





 本文介绍如何在CDH6.2.0集群中使用Solr7对多种格式的文件建立全文索引,涵盖创建Collection、配置文件修改、索引建立及测试等内容。
本文介绍如何在CDH6.2.0集群中使用Solr7对多种格式的文件建立全文索引,涵盖创建Collection、配置文件修改、索引建立及测试等内容。
文档编写目的
Solr是一个开源搜索平台,用于构建搜索应用程序。它建立在Lucene(全文搜索引擎)之上。Solr是企业级的,快速的和高度可扩展的。使用Solr构建的应用程序非常复杂,可提供高性能 。它提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式),并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。Solr7要求JDK为1.8以上。在Solr7版本中新增了跨核(solr 跨核概念,是建立在solr存储方式的基础上,因为使用solr前必须创建Core,Core即为solr的核,那不同的业务有可能在不同的核中,之前版本是不支持跨核搜索的)搜索功能。本文主要介绍如何在CDH6.2.0集群中使用Solr7对多种格式的文件建立全文索引。
- 内容概述
1.创建Collection
2.建立索引
3.总结
- 测试环境
1.CM和CDH版本为6.2.0
2.Solr版本为7.4.0
3.集群未启用kerberos
4.采用root用户
- 前置条件
1.CDH集群已安装成功并正常运行
2.集群已添加Solr服务
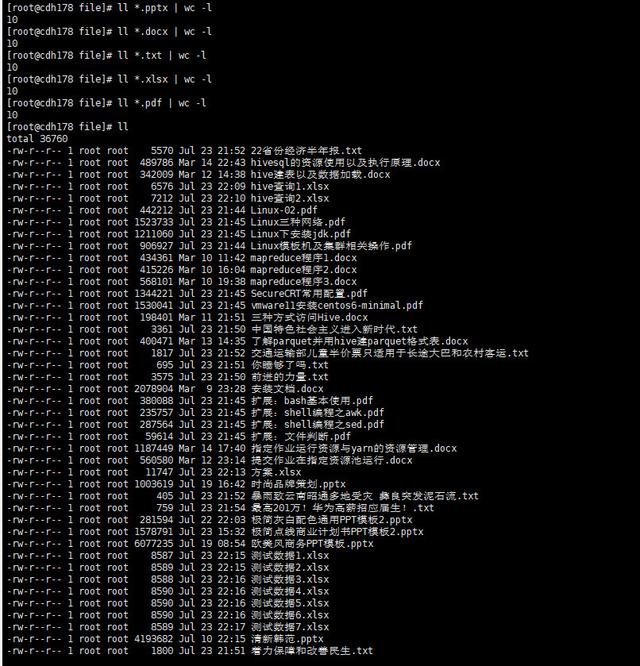
3.准备好测试使用的多种类型的文件,pdf、word、text、excel、ppt各十个如下
创建Collection
2.1 创建Config模板
在/opt/cloudera/parcels/CDH/lib/solr目录下,使用如下命令创建一个自己的Config模板。本次创建模板名称为testcoreTemplate
