







目录
2问:着色器的编译过程是什么?为什么需要创建多个着色器对象?
8问:冯氏光照模型((Phong Lighting Model)有哪几个分量组成?
10问:绘制一个带有不透明和透明物体的场景,渲染顺序是什么?
17问:三种旋转表示(四元数,欧拉角,矩阵)各自的优缺点是什么?
22问:基于物理的渲染(Physically Based Rendering)需要满足哪些条件?
1问:图形渲染管线的流程是什么?
答:图形渲染管线的流程如图所示
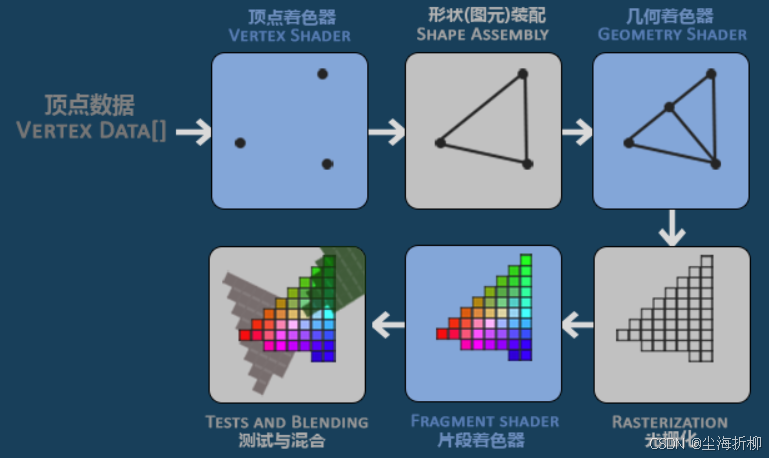
首先,我们以数组的形式传递3个3D坐标作为图形渲染管线的输入,用来表示一个三角形,这个数组叫做顶点数据(Vertex Data);顶点数据是一系列顶点的集合。一个顶点(Vertex)是一个3D坐标的数据的集合。而顶点数据是用顶点属性(Vertex Attribute)表示的,它可以包含任何我们想用的数据。
-
顶点着色器(Vertex Shader) :把一个单独的顶点作为输入。顶点着色器主要的目的是把3D坐标转为另一种3D坐标,同时顶点着色器允许我们对顶点属性进行一些基本处理。
-
图元装配(Primitive Assembly):将顶点着色器输出的所有顶点作为输入并将所有的点装配成指定图元的形状;
-
几何着色器(Geometry Shader):把图元形式的一系列顶点的集合作为输入,它可以通过产生新顶点构造出新的(或是其它的)图元来生成其他形状。
-
光栅化阶段(Rasterization Stage):几何着色器的输出会被传入光栅化阶段,会把图元映射为最终屏幕上相应的像素,生成供片段着色器(Fragment Shader)使用的片段(Fragment)。在片段着色器运行之前会执行裁切(Clipping)。裁切会丢弃超出你的视图以外的所有像素,用来提升执行效率。
-
片段着色器(Fragment Shader):片段着色器的主要目的是计算一个像素的最终颜色,这也是所有OpenGL高级效果产生的地方。通常,片段着色器包含3D场景的数据(比如光照、阴影、光的颜色等等),这些数据可以被用来计算最终像素的颜色。
-
Alpha测试和混合(Blending):在所有对应颜色值确定以后,最终的对象将会被传到Alpha测试和混合(Blending)阶段。这个阶段检测片段的对应的深度和模板(Stencil))值,用它们来判断这个像素是其它物体的前面还是后面,决定是否应该丢弃。这个阶段也会检查alpha值(alpha值定义了一个物体的透明度)并对物体进行混合(Blend)。所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
2问:着色器的编译过程是什么?为什么需要创建多个着色器对象?
答:着色器编译过程如下所示:
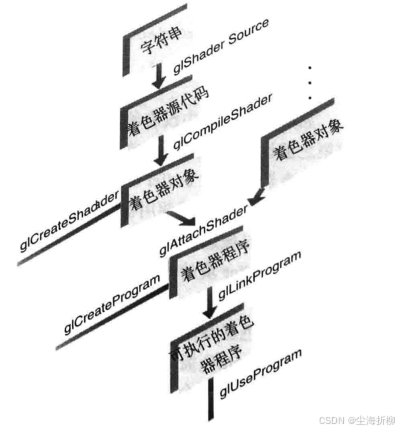
对于每个着色器对象,都需要进行的操作过程如下:
- 创建一个着色器对象(glCreateShader(GLenum type));
- 将着色器源代码编译为对象(GLuint glShaderSource)
- 验证着色器编译是否成功 (glCompileShader)
然后需要将多个着色器对象链接为一个着色器程序
- 创建一个着色器程序(glCreateProgram)
- 将着色器对象关联到着色器程序(glAttachShader)
- 链接着色器程序(glLinkProgram)
- 判断着色器的链接过程是否成功完成(glGetProgramInfoLog)
- 使用着色器来处理顶点和片元(glUseProgram)
创建多个着色器对象的原因:在实际开发中,我们可能在不同的程序中复用同一个函数,在GLSL程序中也是一样,创建的通用函数可以在多个着色器中得到复用,因此不需要使用大量的通用代码来编译大量的着色器资源,只需要将合适的着色器对象链接到一个着色器程序上就可以了。
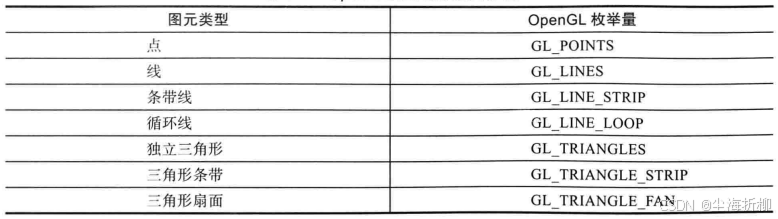
3问:图形学中有哪几类不同的图元?
