



BIT数独个人项目
1.作业说明
github地址如下:***https://github.com/shanliangc/mysudoko
开发环境为:MAC OS python3.6(可能因为python版本不兼容的问题,自带的库报错,请在评价作业时使用python3.6的环境,谢谢!)
本题目要求个人在win10环境下设计出一个可以自动生成数独、解决数独,且带有UI界面的数独的软件。我实现的部分有:自动生成数独、解决数独和附加题和带有UI的解数独模型。
但由于我在MAC下无法调试能在win下运行的exe文件,且现在时间紧迫需要准备剩余8科的考试,故只提供可在命令行下运行的py文件。
分别为:
1.UI.py:使用方式为重新定位目录为当前.py文件所在的文件夹,在命令行里执行即可,其使用的未填满的数独终局文件位于BIN/sudokopuzzle1.txt,可进行修改。
2.sudoko.py :使用方式为重新定位目录为当前.py文件所在的文件夹,按照个人项目说明书上更改即可:如python sudoko.py -c 100(生成100个数独文件)和python sudoko.py -s BIN/sudokopuzzle.txt(可在终端输出所有的数独终局)
2.时间使用情况
| PSP2.1 | personal software process stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 3000 | 1500 |
| Estimate | 估计耗时 | 3000 | 1500 |
| Development | 开发 | 1220 | 1240 |
| Analysis | 需求分析 | 60 | 90 |
| Design Spec | 文档设计 | 120 | 120 |
| Design Review | 设计审查 | 300 | 100 |
| Coding Standard | 代码规范 | 20 | 60 |
| Design | 设计 | 120 | 90 |
| Code Review | 代码复审 | 240 | 60 |
| Test | 测试 | 60 | 120 |
| Report | 报告 | 420 | 180 |
| Test Report | 测试报告 | 240 | 60 |
| Size Measurement | 计算工作量 | 60 | 60 |
| Postmoterm & process improvement plan | 事后总结并提出改进计划 | 120 | 60 |
| 合计 | 合计 | 4640 | 2920 |
3.题目分析
题目要求完成3个需求:1.生成数独终局
题目至少要生成100,0000个数独终局的解。
依照要求,我的想法是先随机生成三串1~9的随机数字,分别填入1、5、9号九宫格中,因为1、5、9号9宫格中两两9宫格中的数字不会相互影响,所以可以随便填写,只要满足数独规则即可。再按照顺序依次填写3、2、6、4、8、7号9宫格中的数字即可,用深度优先搜索的方法解决问题。
但是在后来的实际操作中发现,这种填写方式非常耗费时间,生成1000个数独终局大概需要50s的时间,且有重复生成数独终局的可能性,虽然可能性极低。因为这种填写方式生成数独终局的数量至少有高达8!*9!*9!的结果。
后来在百度上查找资料,**发现可以借用数独的数学性质进行填写,先填写第一行的数字,全排列以后有8!的结果,再通过一定的规律将第一行的结果填满整个数独,并且每一次的结果可以再通过交换生成更多的数独。由此生成的终局,4、5、6行两两之间彼此交换,7、8、9行两两之间彼此交换,2、3行彼此交换依然能满足数独终局的性质,所以至少能生成2 * 3!3!8! >> 100,0000个要求的数独终解。且经过测试,在python环境下只需18s就能生成并将结果写入文件中。
2.解决数独
解决数独的问题比起生成数独的问题来得容易很多,我的想法是记录每个元素填写的次数,先从填写最多的元素开始填起,耗费的时间会相对少一些,因为填写元素的个数越多说明这个元素有可能出现的格子就越少,先从该元素开始填写能减少时间。
3.制作UI界面
本次任务使用了python自带的tkinter来解决UI问题。考虑到如果使用其他python库可能会出现本地缺失的现象。所以使用较为简单且易上手的tkinter。
在判断用户是否填对数独库的时候,只需判断是否满足数独的要求即可。数独的游戏规则有两个个:只能出现1~9的数字,每行每列即每个九宫格中必须出现1 ~ 9的所有数字,且每个数字有且只能出现一遍,判断的时候很方便。
根据用户填写的结果进行判断:当所有的方格全部被填写完成的时候,如果填写正确了,会提示完成,如果填写错误,则会提示未完成,如果填写的内容为空,或者出现非1~9的数字,会提示有且只能出现1 ~ 9 的数字。
4.