solrctl config --create testcoreTemplate managedTemplateSecure -p immutable=false模板创建完成后,需要生成模板配置文件
在当前目录执行如下命令在本地生成testcoreTemplate模板的配置文件
solrctl instancedir --generate testcoreTemplate
2.2 修改配置文件
1.solrconfig.xml文件
solrconfig.xml配置文件主要定义了Solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。相当于是基础配置文件。
注意:该文件中不能有中文,否则会报错,注释也不行
在testcoreTemplate/conf目录下,修改配置文件solrconfig.xml
添加数据源配置,如下所示:
tika-data-config.xmlexplicit10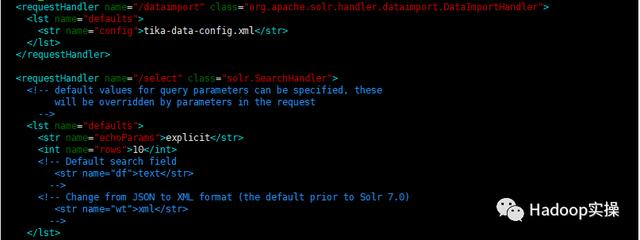
2.tika-data-config.xml文件(该文件可自定义名称)
tika-data-config.xml是数据源文件。该文件不存在,需要自己手动创建。其中dataConfig 标签中,子标签dataSource 配置数据源,entity 标签 定义了 操作名称。
在当前目录下创建数据源文件tika-data-config.xml,与solrconfig.xml文件在同级目录下。
然后添加如下内容:
<?xml version="1.0" encoding="UTF-8" ?>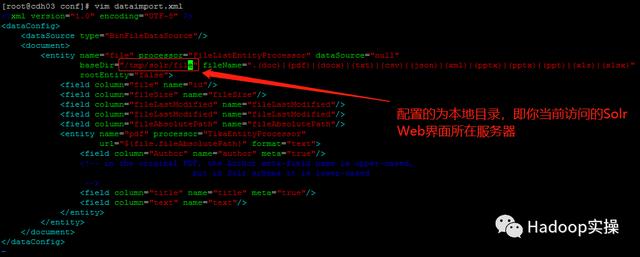
3.managed-schema文件。
