




数组处理
array_contains
判断ARRAY数组a中是否存在元素v。
boolean array_contains(array<T> <a>, value <v>)
array_intersect
求两个数组之间的交集
array_union
求两个数组之间的并集
array_expect
求两个数组之间的差集
select
array_intersect(array(1, 2), array(2, 3)) i,
array_union(array(1, 2), array(2, 3)) u,
array_except(array(1, 2), array(2, 3)) e; ![]()
聚合函数
count
从执行结果来看
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计
从执行效率来看
- 如果列为主键,count(列名)效率优于count(1)
- 如果列不为主键,count(1)效率优于count(列名)
- 如果表中存在主键,count(主键列名)效率最优
- 如果表中只有一列,则count(*)效率最优
- 如果表有多列,且不存在主键,则count(1)效率优于count(*)
参考:HiveSql面试题11详解(count(1)、count(*)和count(列名)的区别)_hive count1和count*的区别-优快云博客
分析函数导图
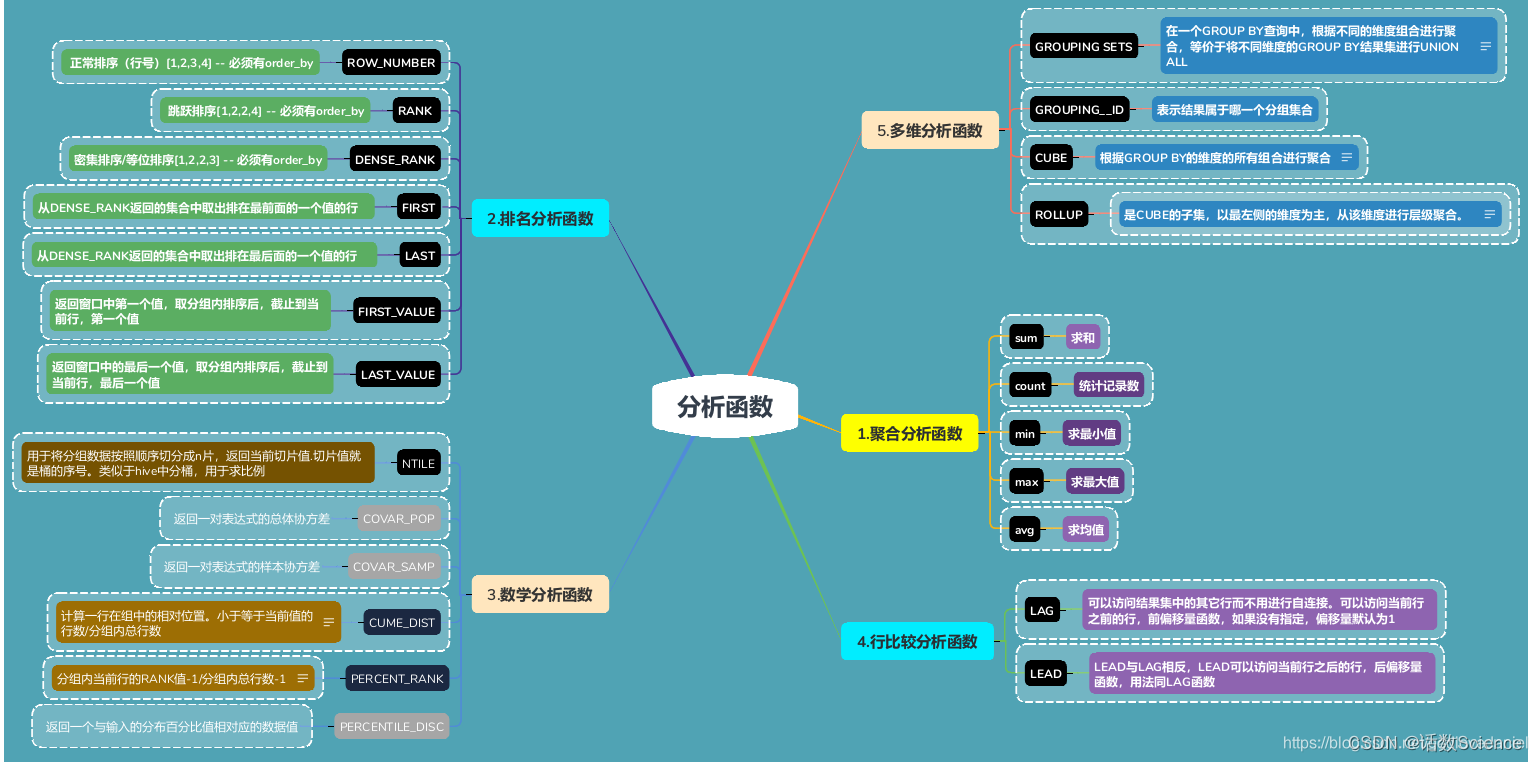
排名函数
row_number
排序相同时不会重复,唯一标记一条记录,顺序排名
SELECT
val,
row_number() over(ORDER by val) rn,
rank() over(ORDER by val) rk,
dense_rank() over(ORDER by val) drk
from (
select 1 as val
union all
select 1
union all
select 2
union all
select 2
union all
select 3
);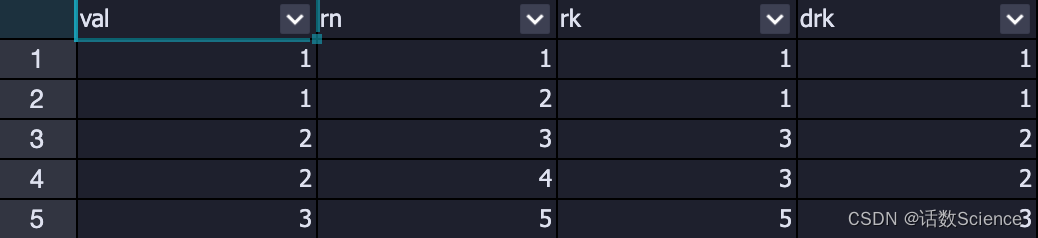
rank
排序相同时会重复,总数不变,跳跃排名
dense_rank
排序相同时会重复,总数会减少,等位排名
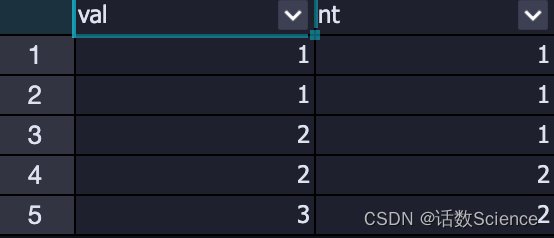
ntile
HIveSQL面试题17---按照某个字段进行动态分桶_hive sql 字段 分桶_莫叫石榴姐的博客-优快云博客参考: HIveSQL面试题17---按照某个字段进行动态分桶_hive sql 字段 分桶_莫叫石榴姐的博客-优快云博客
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值。将一个有序的数据集划分为多个桶(bucket),并为每行分配一个适当的桶数(切片值,第几个切片,第几个分区等概念)。它可用于将数据划分为相等的小切片,为每一行分配该小切片的数字序号。
NTILE不支持ROWS BETWEEN,比如NTILE(2) OVER(PARTITION BY dept_no ORDER BY salary ROWS BETWEEN 3 PRECEDING - AND CURRENT ROW)。
如果切片不均匀,默认增加第一个切片的分布。
Ntile函数使用
可以看成是:它把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。(这个算法在很多当中使用,spark中数据分片的时候也是这个算法,只不过是不均匀的时候,优先分配给较大编号的分片,如下图所示)