类一共有两个:
1.SudoTable.py
其中拥有的重要函数为:
1.solve_a_puzzle(table):传入并解决一个未完成的数独
2.search_a_puzzle(start):从当前路径向后深度优先搜索数独的一个解
拥有的重要数据为:
1.table:记录着终局的结果,数据结构为python中的list,存储着终局的字符串,只有确定完成终局的时候才会对table进行操作。
1.solve_a_puzzle
把一个待解决的数独库传入,其中未填写的地方标记为0,并且设计出填写数独的路径,在我的设计中,填写的路径是这样的,包含两个数据(第x个9宫格中缺少的数字e,九宫格号码x),将这个tuple放在我的路径列表中,按照既定的路径进行搜索(从0出发,到最后到达结点)
2.search_a_puzzle
传入参数当前的路径位置start,从当前路径向后搜索,如果x9宫格中可以填入数字e,则继续solve_a_puzzle(start+1),否则返回上一层,start-1。
2.Fastsudoko.py
其中拥有的重要函数为:
1.perm(begin):生成全排列除2以外的全排列数字
2.create_puzzle(random_ele_sequence):将全排列数字串按照数独规则填写并生成2!*3!*3!个不重复的终局。
其中拥有的重要数据是:
1.path:记录生成的路径
2.ele_sequence:一个开头为2,包含了1~9的所有数字的序列,用来填写数独终局的第一行
3.ans:用来存储所生成的数独库终局。
1.perm
把开始传入,生成全排列,具体原理很简单。
2.create_puzzle
把全排列数字传入,并且2~3行交换,4 ~6 行交换,7 ~9行交换,将这三种交换进行排列组合,生成数独的终局。
5.改进即性能分析
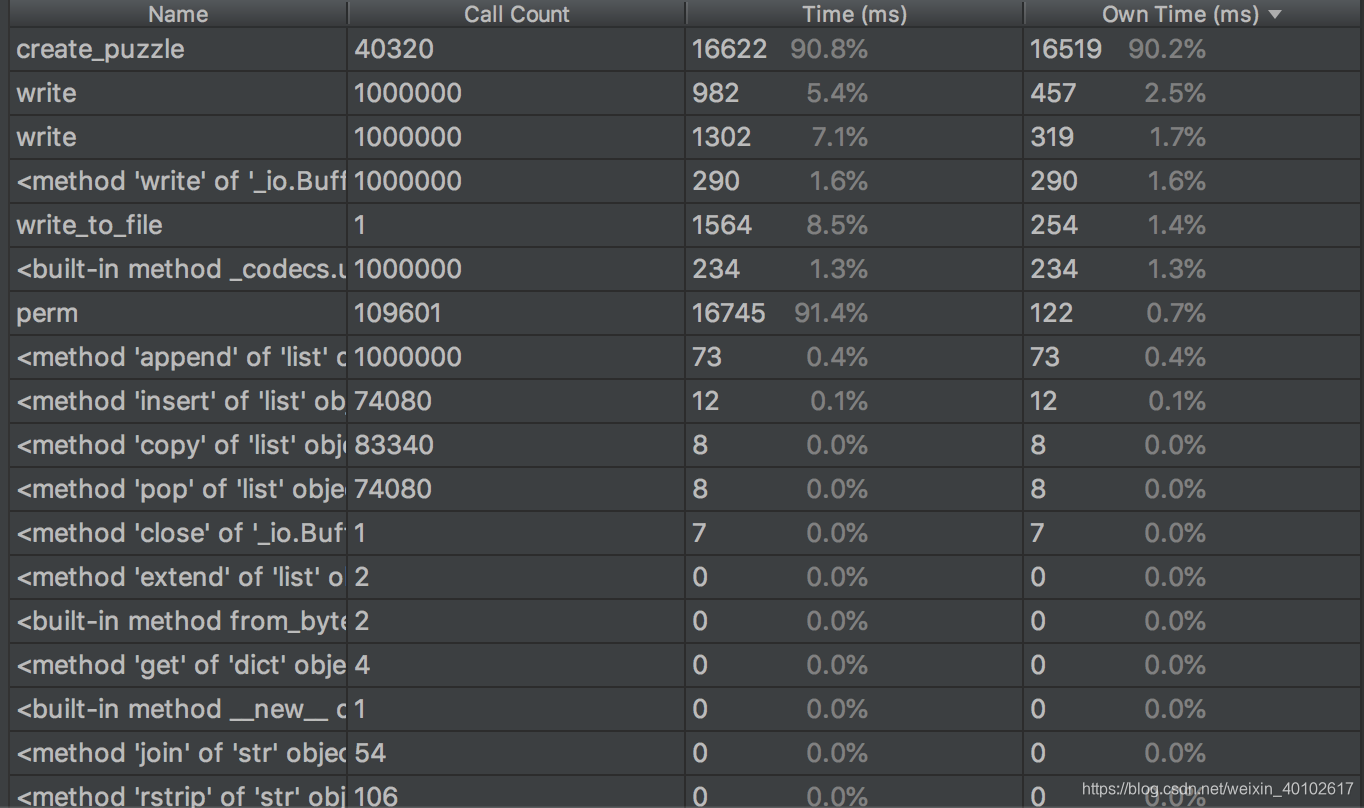
这是改进后的结果,可以看到耗时最多的函数是创造数独终局的函数create_puzzle。改进之前耗时最多的是写入文件操作,因为当时的做法是每生成一个终局则打开一次文件,写入文件中,后来的做法改成,将所有的结果保存在FastSudoko文件的ans中,直接将ans按行写入文件中即可。原来生成100,0000的时间在55s左右,后来使用将文件一次性写入的方式将时间降低到18s左右。
单元测试:
from BIN import FastSudoko
import time
start = time.time()
# 测试生成100,0000个数独生成的时间是多少,测试FastSudoko数独生成单元
sudoko_generator = FastSudoko.FastSudokoGenerator(1000000)
sudoko_generator.perm(1)
sudoko_generator.write_to_file("sudoko.txt")
end = time.time()
# 查看生成的速度
print("time consumed = ", end-start, "s"
如下为python中的单元测试使用方式

6.代码说明
FastSudoko.py中的代码
# 生成全排列,其中第一位为2
def perm(self, begin):
# 从1begin = 1 end = 9
if begin >= 9:
# print(ls)
if self.res >= 0:
self.create_puzzle(self.ele_sequence)
else:
return
else:
i = begin
for num in range(begin, 9):
self.ele_sequence[num], self.ele_sequence[i] = self.ele_sequence[i], self.ele_sequence[num]
if self.res >= 0:
self.perm(begin + 1)
else:
break
self.ele_sequence[num], self.ele_sequence[i] = self.ele_sequence[i], self.ele_sequence[num]
def create_puzzle(self, random_ele_sequence):
# 初始化
sequence = [3, 6, 1, 4, 7, 2, 5, 8]
# 为了避免重复生成数独终局,必须使用全排列的方式进行生成random_ele_sequence
while self.res > 0:
# random_ele_sequence = random.sample(range(1, 10), 9)
# # 调整成2在左上角
# random_ele_sequence.remove(2)
# random_ele_sequence.insert(0, 2)
# ls = []
# for ele in random_ele_sequence:
# ls.append(str(ele))
# random_ele_sequence = ls.copy()
table = [0, 0, 0, 0, 0, 0, 0, 0, 0]
# print(random_ele_sequence)
table[0] = random_ele_sequence.copy()
for i in sequence:
tmp = random_ele_sequence[-1]
random_ele_sequence.pop()
random_ele_sequence.insert(0, tmp)