managed-schema配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,老版本的schema配置文件的名字叫做schema.xml,配置方式就是手工编辑,5.0以后的版本的schema配置文件的名字叫做managed-schema,配置方式不再是用手工编辑而是使用schemaAPI来配置,官方给出的解释是使用schemaAPI修改managed-schema内容后不需要重新加载core或者重启solr,更适合在生产环境下维护。如果使用手工编辑的方式更改配置不进行重加载core有可能会造成配置丢失。
修改managed-schema文件
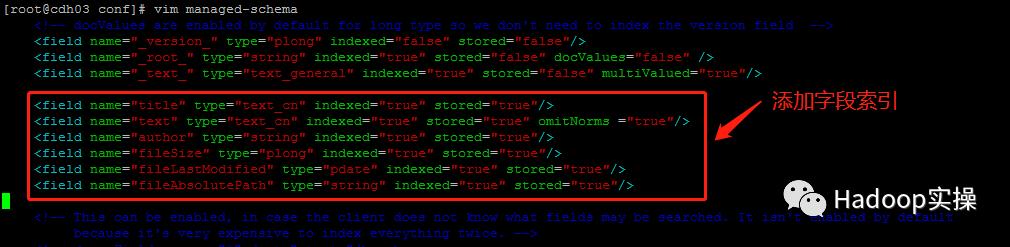
1)添加索引字段
其中field是创建索引用的字段,如果想要这个字段生成索引需要配置他的indexed属性为true,stored属性为true表示存储该索引。
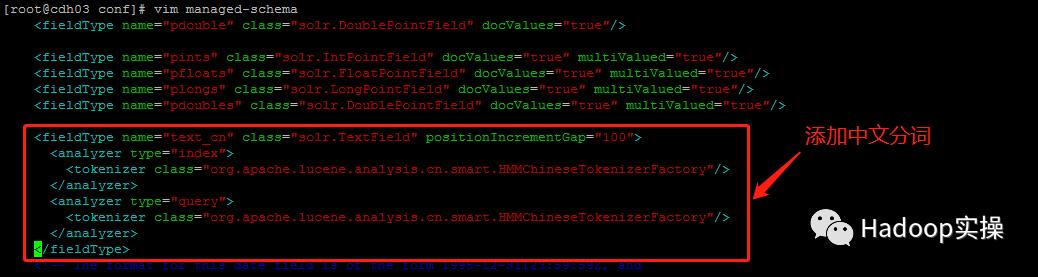
2)配置中文分词
fieldType:为field定义类型,最主要作用是定义分词器,分词器决定着如何从文档中检索关键字。
analyzer:fieldType下的子元素,这就是分词器,由一组tokenizer和filter组成,如下图所示
修改了自定义模板配置后,保存配置,然后在目录/opt/cloudera/parcels/CDH/lib/solr下执行下面的命令将配置更新到solr
solrctl instancedir --update testcoreTemplate testcoreTemplate2.3 准备jar包
在所有节点创建目录/opt/cloudera/parcels/CDH/lib/solr/contrib/extraction/lib

下载以下几个jar包
lucene-analyzers-smartcn-7.4.0-cdh6.2.0.jar下载地址:
https://archive.cloudera.com/cdh6/6.2.0/maven-repository/org/apache/lucene/lucene-analyzers-smartcn/7.4.0-cdh6.2.0/lucene-analyzers-smartcn-7.4.0-cdh6.2.0.jarsolr-dataimporthandler-7.4.0.jar下载地址:
https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.4.0/solr-dataimporthandler-extras-7.4.0.jarsolr-dataimporthandler-extras-7.4.0.jar下载地址:
https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.4.0/solr-dataimporthandler-extras-7.4.0.jartika-app-1.19.1.jar(版本要求1.19以上)下载地址:
https://repo1.maven.org/maven2/org/apache/tika/tika-app/1.19.1/tika-app-1.19.1.jar
将lucene-analyzers-smartcn-7.4.0-cdh6.2.0.jar拷贝到所有节点的/opt/cloudera/parcels/CDH/lib/hadoop-yarn目录和/opt/cloudera/parcels/CDH/lib/solr/server/solr-webapp/webapp/WEB-INF/lib/目录
将solr-dataimporthandler-7.4.0.jar、solr-dataimporthandler-extras-7.4.0.jar和tika-app-1.19.1.jar三个jar包拷贝到集群所有节点的/opt/cloudera/parcels/CDH/lib/solr/contrib/extraction/lib/目录