答:图形学中主要有三大类图元,分别是点、线、和三角形,线和三角形图元类型可以在组合成条带、循环体和扇面。闭合的多线段叫做循环线(line loop),开放的多段线(没有首尾闭合)叫做条带线(line strip)图元模式标识有:
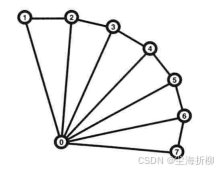
三角形条带的顶点布局如图所示:

三角形扇面的顶点布局:
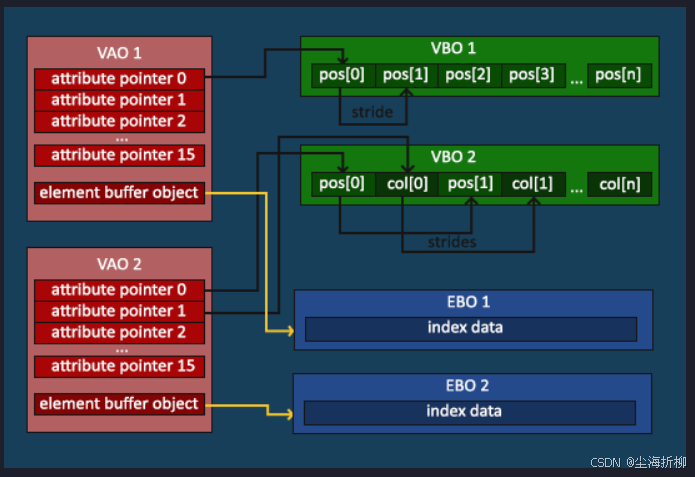
4问:VBO,VAO,EBO分别是什么?
答:VAO,VBO,EBO示意图如下所示:
-
顶点缓冲对象(Vertex Buffer Objects, VBO):管理这在GPU上创建的显存。使用这些缓冲对象的好处是我们可以一次性的发送一大批数据到显卡上,而不是每个顶点发送一次。从CPU把数据发送到显卡相对较慢,所以只要可能我们都要尝试尽量一次性发送尽可能多的数据。当数据发送至显卡的内存中后,顶点着色器访问顶点是个非常快的过程的。
-
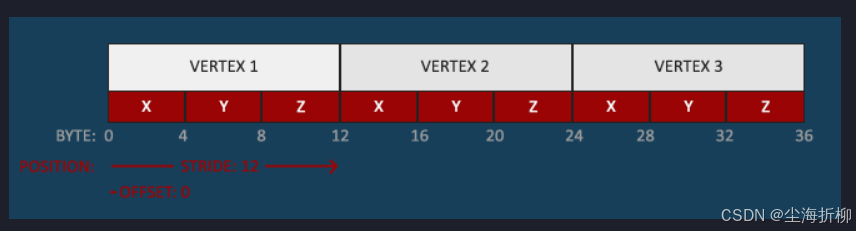
顶点数组对象(Vertex Array Object, VAO):当把顶点数据发送给了GPU,但OpenGL还不知道它该如何解释内存中的顶点数据。GPU内的这块显存区域里是紧密连续的一个个数据,我们需要告诉OpenGL,从哪里到哪里是一个顶点的数据,从哪里到哪里是这个顶点的RGB值,等等。同时,我们也该告诉OpenGL,该如何将顶点数据链接到顶点着色器的属性上。
顶点缓冲数据会被解析为下面这样子:
- 元素缓冲对象(Element Buffer Object,EBO) :也叫索引缓冲对象(Index Buffer Object,IBO),作用是以顶点索引的方式进行渲染,可以大幅度提升渲染效率,规避掉很多重复的顶点数据。
5问:纹理过滤有哪几种方式?
答:纹理过滤有两种最主要的过滤方式:GL_NEAREST和GL_LINEAR。
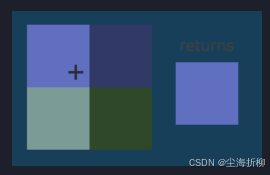
- GL_NEAREST(邻近过滤,Nearest Neighbor Filtering):是OpenGL默认的纹理过滤方式。当设置为GL_NEAREST的时候,OpenGL会选择中心点最接近纹理坐标的那个像素。下图中你可以看到四个像素,加号代表纹理坐标。左上角那个纹理像素的中心距离纹理坐标最近,所以它会被选择为样本颜色:
GL_LINEAR(也叫线性过滤,(Bi)linear Filtering)它会基于纹理坐标附近的纹理像素,计算出一个插值,近似出这些纹理像素之间的颜色。一个纹理像素的中心距离纹理坐标越近,那么这个纹理像素的颜色对最终的样本颜色的贡献越大。下图中你可以看到返回的颜色是邻近像素的混合色:

在一个很大的物体上应用一张低分辨率的纹理分别使用邻近过滤和线性过滤的效果如下:

GL_NEAREST产生了颗粒状的图案,我们能够清晰看到组成纹理的像素,而GL_LINEAR能够产生更平滑的图案,很难看出单个的纹理像素 。
6问:简述引入Mipmap的作用和解决了什么实际问题?