table[i] = random_ele_sequence.copy()
# 通过交换的方式生成新的矩阵
for i in range(1, 3):
for tmp_i in range(1, 3):
if tmp_i == i:
continue
if self.res == 0:
break
table[i], table[tmp_i] = table[tmp_i], table[i]
for j in range(3, 6):
for tmp_j in range(3, 6):
if tmp_j == j:
continue
if self.res == 0:
break
table[j], table[tmp_j] = table[tmp_j], table[j]
for k in range(6, 9):
for tmp_k in range(6, 9):
if tmp_k == k:
continue
if self.res == 0:
break
table[k], table[tmp_k] = table[tmp_k], table[k]
self.res -= 1
s = ''
for row in table:
for i in range(0,8):
s += row[i]
s += ' '
s += row[8]
s += '\n'
# 按照要求一下应该省略,但是为了让调试的时候看的更清楚一些
# 可以使用这样的格式
# s += '\n'
self.ans.append(s)
table[k], table[tmp_k] = table[tmp_k], table[k]
#调整回原来状态
table[j], table[tmp_j] = table[tmp_j], table[j]
# 调整回原来状态
table[i], table[tmp_i] = table[tmp_i], table[i]
# 将结果写入文件中,这里的写入是可覆盖型写入
SudoTable.py中的代码
def search_a_puzzle(self, start):
if start >= len(self.path):
# print("end")
# print("end")
for row in self.table:
s = ''
for i in range(0,8):
s += str(row[i])
s += ' '
s += str(row[8])
s += '\n'
self.ans.append(s)
self.ans.append('\n')
print("answer of this sudokopuzzle is :")
print("----------------------------------------------")
for row in self.ans:
print(row, end = '')
print("----------------------------------------------")
print("")
# 加上这一条
self.ans = []
# for row in self.table:
# print(row)
# print()
# print("end2222")
return True
# 当前要填的是哪一个元素,哪一个格子
(ele, block_num) = self.path[start]
# print("start = ", start, " ", (ele, block_num))
# 寻找当前block,可以填上ele的坐标有哪些
possible_coordinate = self.search_possible_coordinate_for_ele(ele, block_num)
# print(possible_coordinate)
is_find = False
if len(possible_coordinate) == 0:
# print('sssssssssssssssssssssss')
return False
for (row, col) in possible_coordinate:
# 对于每一个当前block可以填下数字ele的坐标而言
# 记录因在这个coordinate填写当前ele而改变的状态,保存下来
self.table[row][col] = ele
changed_coordinate = []
# 更改自身的值
changed_this_coordinate_ele = []
for tmp_ele in self.ele:
if self.coordinate_ele_jud[(row, col)][tmp_ele]:
self.coordinate_ele_jud[(row, col)][tmp_ele] = False
changed_this_coordinate_ele.append(tmp_ele)
# 更改同一个block的
a = int(block_num / 3)
b = int(block_num % 3)
for i in range(0, 3):
tmp_row = a * 3 + i
for j in range(0, 3):
tmp_col = b * 3 + j
if self.coordinate_ele_jud[(tmp_row, tmp_col)][ele]:
changed_coordinate.append((tmp_row, tmp_col))
self.coordinate_ele_jud[(tmp_row, tmp_col)][ele] = False