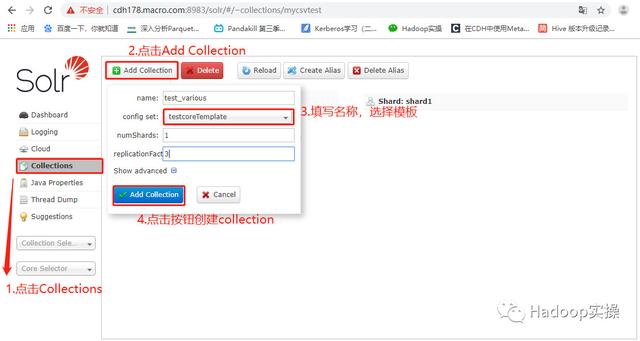
2.4 创建collection
在Solr Web页面,选择左侧的【Collections】,然后单击【Add collection】。创建一个Collection
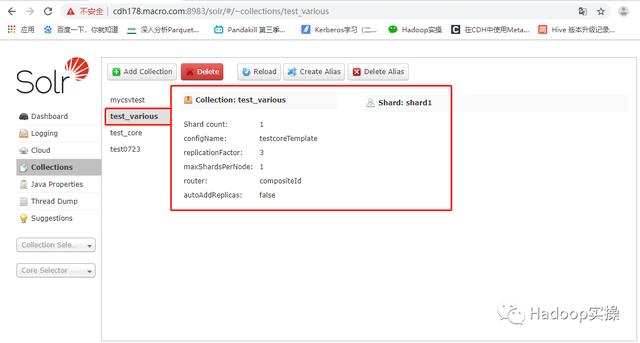
Collection创建成功
建立索引并测试
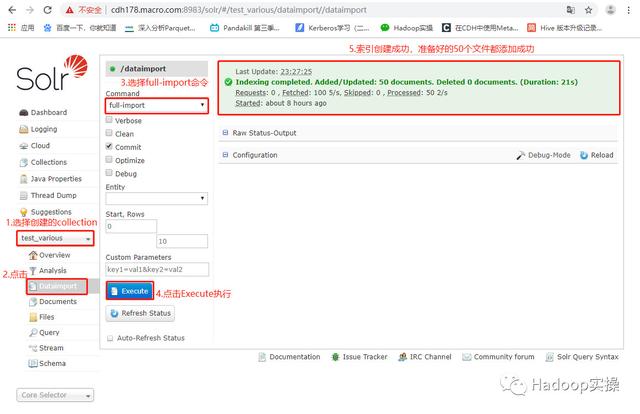
3.1 创建索引
浏览器登录Solr Web UI,默认端口为8983。
选择创建好的collection,点击模板下的【dataimport】菜单,选择【full-import】命令,然后单击下方的【Execute】,将本地的50个数据文件导入到solr并创建index
3.2 查询测试
1.查找文件名
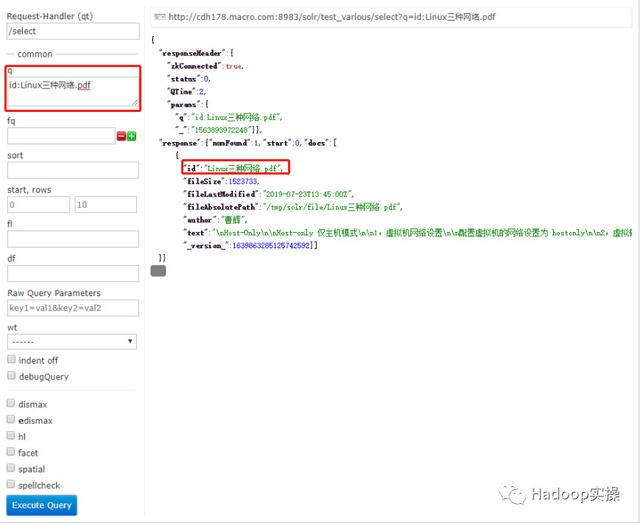
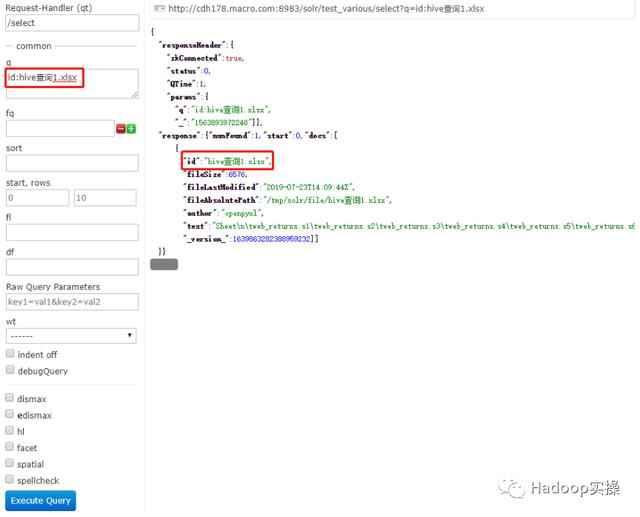
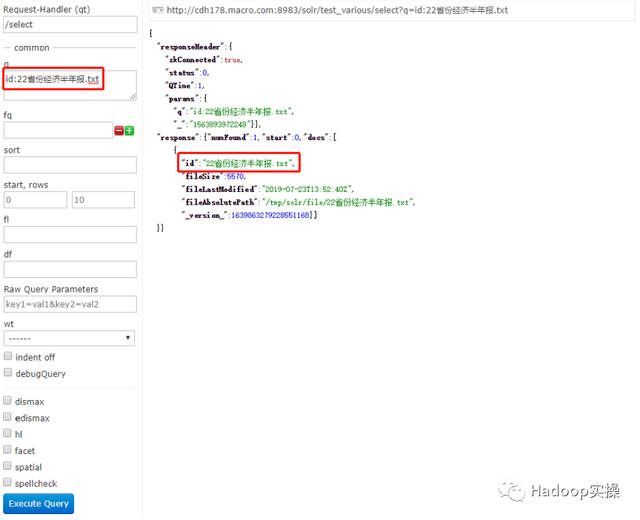
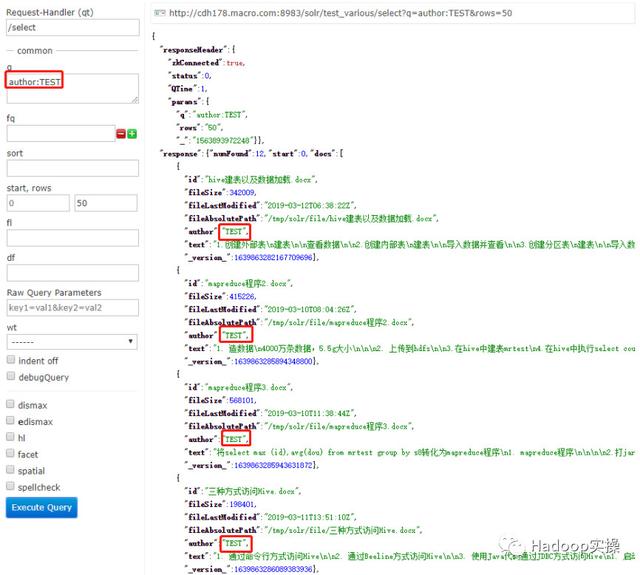
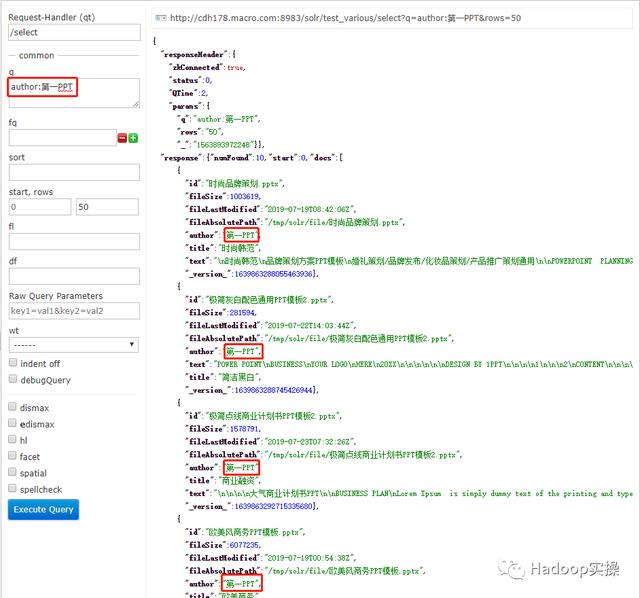
2.查找文件作者
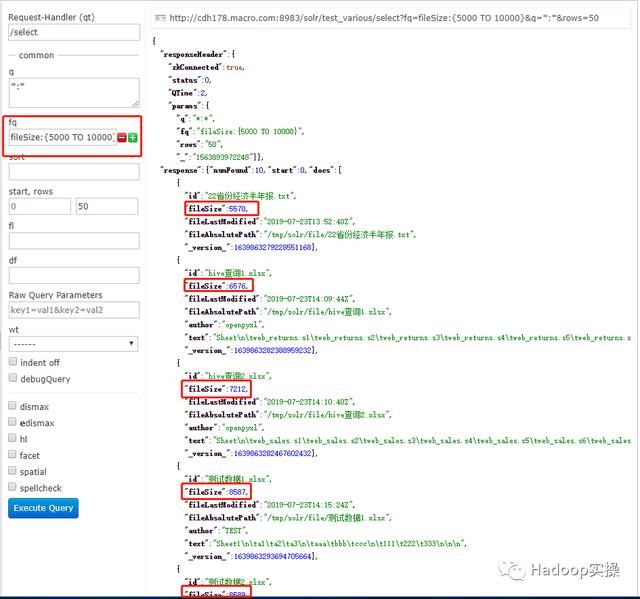
3.按文件大小范围查找,例如5000-10000
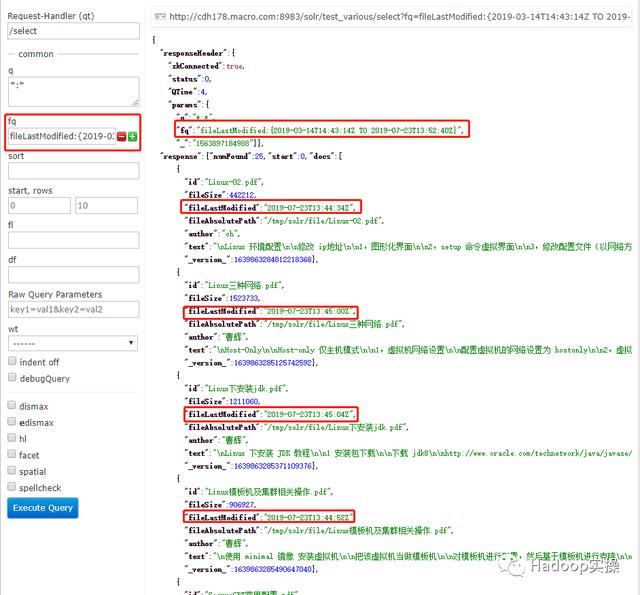
4.按时间范围查找
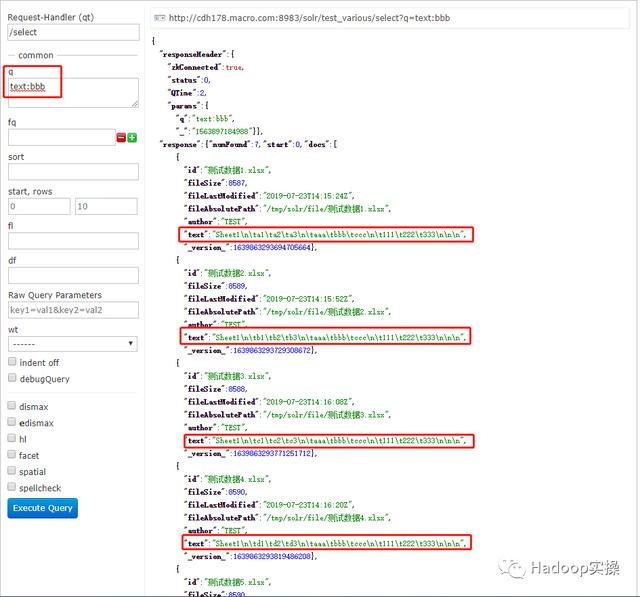
5.按文件内容查找
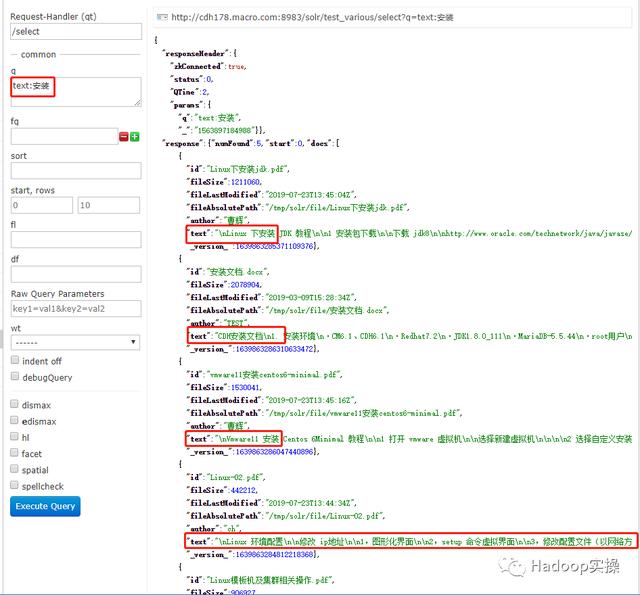
由以上测试可见,solr对pdf、word、text、excel、ppt文件都能够建立索引,并且在配置了中文分词之后,可以对中英文进行检测。