答:假设我们有一个包含着上千物体的大场景,场景中每个物体上都有纹理。有些物体会很远,但其纹理会拥有与近处物体同样高的分辨率。由于远处的物体可能只产生很少的片段,OpenGL从高分辨率纹理中为这些片段获取正确的颜色值就很困难,因为它需要对一个跨过纹理很大部分的片段只拾取一个纹理颜色。在小物体上这会产生不真实的感觉,对它们使用高分辨率纹理同时也会浪费很大的内存。Mipmap(多级渐远纹理)是一系列的纹理图像,后一个纹理图像是前一个的二分之一。多级渐远纹理背后的理念是:距观察者的距离超过一定的阈值,OpenGL会使用不同的多级渐远纹理,即最适合物体的距离的那个。由于距离远,解析度不高也不会被用户注意到。同时,多级渐远纹理另一加分之处是它的性能非常好。让我们看一下多级渐远纹理是什么样子的:

7问:常用的坐标系统有哪几种,它们之间是如何进行转换的?
答:常见的坐标系统有:
- 局部空间(Local Space,或者称为物体空间(Object Space))
- 世界空间(World Space)
- 观察空间(View Space,或者称为视觉空间(Eye Space))
- 裁剪空间(Clip Space)
- 屏幕空间(Screen Space)
坐标系之间的转换过程如图所示:
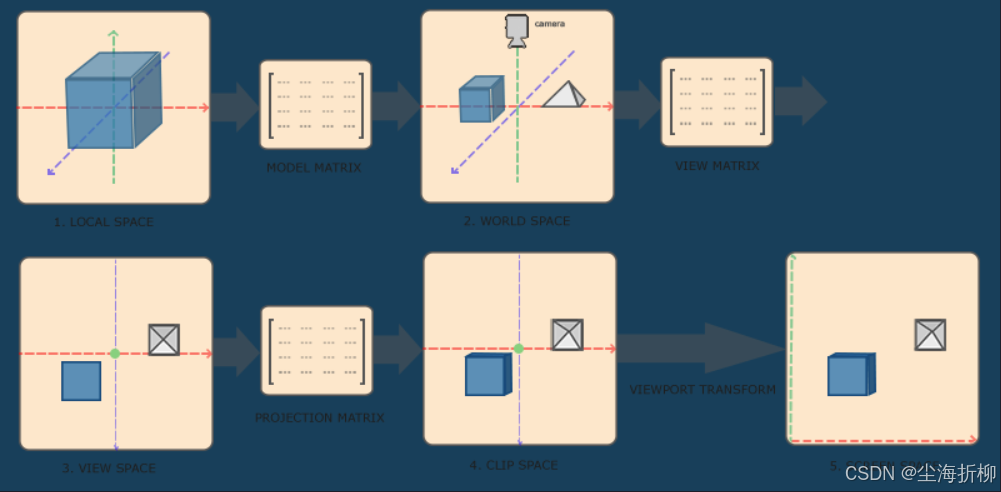
为了将坐标从一个坐标系变换到另一个坐标系,我们需要用到几个变换矩阵,最重要的几个分别是模型(Model)、观察(View)、投影(Projection)三个矩阵。我们的顶点坐标起始于局部空间(Local Space),在这里它称为局部坐标(Local Coordinate),它在之后会变为世界坐标(World Coordinate),观察坐标(View Coordinate),裁剪坐标(Clip Coordinate),并最后以屏幕坐标(Screen Coordinate)的形式结束。
- 局部坐标是对象相对于局部原点的坐标,也是物体起始的坐标。
- 下一步是将局部坐标变换为世界空间坐标,世界空间坐标是处于一个更大的空间范围的。这些坐标相对于世界的全局原点,它们会和其它物体一起相对于世界的原点进行摆放。
- 接下来我们将世界坐标变换为观察空间坐标,使得每个坐标都是从摄像机或者说观察者的角度进行观察的。
- 坐标到达观察空间之后,我们需要将其投影到裁剪坐标。裁剪坐标会被处理至-1.0到1.0的范围内,并判断哪些顶点将会出现在屏幕上。
- 最后,我们将裁剪坐标变换为屏幕坐标,我们将使用一个叫做视口变换(Viewport Transform)的过程。视口变换将位于-1.0到1.0范围的坐标变换到由glViewport函数所定义的坐标范围内。最后变换出来的坐标将会送到光栅器,将其转化为片段。
8问:冯氏光照模型((Phong Lighting Model)有哪几个分量组成?