语法是:ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
ntile 用于将分组数据按照顺序切分成n片(n桶),返回当前切片值(桶序号).切片值就是桶的序号。类似于hive中分桶,用于求百分比。
对于一组数字(1,2,3,4,5,6),ntile(2)切片后为(1,1,1,2,2,2)
(1,2,3,4,5,6,7),ntile(2)切片后为(1,1,1,1,2,2,2)
其序号的标定类似于hive中分桶的原理。
又叫分桶函数或分片函数。ntile(n),n表示分桶或分片的个数。
SELECT
val,
ntile(2) over(ORDER by val) nt
from (
select 1 as val
union all
select 1
union all
select 2
union all
select 2
union all
select 3
);
percent_rank
percent_rank() 函数为分布函数:
- 用于返回某个排序数值在数据集中的百分比排位,其值分布在0-1之间【0,1】
- 此函数用于计算数值在数据集内的相对位置。
- 计算公式:当前行rn -1 / 组内行数 -1 其中减去1表示排位时候不包括他本身,表示他前面有多少人比他值低或高,在实际中有一定分析意义。
- 使用场景:用于关心排在我前面的有多少人。
- 如:班级成绩为例,返回的百分数60%表示某个分数排在班级总分排名前60%。
- 比如站队:我往往关心的是排在我前面的有多少人。如下一组数据:
- 如成绩为20的人,排在他前面的有5个人,除去自身,总共有6个人,那么他的相对排名百分比为 5/6
- 成绩为10的,排在他前面的有6个人,除去自身,那么整个群体中都比他的分数高,所以也就是100%
-
注意点:(1)percent_rank()对重复值的处理(2)percent_rank()对NULL值的处理
-
特点:首尾一定是0 和1
-
cume_dist():累积百分比
和percent_rank()差不多,区别在于是否排除自身影响
含义:
升序排序:表示小于等于当前值的人数所占百分比
降序排序:大于等于当前值的人数所占百分比 -
举例一:求去除最大最小值后的平均值
with salary as ( select '10001' emp_num , '1' dep_num , '60117' salary union all select '10002' emp_num , '2' dep_num , '92102' salary union all select '10003' emp_num , '2' dep_num , '86074' salary union all select '10004' emp_num , '1' dep_num , '66596' salary union all select '10005' emp_num , '1' dep_num , '66961' salary union all select '10006' emp_num , '2' dep_num , '81046' salary union all select '10007' emp_num , '2' dep_num , '94333' salary union all select '10008' emp_num , '1' dep_num , '75286' salary union all select '10009' emp_num , '2' dep_num , '85994' salary union all select '10010' emp_num , '1' dep_num , '76884' salary ) SELECT dep_num,cast(avg(salary) as decimal(18,0)) as avg_salary from( SELECT emp_num ,dep_num ,salary ,PERCENT_RANK() over(PARTITION BY dep_num ORDER BY salary) as rate from salary ) t where rate != 0 and rate != 1 group by dep_num; -
