






1. 模板编译器
如果用户提供的options并没有render函数,则查找其携带的template字段提供的模板串,模板编译器则完成字符串解析成ast语法树的核心工具,关于AST语法树,
编译器将在AST语法树上标记各种关键信息 e.g: filter,text等标记
所谓的服务端喧嚷就是在服务端调用编译器执行编译输出相应render函数的一个过程,这样处理之后前端Vue库文件就不用携带编译器相关的源码,可以解除相关代码的打包,所以可以有效减少Vue js文件体积
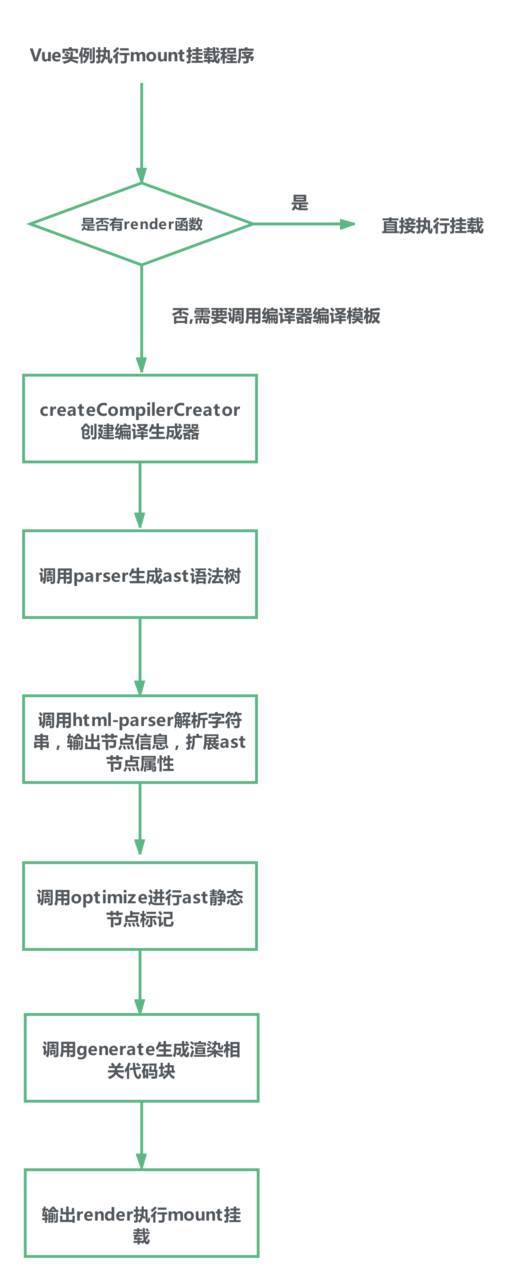
关于模板编译整体流程 文字表述
/**
* => Vue实例执行mount挂载,发现没有render函数,且提供了template字符串,需要调用编译器解析
* => 调用编译器生成动态节点渲染方法render和静态节点渲染方法集合staticRenderFns
* => 调用编译器的时候需要调用子方法parse把字符串解析成AST语法树,对节点进行字段扩展
* => parse中调用html-parse方法输入字符串,逐个输出关键字符节点信息
* => 在上述操作完成后,调用优化方法标记是否静态节点
* => 调用代码生成器,将AST语法树组装成可执行代码块
* => 向编译器调用方输出AST结果&render动态节点渲染函数&staticRenderFns静态节点渲染函数集合
* */
复制代码关于模板编译整体流程 流程导图展示
2. 模板编译核心之html-parser
模板解析的本质是字符的逐一循环处理,所以性能消耗比较大,服务端渲染有比较明显的性能优势
2.1 模板解析中用到的正则梳理
attribute 属性匹配正则
关于正则表达式相关知识可以点击这里正则 掘金
/**
* ^\s* 空白符开头 一个或多个
* ([^\s"'<>\/=]+) 匹配属性名称的子表达式 非空白符且不是"'<>\/=
* (?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+))) 后半部分子表达式
* ?: 非捕获组,不缓存匹配记录,对属性这种高频出现的正则匹配有明显的性能提升
* \s*(=)\s*
* (?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)) 属性值部分
* "([^"]*)"+ "包裹除它本身的0或多个符合条件的内容
* |'([^']*)'+ 或者'包裹除它本身的0或多个符合条件的内容
* |([^\s"'=<>`]+)) 或者没有两者包裹的不包含空白符和这些指定字符的内容
* */
/**
* 该正则匹配的情况如下
*
* */
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
复制代码dynamicArgAttribute 指令正则匹配
与attribute的区别是 属性名称是一个变量
/**
* ^\s*((?:v-[\w-]+:|@|:|#)\[[^=]+\][^\s"'<>\/=]*) 前半部分
* ^\s* 空白符开头 一个或多个
* (?:v-[\w-]+:|@|:|#) 这边就是经常出现的v-指令匹配,:指令匹配,@事件绑定匹配 #slot绑定,[w-]还加个- 这种情况比较少 可能是匹配 v-re-get 也就是用户可能自定义个指令re-get
* \[[^=]+\] 动态属性匹配的关键正则 v-bind[name]="" 绑定的属性名称是变量的时候
* ([^\s"'<>\/=]+) 匹配属性名称的子表达式 非空白符且不是"'<>\/=
* (?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+))) 后半部分子表达式
* ?: 非捕获组,不缓存匹配记录,对属性这种高频出现的正则匹配有明显的性能提升
* \s*(=)\s*
* (?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)) 属性值部分
* "([^"]*)"+ "包裹除它本身的0或多个符合条件的内容
* |'([^']*)'+ 或者'包裹除它本身的0或多个符合条件的内容
* |([^\s"'=<>`]+)) 或者没有两者包裹的不包含空白符和这些指定字符的内容
* */
/**
* 该正则匹配的情况如下
*
*
* */
const dynamicArgAttribute = /^\s*((?:v-[\w-]+:|@|:|#)\[[^=]+\][^\s"'<>\/=]*)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
复制代码startTagOpen 开始标签起点匹配正则
startTagClose 开始标签终点匹配正则
engTag 结束标签匹配正则
/**
* 上述三个标签正则类型都以下面正则为基础
* */
ncname = `[a-zA-Z_][\\-\\.0-9_a-zA-Z${unicodeRegExp.source}]*` // 解析 \\-\\. 这边ncname是个字符串 并不是正则表达式 所以需要双反斜杠表示
复制代码
2.2 parseHTML字符串解析流程
我们将用文字来表述整个过程,比较冗长,具体源码等可以看我的仓库代码并附有注释
假设要处理的html代码如下:
Normal
level2
