





 本文讨论并实施MixMatch半监督学习算法,其性能优于以往方法。半监督学习针对过拟合,MixMatch结合三种正则化形式。还介绍了基于Pytorch的fastai库,以及MixMatch所需的数据增强、Mixup等组件,阐述了它们在算法中的应用和作用。
本文讨论并实施MixMatch半监督学习算法,其性能优于以往方法。半监督学习针对过拟合,MixMatch结合三种正则化形式。还介绍了基于Pytorch的fastai库,以及MixMatch所需的数据增强、Mixup等组件,阐述了它们在算法中的应用和作用。
在这篇文章中,我将讨论和实施Berthelot,Carlini,Goodfellow,Oliver,Papernot和Raffel 的“MixMatch: A Holistic Approach to Semi-Supervised Learning”。MixMatch于2019年5月发布,是一种半监督学习算法,其性能明显优于以前的方法。
MixMatch有多大改进呢?当使用250张标记图像对CIFAR10进行训练时,MixMatch在error rate上的表现优于第二最佳技术(Virtual Adversarial Training)近25%(11.08%对36.03%;所有50k图像的监督情况的error rate为4.13%)。
半监督学习主要是针对过度拟合; 当标记集很小时,不需要非常大的神经网络来记忆整个训练集。几乎所有半监督方法背后的一般思想是利用未标记的数据作为标记数据训练的正则化器。不同的技术采用不同形式的正则化,MixMatch论文将它们分为三组:熵最小化,一致性正则化和通用正则化。由于这三种正则化形式都被证明是有效的,所以MixMatch算法包含了它们各自的特性。
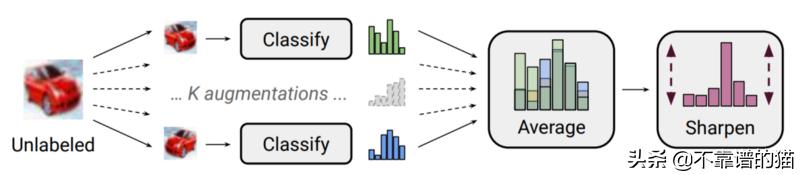
MixMatch是近年来出现的几种技术的组合和改进,包括:Mean Teacher,Virtual Adversarial Training和Mixup。MixMatch的想法是使用模型中的预测标记未标记的数据,然后以多种形式应用正则化。第一种是多次执行数据增加并取标签预测的平均值。然后,这些预测被“sharpened”以减少其熵。最后,在标记和未标记的组上进行Mixup。
fastai
Fastai是一个基于Pytorch构建的机器学习库,它使编写机器学习应用程序变得更加容易和简单。与纯Pytorch相比,fastai显著减少了生成神经网络所需的样板代码量。在这里,我们将使用fastai的数据管道和训练循环特性。
#Importing fastai will also import numpy, pytorch, etc. from fastai.vision import *from numbers import Integralimport seaborn as sns
Components
让我们首先描述MixMatch所需的各个部分,然后将它们组合在一起以形成完整的算法。在本文之后,我们将使用CIFAR10,随机选取500幅图像作为标记训练集。所有准确度都使用标准的10000幅图像测试集。
数据增强
数据增强是一种广泛应用的一致性正则化技术,其在计算机视觉领域中取得了最大成功。其思想是在保留其语义标签的同时修改输入数据。对于图像,常见的增强包括旋转、裁剪、缩放、增白等——所有的转换都不会改变图像的基本内容。MixMatch更进一步,多次执行增强以生成多个新图像。然后对这些图像上的模型预测进行平均,以产生未标记数据的目标。这使得预测比使用单一图像更可靠。研究人员发现,只要增加两次就足以看到这种好处。
Fastai有一个高效的转换系统,我们将利用它来处理数据。由于它被设计为每个图像只产生一个增强,我们需要几个,我们将从修改默认的标签列表开始,以发出多个增强。
#Modified from K=2class MultiTransformLabelList(LabelList): def __getitem__(self,idxs:Union[int,np.ndarray])->'LabelList': "return a single (x, y) if `idxs` is an integer or a new `LabelList` object if `idxs` is a range." idxs = try_int(idxs) if isinstance(idxs, Integral): if self.item is None: x,y = self.x[idxs],self.y[idxs] else: x,y = self.item ,0 if self.tfms or self.tfmargs: #I've changed this line to return a list of augmented images x = [x.apply_tfms(self.tfms, **self.tfmargs) for _ in range(K)] if hasattr(self, 'tfms_y') and self.tfm_y and self.item is None: y = y.apply_tfms(self.tfms_y, **{**self.tfmargs_y, 'do_resolve':False}) if y is None: y=0 return x,y else: return self.new(self.x[idxs], self.y[idxs]) #I'll also need to change the default collate function to accomodate multiple augmentsdef MixmatchCollate(batch): batch = to_data(batch) if isinstance(batch[0][0],list): batch = [[torch.stack(s[0]),s[1]] for s in batch] return torch.utils.data.dataloader.default_collate(batch)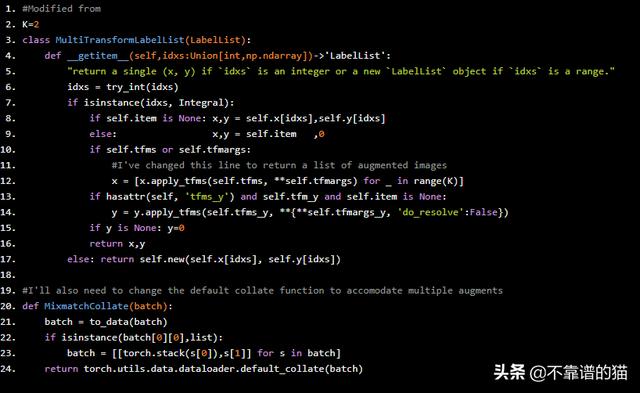