举例二

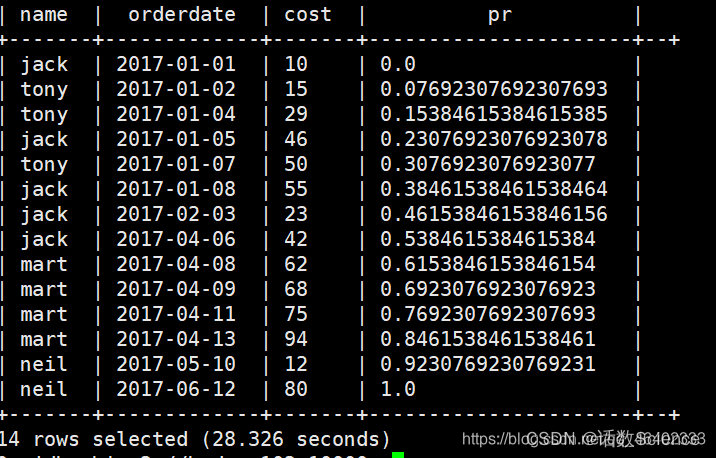
参考:HiveSql一天一个小技巧:如何巧用分布函数percent_rank()求去掉最大最小值的平均薪水问题_hive percent_rank_莫叫石榴姐的博客-优快云博客
cume_dist
计算一行在组中的相对位置。小于等于当前值的行数/分组内总行数。
with student as (
select '001' as classId,'001' as stuId,'math' as course,15 as score
union all
select '001','002','math',20
union all
select '001','003','math',35
union all
select '001','004','math',40
union all
select '001','005','math',48
union all
select '001','006','math',60
union all
select '001','007','math',69
union all
select '001','008','math',80
union all
select '001','009','math',89
union all
select '001','010','math',100
union all
select '001','001','english',99
union all
select '001','002','english',100
union all
select '001','003','english',87
union all
select '001','004','english',10
union all
select '001','005','english',50
union all
select '001','006','english',30
union all
select '001','007','english',58
union all
select '001','008','english',68
union all
select '001','009','english',78
union all
select '001','010','english',89
union all
select '002','001','math',15
union all
select '002','002','math',20
union all
select '002','003','math',35
union all
select '002','004','math',40
union all
select '002','005','math',48
union all
select '002','006','math',60
union all
select '002','007','math',69
union all
select '002','008','math',80
union all
select '002 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