答:冯氏光照模型的主要结构由3个分量组成:环境(Ambient)、漫反射(Diffuse)和镜面(Specular)光照组成。
- 环境光照(Ambient Lighting):即使在黑暗的情况下,世界上通常也仍然有一些光亮(月亮、远处的光),所以物体几乎永远不会是完全黑暗的。为了模拟这个,我们会使用一个环境光照常量,它永远会给物体一些颜色。
- 漫反射光照(Diffuse Lighting):模拟光源对物体的方向性影响(Directional Impact)。它是冯氏光照模型中视觉上最显著的分量。物体的某一部分越是正对着光源,它就会越亮。
- 镜面光照(Specular Lighting):模拟有光泽物体上面出现的亮点。镜面光照的颜色相比于物体的颜色会更倾向于光的颜色。
9问:常见的投光物(Light Caster)有哪几类?
答:常见的投光物包括定向光(Directional Light),点光源(Point Light)和聚光源(Spotlight)。
10问:绘制一个带有不透明和透明物体的场景,渲染顺序是什么?
答:渲染顺序为:
- 先绘制所有不透明的物体,从近到远。
- 对所有透明物体根据距离相机的远近进行排序。
- 按从远到近的顺序绘制所有透明的物体,从远到近。
11问:向量点乘和叉乘的应用分别有哪些?
答:向量点乘也叫点积,两个向量的点积(乘),记作 a · b。点积是个 标量 (普通的数,也称为 标量积)。
两个向量的点积等于两个向量的长度相乘再乘以两个向量夹角的余弦值
a · b = |a| |b| cosθ
其中:
|a| 是 矢量 a 的量值
|b| 是 矢量 b 的量值
θ 是 a 和 b 之间的 角度
点乘的应用:
- 判断朝向和计算方向:图形学中,点积用于光照模型、阴影计算、法线映射等,以及判断物体表面的朝向和计算反射方向。在近似镜面反射中,如果反射光的方向与人眼观察方向很接近,那么在一定的范围内可以观察到物体表面的高光。
- 计算角度:cosθ = (∥a∥∥b∥) / (a⋅b)
- 判断方向:根据cosθ的值进行判断:
如果 a · b 大于0小于1,说明夹角在0度到90度之间或270度与360度之间,即向量 a 与向量 b 是相同的方向
如果 a · b 等于0,说明cosθ =0,夹角是90度或270度,两个向量垂直
如果 a · b 小于0大于-1,说明夹角在90度到270度之间 (不包括180度),即向量 a 与向量 b 方向相反
如果 a · b 等于-1,说明夹角是180度,两个向量方向相反,如下图中向量 a 与向量 b2
向量叉乘也叫叉积,是一个矢量 是有量值(长度)和 方向。两个矢量的叉积 a × b 是与这两个矢量垂直的 矢量:
a × b = |a| |b| sin(θ) n
其中:
|a| 是 矢量 a 的量值 (长度)
|b| 是 矢量 b 的量值 (长度)
θ 是 a 和 b 之间的角度
n 是 与 a 和 b 垂直的 单位矢量
叉乘的应用:
判断一个向量在另一个的左侧还是右侧 :根据右手螺旋定则,把食指指着矢量 a 的方向,把中指指着矢量 b 的方向:拇指指着的方向便是叉积的方向。
如果向量 a 叉乘向量 b 的结果 > 0,右手旋转时时从 a 向量转向 b 向量,所以 b 向量在 a 向量的左侧,若叉乘结果< 0,则 b 向量在 a 向量的右侧。向量 a 叉乘向量 b > 0, b 向量在 a 向量的左侧向量 a 叉乘向量 b < 0, b 向量在 a 向量的右侧。
判断点和多边形的位置关系:在二维空间中,通过计算待判断点与多边形各边的向量叉乘,可以判断该点是否在多边形内部。如果点与各边的向量叉乘结果保持同号(全部大于0或全部小于0),则点在多边形内部。
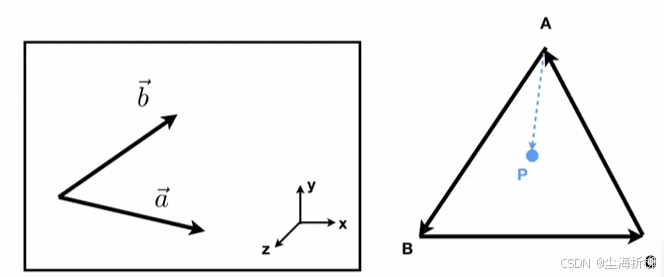
例如:按照一定顺序(例如逆时针)连接三角形的三条边,形成三个向量AB、BC、CA。要判断的点为 P。对于每个顶点,构造一个从该顶点指向待判断点P的向量。
计算AB×AP,如果结果大于0,则AP在AB的左侧;如果小于0则在右侧;如果等于 0,则共线。
同样计算BC×BP CA×CP。如果都在左侧则证明在三角形内。
12问:前向渲染与延迟渲染的区别是什么?