Fastai的data block api允许灵活地加载,标记和整理几乎任何形式的数据。但是,它没有一种方法来获取一个文件夹的子集和整个文件夹,这是必需的。因此,我们将继承ImageList类并添加自定义方法。我们将使用get_transforms方法,Fastai的变换系统在应用时自动随机化每个变换的精确参数。
#Grab file path to cifar dataset. Will download data if not presentpath = untar_data(URLs.CIFAR)#Custom ImageList with filter functionclass MixMatchImageList(ImageList): def filter_train(self,num_items,seed=2343): train_idxs = np.array([i for i,o in enumerate(self.items) if Path(o).parts[-3] != "test"]) valid_idxs = np.array([i for i,o in enumerate(self.items) if Path(o).parts[-3] == "test"]) np.random.seed(seed) keep_idxs = np.random.choice(train_idxs,num_items,replace=False) self.items = np.array([o for i,o in enumerate(self.items) if i in np.concatenate([keep_idxs,valid_idxs])]) return self #Create two databunch objects for the labeled and unlabled images. A fastai databunch is a container for train, validation, and#test dataloaders which automatically processes transforms and puts the data on the gpu.data_labeled = (MixMatchImageList.from_folder(path) .filter_train(500) #Use 500 labeled images for traning .split_by_folder(valid="test") #test on all 10000 images in test set .label_from_folder() .transform(get_transforms(),size=32) #On windows, must set num_workers=0. Otherwise, remove the argument for a potential performance improvement .databunch(bs=64,num_workers=0) .normalize(cifar_stats))train_set = set(data_labeled.train_ds.x.items)src = (ImageList.from_folder(path) .filter_by_func(lambda x: x not in train_set) .split_by_folder(valid="test"))src.train._label_list = MultiTransformLabelListdata_unlabeled = (src.label_from_folder() .transform(get_transforms(),size=32) .databunch(bs=128,collate_fn=MixmatchCollate,num_workers=0) .normalize(cifar_stats))#Databunch with all 50k images labeled, for baselinedata_full = (ImageList.from_folder(path) .split_by_folder(valid="test") .label_from_folder() .transform(get_transforms(),size=32) .databunch(bs=128,num_workers=0) .normalize(cifar_stats))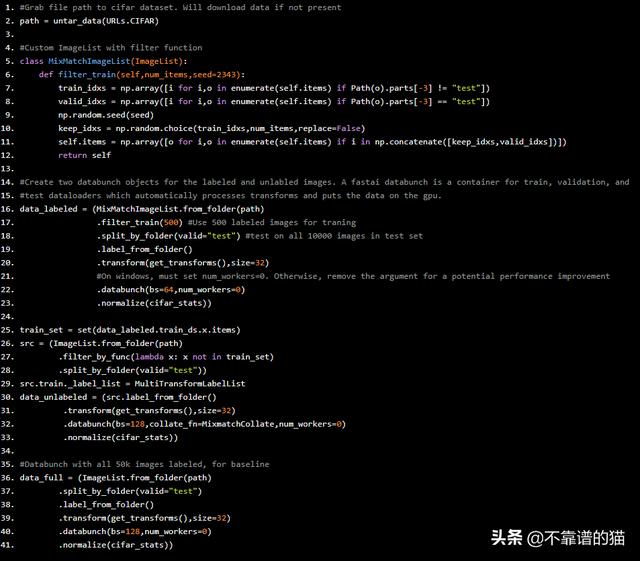
Mixup
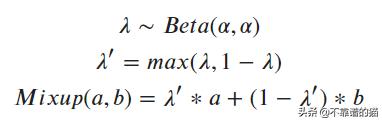
Mixing最初是由Zhang,Cisse,Dauphin和Lopez-Paz在2018年引入的,属于一般或传统正规化的范畴。Mixup不是将单个图像传递给模型,而是在两个单独的训练图像之间执行线性插值,并将其传递给模型。使用与图像相同的λ系数,也对图像的One hot编码标签进行插值。该系数是从β分布中随机抽取的,由alpha参数化。在α值较小时,β分布的tails大部分weight接近0或1。随着α增加,分布变得均匀,然后越来越接近0.5。因此,α可以被视为控制mixup的强度; 小值只会产生少量mixup,而较大的值偏向最大mixup(50/50)。在极端情况下,α= 0导致根本没有混淆,当α→∞时,β接近以0.5为中心的狄拉克δ分布。作者建议从.75的值开始。论文对原方法进行了一次修改,即将λ设置为max(λ,1-λ); 这使mixup偏向原始图像。
from scipy.stats import betax = np.linspace(0.01,0.99, 100)fig, axes = plt.subplots(1,5,figsize=(36,5))fig.suptitle(r"$beta(alpha,alpha)$ Distribution

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