# 更改同行的
for tmp_row in range(0, 9):
if self.coordinate_ele_jud[(tmp_row, col)][ele]:
changed_coordinate.append((tmp_row, col))
self.coordinate_ele_jud[(tmp_row, col)][ele] = False
# 更改同列的
for tmp_col in range(0, 9):
if self.coordinate_ele_jud[(row, tmp_col)][ele]:
changed_coordinate.append((row, tmp_col))
self.coordinate_ele_jud[(row, tmp_col)][ele] = False
# 根据路径寻找下一个
# 如果下一个返回的是False,则代表不能找到
# 如果下一个返回的值是True,代表已经找到了结果
# print("coordinate = ", (row,col),"changed_coordinate = ", changed_coordinate)
is_find = self.search_a_puzzle(start + 1)
if is_find:
# self.table[row][col] = ele
break
else:
# 如果没有找到答案,则把已经更改的状态退回来
# 更改已经改过的
self.table[row][col] = 0
for (tmp_row, tmp_col) in changed_coordinate:
self.coordinate_ele_jud[(tmp_row, tmp_col)][ele] = True
for tmp_ele in changed_this_coordinate_ele:
self.coordinate_ele_jud[(row, col)][tmp_ele] = True
# 填不了了为什么没有回退上一个呢?
# 为什么会出现同行的现象? 改得不够彻底吗?
if is_find:
return True
else:
return False
# 重新开始我们的故事:
def clean_data(self):
for row in range(0, 9):
for col in range(0, 9):
self.table[row][col] = 0
for tmp_ele in self.ele:
self.coordinate_ele_jud[(row, col)][tmp_ele] = True
self.res = 81
self.start = 0
def write_answer_to_file(self, file_path):
file = codecs.open()
for tmp_table in self.ans:
for row in range(0, 9):
for col in range(0, 9):
tmp_ele = tmp_table[row][col]
if col == 8:
file.write(tmp_ele, "\n")
else:
file.write(tmp_ele, " ")
file.write("\n")
def solve_a_puzzle(self, table):
self.clean_data()
self.path = []
# 构建一个数据结构
# 这个数据结构里标着False的,代表这个单元格里面这个元素还没有被填入
print("the sudoko puzzle is :")
print("----------------------------------------------")
for row in table:
print(row)
print("----------------------------------------------")
print("")
block_num_ele = []
#block_num_ele最后用来统计哪一个已经填过了
left_block_num = [9, 9, 9, 9, 9, 9, 9, 9, 9]
for i in range(0, 9):
# 填1~9,全为True,0为False(0不填)
block_num_ele.append([False, True, True, True, True, True, True, True, True, True])
#读取table中的每一个数
left_block_num = []
for row in range(0, 9):
for col in range(0, 9):
ele = table[row][col]
self.table[row][col] = ele
# 如果是未填写的数,则继续
a = int(row / 3)
b = int(col / 3)
tmp_block_num = a * 3 + b
if ele == 0:
continue
# 如果是已经填写的数,先计算这个数所在的block
# 如果这个block里面已经填过了这个ele就填写False
block_num_ele[tmp_block_num][ele] = False
# 更改自身
for tmp_ele in self.ele:
self.coordinate_ele_jud[(row, col)][tmp_ele] = False
# 更改本block里面的其他坐标
for i in range(0, 3):