答:前向渲染步骤如下图所示:
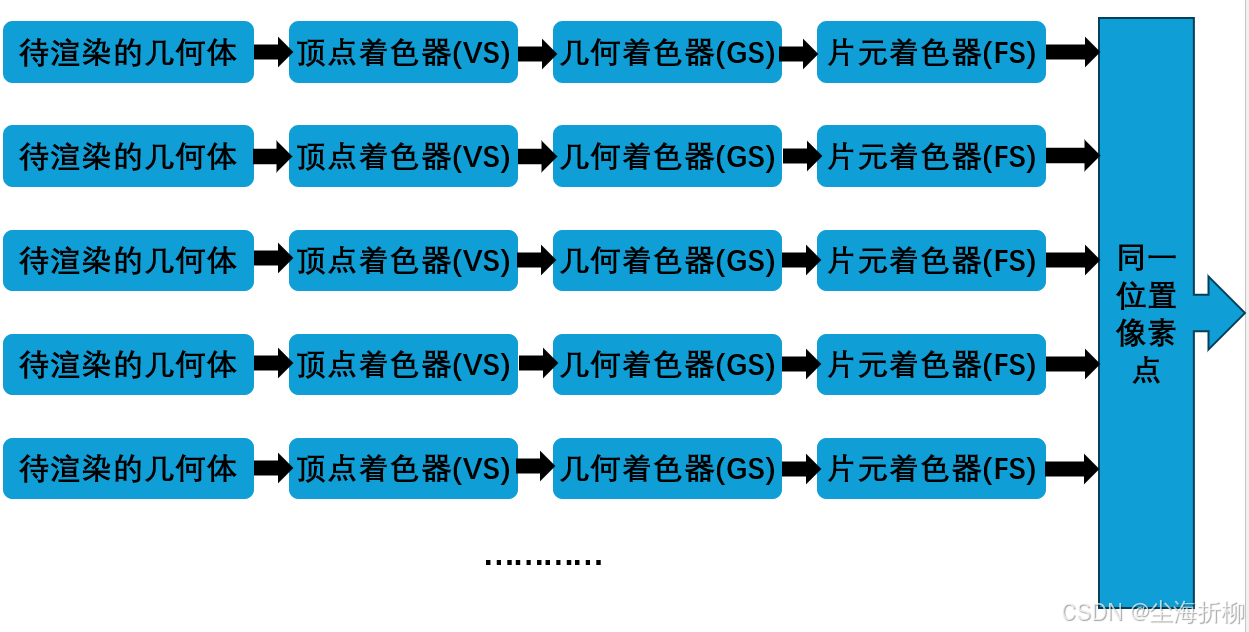
前向渲染是现在最基础,也是最多引擎使用的标准。前向渲染的流程是给定一个几何体,引擎对其进行从顶点到像素着色器的一系列计算,然后输出到最终的图像缓冲区。场景中有多个几何体时,引擎就是对其挨个进行渲染,完成一个再继续下一个 。
前向渲染的问题:
- 前向渲染有一个问题就是无效渲染太多,比如场景中有四个物体,互相之间存在叠压关系,按照前向渲染的流程,先前渲染了一个物体之后,它的一部分被后一个渲染的物体挡住了,那么被挡住的这部分就是无效的计算,毕竟我们在屏幕上是看不到这部分的。
- 另一个问题在于难以支持过多的光源,对于每个需要逐像素计算的光源,渲染一个几何体的时候需要逐个做一次光照计算。如果有一个场景,其中有10个几何体需要进行渲染,有四个光源对整个场景产生影响,那么渲染整个场景需要进行40次光照计算。而且其中还有很多的计算被挡住了。
前向渲染的优点:
- 如果需要在场景中使用多个着色模型,甚至是每个几何体都使用不同的着色模型和渲染技术,前向渲染是可以很好的支持的。
- 另外,因为前向渲染这种逐个渲染的特点,它非常适合渲染半透明物体。
延迟渲染步骤如下图所示:
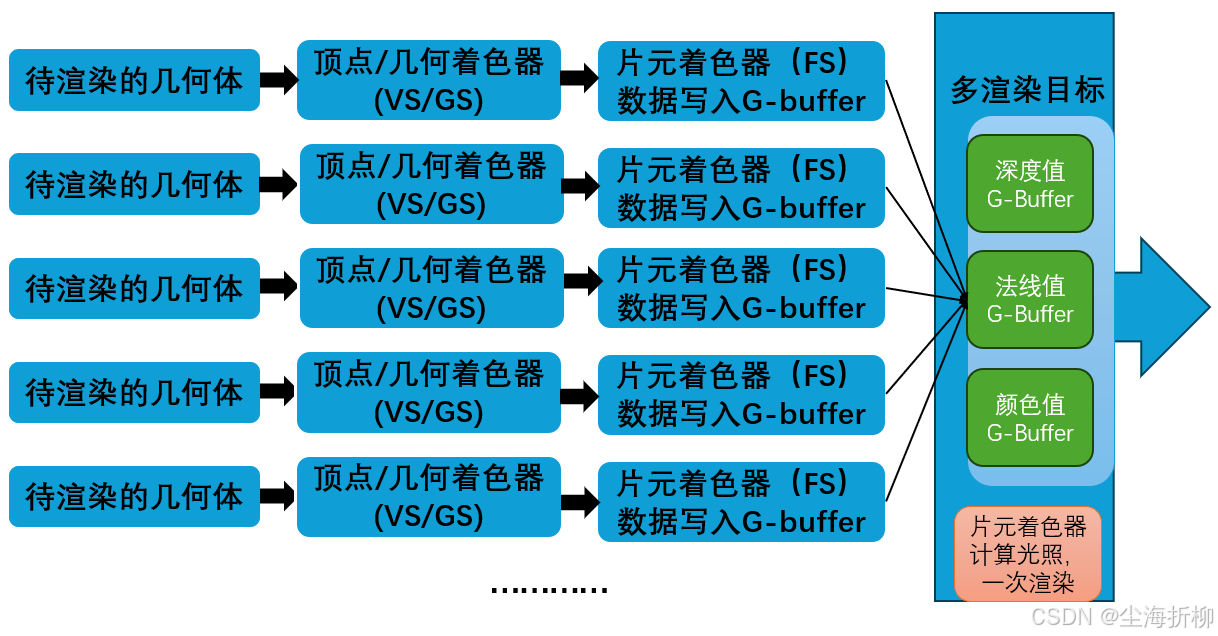
延迟渲染 (Deferred Rendering) 的主要特点是它首先将场景的几何信息和材料属性渲染到几个不同的纹理(称为G-buffer)中,然后在一个单独的步骤中计算最终的光照。这种方式允许它高效地处理场景中的大量光源。然而,这种方法在处理半透明物体时确实面临一些困难。
延迟渲染的优点:
当场景中所有几何体都写入G-Buffer之后,光照计算就和场景中有多少物体,多少三角形没有关系了。
延迟渲染不适合直接处理半透明物体的原因:
- G-buffer限制:延迟渲染需要将每个像素的材料属性存储在G-buffer中。这是基于每个像素的“最前面”的表面。半透明物体需要考虑多个表面的贡献,这使得在G-buffer中存储所有这些信息变得困难。
- 深度信息:G-buffer中的深度值通常仅存储最前面的表面深度。由于没有存储其他表面的深度信息,渲染半透明物体并考虑其与其他物体的混合关系变得困难。
- 混合问题:半透明物体需要进行混合运算来确定最终颜色。在延迟渲染的第一阶段(几何/材质阶段)中,我们并不真正计算最终的像素颜色,所以这一步无法处理混合。
- 性能考虑:即使在G-buffer中为半透明物体提供额外的存储空间,也会增加带宽和存储需求,从而可能导致性能下降。
13问:什么是draw call?
答:cpu向gpu提交一次绘制的图元(顶点)集合即为draw call。draw call太多就会让gpu反复切换渲染状态,cpu需要不断提交数据到gpu,降低帧数。减少draw call就要对需要绘制的图元进行合并,这样就要保证这些图元的渲染状态(材质)是一样的,且这些图元必须是在一起绘制的(中间不要插入别的材质的图元)。在creator中可使用图集合并工具如texture packer将sprite合并成到一张贴图上,并且安排节点的绘制顺序,将使用同一张贴图的节点放到一起绘制。
