





 本文介绍了MapReduce的定义、核心思想以及其在Hadoop2.0架构下的工作原理。详细解析了MapReduce如何利用Master/Slave架构进行分布式计算,以及在引入YARN后的资源管理和任务调度机制。
本文介绍了MapReduce的定义、核心思想以及其在Hadoop2.0架构下的工作原理。详细解析了MapReduce如何利用Master/Slave架构进行分布式计算,以及在引入YARN后的资源管理和任务调度机制。
浅析MapReduce原理及其执行过程
一、MapReduce定义及核心思想
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架。用户可以基于该框架轻松的编写应用程序,而这些应用程序能够运行在由上千个商用服务器组成的大集群上,并以一种可靠的,具有高容错能力的方式并行处理上TB级别的海量数据集。
MapReduce的核心思想就是“分而治之”。
1.将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce中。
2.编程容易,开发人员不需要掌握分布式并行编程细节,也可以很容易的把自己的程序运行在分布式系统上,然后完成海量计算。
3.MapReduce采用“分而治之”的策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
4.MapReduce设计的理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,这样就减少了大量的网络传输开销。
5.MapReduce框架采用了Master/Slave架构,包括一个Master和若干个slave,master上运行JobTracker,slave上运行TaskTracker
6.Hadoop框架使用java实现的,但是,MapReduce应用程序则不一定要有java来写。
三、MapReduce的架构
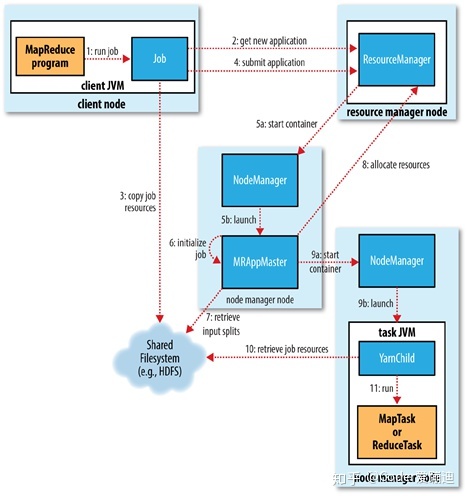
如图所示MapReduce中包含的组件:
1.客户端:提交MapReduce作业
2.YARN的资源管理器(Resource Manager),协调集群中资源的分配
3.YARN的节点管理器(Node Manager)启动并监控集群中的计算容器。
4.MapReduce的Application Master,协调MapReduce作业中任务的运行。Application Master和MapReduce任务运行于容器中。这些容器由resourcemanager调度,由namenode管理。
5.分布式文件系统(HDFS),在组建之间共享作业数据。
上述所讲的是在引入YARN的Hadoop2.0的资源管理系统,核心思想是将MRv1中JobTracker的 资源管理 和 任务调度 两个功能分别由ResourceManager和ApplicationMaster进程实现。
其中ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务、比如任务调度、任务监控和容错等。每个应用程序对应一个ApplicationMaster,并且YARN的引入,使得多个计算框架(Spark,MapReduce,storm等)可运行在一个集群中。
MapReduce On YARN
基本功能模块:
YARN:负责集群中的资源管理和调度。
MRAPPMaster:负责任务调度、任务监控和失败重试等。
MapTask/ReduceTask:Common任务驱动引擎,与MRv1一致。
MRAPPMaster容错:
如果MRAPPMaster启动失败后,由YARN重新启动
如果任务失败,MRAPPMaster会重新向ResourceManager重新申请资源。
MR任务执行流程:
如图所示:
1.当客户端JobSubmitter提交任务时,会先向ResourceManager申请一个新的application ID,用于MapReduce作业的ID,并且会获得和任务相关文件的元数据信息。
2.当客户端获取ID和元数据信息后,就会执行一系列的检查操作
(a)检验输入目录或者文件是否存在,不存在则MR抛出异常。
(b)如果没有指定输出路径,或者输出路径已经存在,则不提交作业,MapReduce程序抛出异常。
(c)计算任务的切片信息,如果不能计算出切片,则不执行第三步,MR抛出异常。
3.在上面的检查和计算都完成后,客户端向共享文件存储系统的以作业ID命名的目录中提交多份(默认是10份)任务信息(配置文件/jar包/计算好的输入切片等),并向ResourceManager发送请求。然后自身进入轮询状态,监控作业执行的进度,每秒发送一次请求,请求作业执行进度,如果进度有变,则在控制台打印进度信息。
因为后续执行计算时,很多NodeManager都会来抓取集群中的任务信息,份数越多,NodeManager的读取效率越高。
4.YARN框架的RM收到客户端的请求后,调用NodeManager,并由NodeManager在本机上分配一个容器(1G内存,一个虚拟核心)运行ApplicationMaster程序。
5.MRAPPMaster,会去HDFS中收集客户端发送过来的任务信息进行分析,需要多少个Map任务,多少个reduce任务,分析完毕后,向ResourceManager发送请求。
(a)MapReduce作业的application master是一个java app,主入口类是MPAPPMaster,它会从HDFS抽取客户端计算好的输入切片,为每一个切片创建一个map任务对象,以及一定数量的reduce任务对象。