总结
1.Solrcloud需要利用公共的Zookeeper保持所有的Solr主机的注册信息(将每一个core中的conf目录的内容进行公共存储)。一旦搭建了Solrcloud集群,那么所有的数据的操作都将以Collection为主,在一个Collection下可以有若干个Shard(分片),而后每一个分片上都会有Core(每一个Core都会存在有主从关系)。这些Collection、Shared、Core的分片的信息都会自动的在Zookeeper上进行存储。对于整体的Solr而言,需要提供统一的认证信息,这些信息也需要保持在Zookeeper上。
2.Solr7中自带了一些中文分词器,比较好用的是SmartChineseAnalyzer。但是本次测试时失败,所以额外又下载一个中文分词包lucene-analyzers-smartcn-7.4.0-cdh6.2.0.jar,看网上很多成功示例不需要下载,可能某一部分操作失误所致,后续再验证。
3.如果由于配置文件异常导致Solr功能使用异常时,可以将自定义的模板删除
solrctl config --delete testcoreTemplatesolrctl instancedir --delete testcoreTemplate4.tika-app-1.19.1.jar可以支持Solr对pdf、word、text、excel、ppt等格式文件建立索引。
5.在将需要的jar包下载到执行目录下后,需要对solr服务进行重启,否则jar包不会生效,运行时会报错找不到jar包中的类。
在对自定义模板的配置进行更新后,需要使用命令来将模板的配置更新到solr中去,
solrctl instancedir --update testcoreTemplate testcoreTemplate
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