14问:顶点着色器和片元着色器的作用是什么?
答:顶点着色器:顶点着色器(Vertex Shader)在渲染管线中的作用非常大,是渲染管线的第一个可编.程着色器,处理单元是顶点数据。顶点着色器的主要功能是对坐标进行变换。将输入的局部坐标变换到世界坐标、观察坐标和裁剪坐标。除此之外当然也可以进行光照着色,但是着色效果远不如在片元着色器中进行光照着色,因为计算量较小。
片元着色器:片元着色器处理的对象将是像素点的颜色信息,也是最终显示在屏幕上的像素点,在这个过程中,可以处理光照和阴影计算,将处理完的值保存至缓冲区当中。
15问:锯齿或走样产生的原因和抗锯齿算法有哪些?
答:锯齿产生的原因:场景的定义在三维空间中是连续的,而最终显示的像素则是一个离散的二维数组,这是计算机屏幕产生锯齿的原因。在计算机处理图形的过程中,有一个非常重要的阶段,就是光栅化,光栅化主要的作用是将顶点数据的不连续性通过插值计算,将两个顶点之间不存在的点进行弥补,然后实现到屏幕像素点上的一一映射。
抗锯齿算法:
超级采样抗锯齿 (Super-Sampling Anti-aliasing),也叫SSAA,其原理比较好理解,就是直接“放大屏幕分辨率”。假设屏幕分辨率为800x600,那么4xSSAA会将屏幕渲染到1600x1200的缓冲区上,然后在下采样到800x600,SSAA可以得到非常好的抗锯齿效果,不过SSAA需要的计算量是非常大的,光栅化和片段着色器都是原来的4倍,渲染缓存的大小也是原来的4倍。4xSSAA就是放大4倍的意思。因为SSAA要浪费大量内存,因此基本没有大量应用。
多重采样抗锯齿 (Multi-Sampling Anti-aliasing),MSAA是对SSAA的改进,放弃了扩大像素分辨率,使用多重采样的方式,既然有多重采样,就有“单重采样”,而传统的采样方式就可以理解为“单重采样”,当然并不存在“单重采样”这个东西了。姑且这样叫它。“单重采样”就是一个像素点与一个采样点进行对应,而“多重采样”则是一个像素点与多个采样点进行对应。
覆盖采样抗锯齿(Coverage Sampling Anti-Aliasing,简称CSAA)是NVIDIA在G80及其衍生产品首次推向实用化的AA技术,也是目前NVIDIA GeForce 8/9/G200系列独享的AA技术。CSAA就是在MSAA基础上更进一步的节省显存使用量及带宽,简单说CSAA就是将边缘多边形里需要取样的子像素坐标覆盖掉,把原像素坐标强制安置在硬件和驱动程序预先算好的坐标中。这就好比取样标准统一的MSAA,能够最高效率的执行边缘取样,效能提升非常的显著。比方说16xCSAA取样性能下降幅度仅比4xMSAA略高一点,处理效果却几乎和8xMSAA一样。8xCSAA有着4xMSAA的处理效果,性能消耗却和2xMSAA相同。
FSAA(Fast Approximate AA)的核心思想是正常采样一个三角形,如果该三角形存在锯齿,则通过边缘检测查找出边界区域,然后使用没有锯齿的线段去替换有锯齿的边界,该方法和采样无关,因此速度很快。
TAA(Temporal AA):该方法的核心思想是复用上一帧渲染出的结果,并整合到本帧中,从时间上复用以前的计算结果,对于静止的图像优势明显。
16问:构建一个帧缓冲需要满足的条件有哪些?