level3
level4
名字
姓氏
用来测试expectHTML-p
测试双括号号输出 -- {{username}} -- Mustache语法
复制代码
2.2.1 第一批次解析
const stack = [] // 定义栈,用来存放解析过程中的标签信息
let index = 0 // 定义游标,用来标记当前字符串处理位置
let last, lastTag // last用来备份字符流数据,lastTag用来标记结尾标签信息
/**
* 1. 如果html不为空,备份数据last=html,此时不存在lastTag
* 2. 查找左尖括号的位置,定位非纯文本的位置,此时textEnd === 0
* 3. 当前开头字串略过注释,条件注释,开始标签终点匹配,结束标签匹配,执行开始标签解析
* 4. 命中开始标签匹配,定义match对象,挂载标签名称,初始化属性数组,记录开始索引start
* 5. 调用advance方法游标前移,html从游标位置往后截取
* 6. 定义end,attr分别存储开始标签终点匹配信息,attr属性匹配信息,开始循环匹配
* 7. 命中属性匹配 class,attr对象记录属性开始索引start,结束索引end,压入前面match对象挂载的attrs数组
* 8. 调用advance,命中开始标签终点,非自闭合标签且需要斜杠标记结尾,前移索引,解析结果如下信息
* match = {
* tagName: 'section',
* start: 0,
* end: 36,
* attrs: [
* {
* 0: 'class="html-parse-example"', // 匹配到的全部内容
* 1: 'class', // 第一个子表达式内容 属性名称
* 2: '=', // =
* 3: 'html-parse-example' // 第三个子表达式匹配内容 表达式
* start: 8,
* end: 35,
* }
* ]
* }
* 9. 处理开始标签匹配结果,整理属性集合,获取属性名称和value表达式
* const args = match.attrs[i]
* const value = args[3] || args[4] || args[5] || '' [3], [4], [5]分别表示第3,4,5子表达式正则匹配的表达式
* let html = 'v-html="html | xxxxxxxx"' args[3]
* let html = "v-html='html | xxxx'" args[4]
* let html = "v-html=html" args[5]
* 10. 不是自闭合标签,压入栈标签信息
* 11. 如果options.start存在,抛出相关匹配信息
* 12. 此时stack=[
* {
* tag: 'div',
* lowerCasedTag: 'div',
* attrs: [...],
* start: ,
* end:
* }
* ]
* */
复制代码
2.2.1 第二批次解析
/**
* 1. 解析到注释标签,如果options带有comment方法且标记需要保存注释内容,则调用comment抛出注释相关的索引,内容等信息
* 2. 注释和条件注释等并不会把相关信息压入栈
* 3. div(level4)处理完开始标签部分
* 4. 此时lastTag = 'div' // class="level4"
* 5. 此时stack=[
* {
* tag: 'div', // class="html-parse-example"
* lowerCasedTag: 'div',
* attrs: [...],
* start: ,
* end:
* },
* {
* tag: 'div', // class="level1"
* },
* {
* tag: 'div', // class="level2"
* }
* {
* tag: 'div', // class="level3"
* }
* ]
* */
复制代码
2.2.1 第三批次解析
此时剩余的html内容如下:
名字
姓氏
用来测试expectHTML-p
测试双括号号输出 -- {{username}} -- Mustache语法
复制代码其实我觉得只要在pos的位置索引不等于stack的末尾索引不就是没有匹配的标签吗 pos !== stack.length - 1就报错
/**
* 当前lastTag='div'
* 1. 匹配到结束标签
* 2. 开始回溯 stack从末端开始遍历 找到与之匹配的元素 我们回头找到在最末尾位置 找到之后记住pos = 3
* 3. pos >= 0成立,再次逆向遍历stack,如果在i>pos位置上存在标签 则是没有对应结束标签的情况,报错has no matching end tag
* 4. 我们这边是正常结束 i === pos 所以执行options.end(stack[i].tag, start, end)
* 5. 以pos为末端截断stack,相当于栈弹出末端元素
* */
复制代码
2.2.2 第四批次解析
此时剩余的html内容如下:
/>
姓氏
用来测试expectHTML-p
测试双括号号输出 -- {{username}} -- Mustache语法

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