tmp_row = a * 3 + i
for j in range(0, 3):
tmp_col = b * 3 + j
self.coordinate_ele_jud[(tmp_row, tmp_col)][ele] = False
# 更改同行的
for tmp_row in range(0, 9):
self.coordinate_ele_jud[(tmp_row, col)][ele] = False
# 更改同列的
for tmp_col in range(0, 9):
self.coordinate_ele_jud[(row, tmp_col)][ele] = False
for tmp_block_num in range(0, 9):
for tmp_ele in range(1, 10):
if block_num_ele[tmp_block_num][tmp_ele]:
self.path.append((tmp_ele,tmp_block_num))
self.search_a_puzzle(0)
# 初始化状态后,统计每个元素剩余的代填格数是什么
UI.py中的代码
# 提交button的关联函数,会根据用户填写的信息进行报错,有健壮性
def submit():
ele = ['1', '2', '3', '4', '5', '6', '7', '8', '9']
for entry in entry_list:
print(entry.get())
if str(entry.get()) == '':
messagebox.showinfo(title="wrong",message="please fill all the blank")
return
if str(entry.get()) not in ele:
messagebox.showinfo(title="wrong",message="input should be integer and between[1,9]")
return
for i in range(0,len(entry_list)):
tmp_ele = entry_list[i].get()
(tmp_row, tmp_col) = coordinate_list[i]
table[tmp_row][tmp_col] = tmp_ele
jud = check()
if jud:
messagebox.showinfo(title="CONGRATULATIONS!", message="you've completed this sudoko puzzle!")
else:
messagebox.showinfo(title="SORRY:(", message="you don't finish this puzzle!")
7.最终时间安排
| PSP2.1 | personal software process stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 3000 | 1500 |
| Estimate | 估计耗时 | 3000 | 1500 |
| Development | 开发 | 1220 | 1240 |
| Analysis | 需求分析 | 60 | 90 |
| Design Spec | 文档设计 | 120 | 120 |
| Design Review | 设计审查 | 300 | 100 |
| Coding Standard | 代码规范 | 20 | 60 |
| Design | 设计 | 120 | 90 |
| Code Review | 代码复审 | 240 | 60 |
| Test | 测试 | 60 | 120 |
| Report | 报告 | 420 | 180 |
| Test Report | 测试报告 | 240 | 60 |
| Size Measurement | 计算工作量 | 60 | 60 |
| Postmoterm & process improvement plan | 事后总结并提出改进计划 | 120 | 60 |
| 合计 | 合计 | 4640 | 2920 |
8.个人总结
这次经历作为个人第一次开发软件的经历,其带给我的经验非常重要。
1.在软件需求上投入功夫
所谓好的开头是成功的一半,开头的设计应该成为以后软件开发最重要的环节。
2.使用合适的开发模型
一开始使用的是瀑布模型,后来发现在有限的时间内使用瀑布模型进行开发还是不够有效率,如果我今年没有修双学位加备考托福加修一堆网课和线下课的情况下,我可能不能发现其实以原型模型作为开发模型是非常有效率,且方便进行更改的。瀑布模型还是不够灵活。
3.咨询有经验的人
可以咨询一些有过开发经验的同学,要如何才能避免开发路上的坑。
4.Done is better than PERFECT!
先尝试再说,即便一开做的东西并不完美,但尝试后才有可能知道改进的地方。一个小demo能反应很多问题。
5.不畏困难
一开始我并不会UI的设计,我觉得UI设计很难(要做得好看确实不容易,但是简单的UI设计不需要投入很多功夫)。为什么我会这么认为呢?因为我的潜意识畏惧新的东西,在没有了解之前就已经告诉我“不可以”!我的大脑甚至都不会给我去了解这个领域的机会就拒绝了这个在未了解之前以为的难题。
我必须抗拒弗洛伊德提出的“本我”对自身的影响,意识到潜意识并且改变自己的潜意识。





















 到【灌水乐园】发言
到【灌水乐园】发言