答:需要满足的条件:
- 我们必须往里面加入至少一个附件(颜色、深度、模板缓冲)。
- 其中至少有一个是颜色附件。
- 所有的附件都应该是已经完全做好的(已经存储在内存之中)。
- 每个缓冲都应该有同样数目的样本。
17问:三种旋转表示(四元数,欧拉角,矩阵)各自的优缺点是什么?
答:欧拉角:非常直观,我们可以很容易理解它的意思,也能想象出对应的空间位置,但是存在万向锁现象,导致后面有很多数学问题。
旋转矩阵:旋转矩阵有9个元素,计算繁杂,尤其是求微分时,而且也不直观。
四元数:没有奇点,能表征任何旋转关系,而且表示简单,只有四个元素,计算量小,但是不直观。
18问:裁剪测试有哪些可配置的属性参数?
答:裁剪一种提高渲染性能的方法,是只刷新屏幕上发生变化的部分。我们可能还需要将 OpengGL 渲染限制在窗口中一个较小的矩形区域(剪裁框)中。裁剪测试 是片元可见性判断的第一个附加测试。 默认情况下,剪裁框与窗口同样大小,并且不会进行 裁剪测试。我们可以使用几乎处处都会用到的 glEnable 函数开启裁剪测试,glDisable关闭裁剪测试。
glEnable(GL_SCISSOR_TEST);// 开启裁剪测试
glDisable(GL_SCISSOR_TEST);// 关闭裁剪测试剪裁框可以通过下面的函数设置位置与大小:
void glScissor(Glint x,Glint y,GLSize width,GLSize height);参数 x,y: 指定裁剪框左下⻆的点位置 (x,y);
参数 width , height:指定裁剪的宽和高
19问:阴影渲染的原理是什么?阴影渲染会有哪些问题?
答:阴影绘制的实现基础是Shadow Map算法,Shadow Map的绘制过程如下:
将物体顶点数据通过矩阵运算转移到灯光空间下。从局部空间转移到世界空间,在转移到灯光空间下,对于不同的灯光,有着不同的投影矩阵,这里涉及两种投影方式:正交投影和透视投影。两种投影方式分别对应着不同的投影矩阵及视觉效果:正交投影往往应用于2D游戏中,透视投影应用于3D游戏.中,但并不绝对。在灯光坐标下渲染物体阴影:
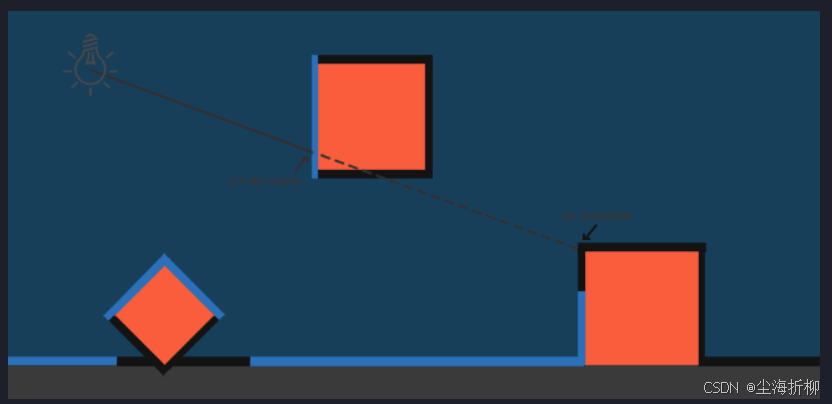
在灯光空间下创建一张深度纹理贴图,用于保存物体在灯光空间下的深度信息,此深度贴图则是摄像机的渲染目标。灯管空间下的物体深度信息将被保留在该深度贴图中。
渲染深度贴图的过程比较简单,首先在该视口下的顶点信息进行判断,如果某个顶点的深度值比深度贴图中的值小,就更新贴图数据,反之丢弃掉该数据,直到遍历一遍所有像素点为止。遍历完成后,便得到了深度信息图。
获取到深度贴图后,如果某个点在光源视角下的深度值大于深度贴图中对应位置的深度值,就说明它被某个物体遮挡,因此是在阴影中的;反之,深度值小于深度贴图中的值,则不在阴影之中。
判断完成该顶点是否需要接收阴影后,需要做的最后一步就是对该顶点乘上阴影的颜色,遍历完一遍该物体的所有顶点后,便可得到该物体接收阴影的效果。
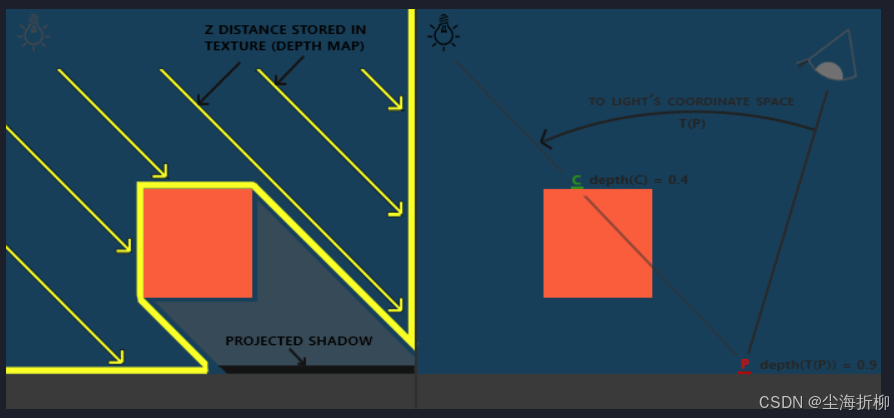
存在问题:
阴影失真:现象:明显的线条样式;原因:阴影贴图受限于分辨率,在距离光源比较远的情况下,多个片段可能从深度贴图的同一个值中去采样,解决办法:根据表面朝向光线的角度更改偏移量,通过使用点乘方式。
