





第五章:图(图的存储方法)
1.邻接矩阵法
下面是一个无向图的表示,我们使用一个一维数组存放点集,使用一个二维数组存放边集
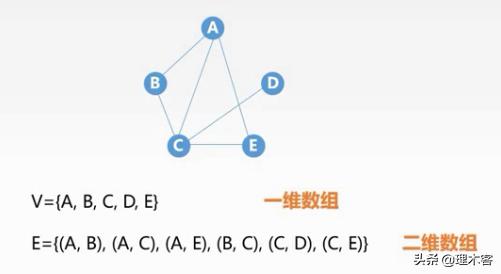
二维数组表示边:行号表示其实端点,列号表示结束端点,值表示该边是否存在,以及该边的权重,我们称这种二维数组表示的矩阵为邻接矩阵
邻接矩阵法:- 结点数为n的图G=(V,E)的邻接矩阵A是n*n的(每个行号表示一个结点每个列号表示一个结点,n个结点即为n*n)- 将G的顶点编号为 V1,V2,V3......Vn (1,2,3.....数组下标)- 若 存在,则A[i][j]=1,否则A[i][j]=0
注意有向边和无向边是不一样的,有向边 Vi---->Vj,则存放A[i][j]=1,若无向边Vi-------Vj,则存放A[i][j]=1、A[j][i]=1 .
有向图邻接矩阵:
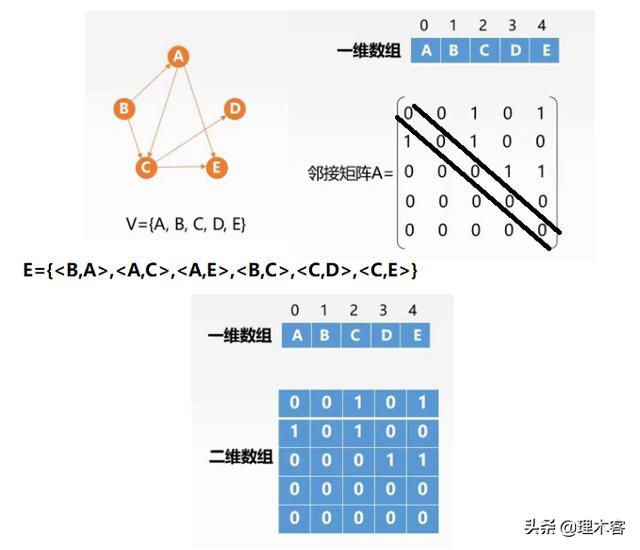
无向图邻接矩阵:(关于对角线对称)
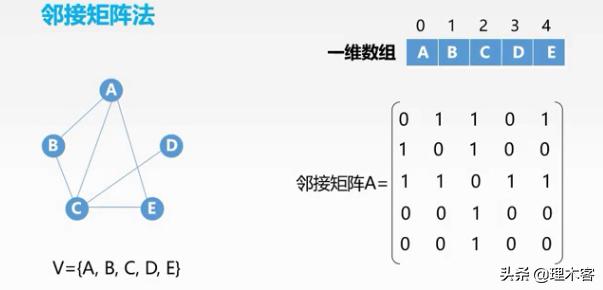
有权重的图:

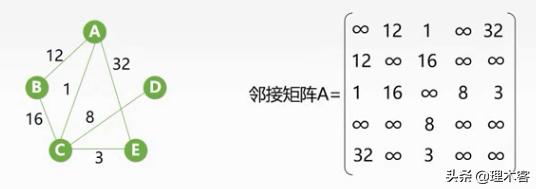
有向边 Vi---->Vj,则存放A[i][j]=Wi,j,若无向边Vi-------Vj,则存放A[i][j]=Wi,j、A[j][i]=Wi,j .
网转邻接矩阵
语言实现
#define MaxvertexNum 100 typedef char VertexType; //每个结点时字符型的(类型可自行调整)typedef int EdgeType; //可表示便是否存在、边的权重(类型可以自行调整)typedef struct{ VertexType Vex[MaxVertexNum];//点集数组 EdgeType Edge[MaxVertexNum][MaxVertexNum];//边集数组 int vexnum,arcnum;//结点的数量和边的数量}MGraph;邻接矩阵法的空间复杂度位O(n^2)
2.邻接矩阵性质

