
console.log(needString);
判断字符串中是否含有中文
const hasChineseStr = (s: string) => {
const reg = /[\u4E00-\u9FFF]+/g;
if (reg.test(s)) {
return true;
}
return false;
};
正则字符含义符号
修饰符
| 修饰符 | 描述 |
|---|---|
| i | 执行对大小写不敏感的匹配。 |
| g | 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 |
| i | 执行对大小写不敏感的匹配。 |
| m | 执行多行匹配。 |
方括号用于查找某个范围内的字符
| 表达式 | 描述 |
|---|---|
| [abc] | 查找方括号之间的任何字符。 |
| [^abc] | 查找任何不在方括号之间的字符。 |
| [0-9] | 查找任何从 0 至 9 的数字。 |
| [a-z] | 查找任何从小写 a 到小写 z 的字符。 |
| [A-Z] | 查找任何从大写 A 到大写 Z 的字符。 |
| [A-z] | 查找任何从大写 A 到小写 z 的字符。 |
| [adgk] | 查找给定集合内的任何字符。 |
| [^adgk] | 查找给定集合外的任何字符。 |
| ` (red | blue |
元字符(Metacharacter)是拥有特殊含义的字符
| 元字符 | 描述 |
|---|---|
| . | 查找单个字符,除了换行和行结束符。 |
| \w | 查找数字、字母及下划线。 |
| \W | 查找非单词字符。 |
| \d | 查找数字。 |
| \D | 查找非数字字符。 |
| \s | 查找空白字符。 |
| \S | 查找非空白字符。 |
| \b | 匹配单词边界。 |
| \B | 匹配非单词边界。 |
| \0 | 查找 NULL 字符。 |
| \n | 查找换行符。 |
| \f | 查找换页符。 |
| \r | 查找回车符。 |
| \t | 查找制表符。 |
| \v | 查找垂直制表符。 |
| \xxx | 查找以八进制数 xxx 规定的字符。 |
| \xdd | 查找以十六进制数 dd 规定的字符。 |
| \uxxxx | 查找以十六进制数 xxxx 规定的 Unicode 字符。 |
| 量词 | 描述 |
|---|---|
| n+ | 匹配任何包含至少一个 n 的字符串。例如,/a+/ 匹配 “candy” 中的 “a”,“caaaaaaandy” 中所有的 “a”。 |
| n* | 匹配任何包含零个或多个 n 的字符串。例如,/bo*/ 匹配 “A ghost booooed” 中的 “boooo”,“A bird warbled” 中的 “b”,但是不匹配 “A goat grunted”。 |
| n? | 匹配任何包含零个或一个 n 的字符串。例如,/e?le?/ 匹配 “angel” 中的 “el”,“angle” 中的 “le”。 |
| n{X} | 匹配包含 X 个 n 的序列的字符串。例如,/a{2}/ 不匹配 “candy,” 中的 “a”,但是匹配 “caandy,” 中的两个 “a”,且匹配 “caaandy.” 中的前两个 “a”。 |
| n{X,} | X 是一个正整数。前面的模式 n 连续出现至少 X 次时匹配。例如,/a{2,}/ 不匹配 “candy” 中的 “a”,但是匹配 “caandy” 和 “caaaaaaandy.” 中所有的 “a”。 |
| n{X,Y} | X 和 Y 为正整数。前面的模式 n 连续出现至少 X 次,至多 Y 次时匹配。例如,/a{1,3}/ 不匹配 “cndy”,匹配 “candy,” 中的 “a”,“caandy,” 中的两个 “a”,匹配 “caaaaaaandy” 中的前面三个 “a”。注意,当匹配 “caaaaaaandy” 时,即使原始字符串拥有更多的 “a”,匹配项也是 “aaa”。 |
| n$ | 匹配任何结尾为 n 的字符串。 |
| ^n | 匹配任何开头为 n 的字符串。 |
| ?=n | 匹配任何其后紧接指定字符串 n 的字符串。 |
| ?!n | 匹配任何其后没有紧接指定字符串 n 的字符串。 |


















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