悬浮:现象:物体看起来轻轻悬浮在表面之上,原因:使用阴影偏移的一个缺点是你对物体的实际深度应用了平移。偏移有可能足够大,以至于可以看出阴影相对实际物体位置的偏移。解决办法:使用正面剔除;
采样过多:现象:光的视锥不可见的区域一直处于阴影中,原因:超出光的视锥的投影坐标比1.0大,这样采样的深度纹理就会超出他默认的0到1的范围。根据纹理环绕方式,我们将会得到不正确的深度结果,它不是基于真实的来自光源的深度值。解决办法:第一步:可以储存一个边框颜色,然后把深度贴图的纹理环绕选项设置为GL_CLAMP_TO_BORDER,第二步:投影向量的z坐标大于1.0,我们就把shadow的值强制设为0.0。
20问:PCF是为了解决什么问题?
深度贴图有一个固定的分辨率,多个片段对应于一个纹理像素。结果就是多个片段会从深度贴图的同一个深度值进行采样,这几个片段便得到的是同一个阴影,这就会产生锯齿边。
解决方案叫做PCF(percentage-closer filtering),这是一种多个不同过滤方式的组合,它产生柔和阴影,使它们出现更少的锯齿块和硬边。核心思想是从深度贴图中多次采样,每一次采样的纹理坐标都稍有不同。每个独立的样本可能在也可能不再阴影中。所有的次生结果接着结合在一起,进行平均化,我们就得到了柔和阴影。
一个简单的PCF的实现是简单的从纹理像素四周对深度贴图采样,然后把结果平均起来。
21问:编写一个PBR材质需要哪些纹理参数?
答:在一个PBR渲染管线当中经常会遇到的纹理列表如下:

反照率:反照率(Albedo)纹理为每一个金属的纹素(Texel)(纹理像素)指定表面颜色或者基础反射率。这和漫反射纹理相当类似,不同的是所有光照信息都是由一个纹理中提取的。漫反射纹理的图像当中常常包含一些细小的阴影或者深色的裂纹,而反照率纹理中是不会有这些东西的。它只包含表面的颜色(或者折射吸收系数)。
法线:法线贴图纹理使我们可以逐片段的指定独特的法线,来为表面制造出起伏不平的假象。
金属度:金属(Metallic)贴图逐个纹素的指定该纹素是不是金属质地的。根据PBR引擎设置的不同,既可以将金属度编写为灰度值又可以编写为1或0这样的二元值。
粗糙度:粗糙度(Roughness)贴图可以以纹素为单位指定某个表面有多粗糙。采样得来的粗糙度数值会影响一个表面的微平面统计学上的取向度。一个比较粗糙的表面会得到更宽阔更模糊的镜面反射(高光),而一个比较光滑的表面则会得到集中而清晰的镜面反射。某些PBR引擎预设采用的是更加直观的光滑度(Smoothness)贴图而非粗糙度贴图,这些数值在采样之时就马上用(1.0 – 光滑度)转换成了粗糙度。
AO:环境光遮蔽(Ambient Occlusion)贴图或者说AO贴图为表面和周围潜在的几何图形指定了一个额外的阴影因子。比如如果我们有一个砖块表面,反照率纹理上的砖块裂缝部分应该没有任何阴影信息。然而AO贴图则会把那些光线较难逃逸出来的暗色边缘指定出来。在光照的结尾阶段引入环境遮蔽可以明显的提升你场景的视觉效果。网格/表面的环境遮蔽贴图要么通过手动生成,要么由3D建模软件自动生成。
22问:基于物理的渲染(Physically Based Rendering)需要满足哪些条件?
答:需要满足下面三个条件:
- 基于微平面(Microfacet)的表面模型。
- 能量守恒。
- 应用基于物理的BRDF



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