(b)application master会为作业中所有的map任务以及reduce任务向ResourceManager请求容器,为map任务的请求会首先进行并且相对于reduce任务请求有更高的优先级。并且当map任务完成率达到了5%之后才会为reduce任务发送容器请求。
(c)请求会指定每个任务需要的内存和CPU资源。并且可以通过修改
mapreduce.map.memory.mb,
mapreduce.reduce.memory.mb,
mapreduce.map.cpu.vcores,
mapreduce.reduce.cpu.vcores进行相关的个性化配置。
6.ResourceManager收到请求后,会去调度NodeManager为 任务分配容器,application master会与这个NodeManager进行通信,启动容器。任务由java app来执行,该app的主入口类是YarnChild。在开始执行任务之前,它会本地化任务的资源,包括jar包,配置文件,以及HDFS中存储的其他共享文件。然后开始执行MapTask或者ReduceTask。
MapReduce计算过程:
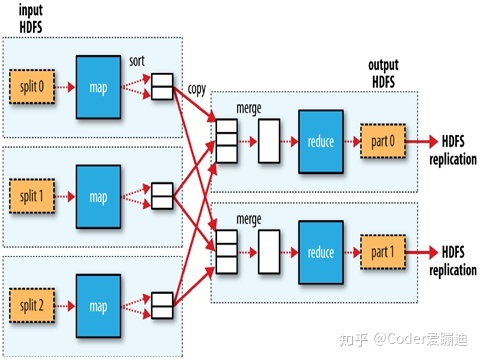
reduce任务可以运行于集群中的任意位置,而map任务只能在本地进行数据的读取和计算。这里有一个 移动计算 的概念。因为在客户端第一次请求时,ResourceManager就会将任务的所有元数据信息返回给客户端,然后客户端进行计算和检验,然后将这些数据打包并提交到HDFS,MRAPPMaster会执行分析, 获得数据的存储位置 交给RM来分配调度NM,最终参与map运算的数据都存储在本机上。然后在开始执行任务之前,本地化任务的资源,从HDFS中拉取各项资源开始执行计算。这样就避免了集群中数据的大量移动,只需要发送一些配置文件,jar包,运算程序等。
在真正开始执行时,Map会将输入的数据集进行逻辑切片,然后各个节点上的map任务以并行的方式处理切片数据。每个block会在逻辑上分成若干的切片数据,每个切片数据计算完成后进行排序型形成一个有序数列,由内存写入一个环形缓冲区,然后再由环形缓冲区写入磁盘,因为内存对磁盘的读写会产生大量的I/O,并且内存的运行速度远远大于磁盘,所以先将运算结果写入读写速度与内存相差不大的缓冲区,再由缓冲区写入磁盘。一个map在执行切片的计算过程中,会不断的产生有序的切片,这时候,MapReduce会对这些有序的切片不断执行归并操作,形成一个更大的有序文件,并且合并相同的元素,比如10个<"hello","1">会合并成<"hello","10">以此来减少map和reduce之间的数据传输量。
maper和reducer间的数据传输:
当map任务完成5%的时候MRAPPMaster才会为reduce任务发送请求,reducer通过HTTP按照分区号获取map输出文件的数据,对map的执行结果进行分区,比如上图有两个reduce,可以将map的运算结果的key值mod2。map端有一个HTTP服务处理该redurce的Http请求,该HTTP请求服务最大线程数由mapreduce.shuffle.Max.threads属性指定。这个属性 指定NodeManager的线程数,而不是对map任务指定线程数,因为一个NodeManager上可能会运行好几个map任务。默认是0,表示最大线程数是服务器处理器核心数的两倍。
map输出文件位于map任务的本地磁盘,一个reduce任务需要从集群中多个map任务获取指定分区的数据,多个map任务可能是在不同时间完成的,每当一个map任务运行完成,reduce就从该map任务获取指定分区数据。reduce任务会以多线程的方式从多个map任务并行获取指定分区数据。默认线程数是5,可以通过mapredurce.redurce.shuffle.parallelcopies属性指定。
reducer拷贝map的输出如果很小,则放在内存中(mapreduce.reduce.shuffle.input.buffer.percent指定堆空间百分比)否则拷贝到磁盘中。当内存缓冲数据大小达到阈值(mapreduce.reduce.shuffle.merge.percent)或map输出文件个数达到阈值(mapreduce.reduce.merge.inmem.threshold),就会发生文件合并溢写在磁盘上。如果指定了combiner,此处也会进行combine。
当reducer从所有的map拷贝了分区数据后,reduce进入到了合并阶段,合并所有从map拷贝过来的数据。该合并会有多个回合。如50个文件,合并因子是10(mapreduce.task.io.sort.factor,默认10),则需要5轮,得到5个中间文件就不再合并了。然后直接输出给reduce阶段。给reduce的数据一般是从内存和磁盘数据的混合形式。
MapReduce元语:“相同的key的键值对为一组调用reduce方法,方法内迭代这一组数据进行计算”。
例如:map1传过来<"hello","20">
map2传过来<"hello","10">
map3传过来<"hello","15">
reduce端会先将几个map传过来的数据进行归并,他们的键值都相同,所以会放在一起,然后reduce方法迭代计算,进行统计。
当作业的最后一个任务完成后,就会通知MRAPPMaster,MRAPPMaster就会更改作业状态为“successfully”。作业就会打印信息告知客户端,客户端waitForCompletion方法返回。并在控制台打印作业的统计信息和计数器信息。
作业完成,application master所在容器和任务所在容器销毁工作状态(中间的输出结果删除)作业的信息被作业历史服务器存档一杯以后查询使用。

















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