性质1:邻接矩阵法的空间复杂度为O(n^2),适用于稠密图
因为无论该边是否存在,我们都会为其申请空间,所以稠密图也就是边越多的图它的空间利用率也就越高
性质2:无向图的邻接矩阵为对称矩阵
性质3:无向图中第 i 行(或第 i 列)非0元素(非正无穷)的个数为第 i 个顶点的度;有向图中第 i 行(第 i 例)非0元素(非正无穷)的个数为第 i 个顶点的出度(入度)
设图G的邻接矩阵为A,矩阵运算A^n的含义??
我们先看A^2,首先两个矩阵,我们知道A^2[2][5]=1*1+0*0+1*1+0*0+0*0=2
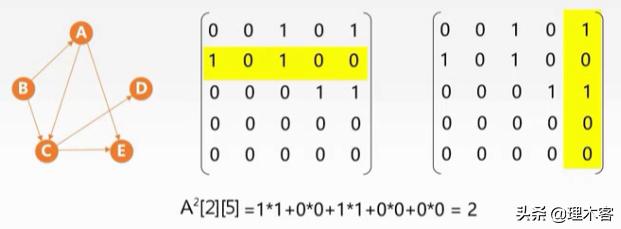
首先第一个1*1:第一个1代表B->A,第二个1代表A->E,相乘代表B->E存在一条B->A->E的路径,第二个1*1:第一个1代表B->C,第二个1代表C->E,相乘代表B->E存在一条:B->C->E的路径。
所以:A^2[2][5]=2表示从顶点V2(B)到顶点V5(E)长度为2的路径有两条。(长度为2因为是的A方,两条是因为值为2)
现在我们再看A^3,首先两个矩阵,一个是A^2,一个是A
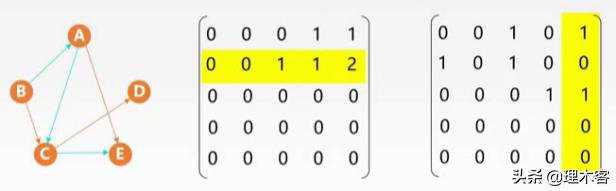
则:A^3[2][5]=0*0+0*0+1*1+1*0+2*0=1,首先我们知道A^2[2][3]=1表示从顶点V2->V5长度为2的路径只有一条,则A^3[2][5]=1表示从顶点V2到顶 点V5长度为3的路径只有一条
综上我们可知A^n[i][j]表示从顶点vi到顶点Vj长度为n的路径的条数
2.邻接矩阵表
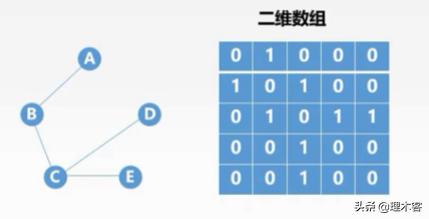
上面讲解了邻接矩阵法,对于上面的稀疏图,我们如果采用邻接矩阵法存储的话,会出现很多空间的浪费即
邻接矩阵法存储稀疏图会有许多空间浪费 ,对于稀疏图我们通常采用邻接表法存储
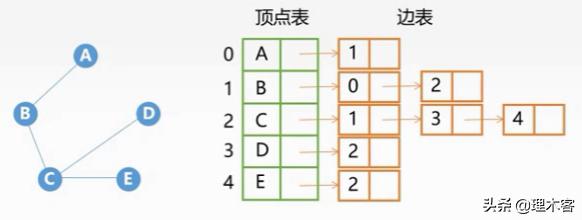
邻接表法:为每一个顶点建立一个单链表存放与它相邻的边- 顶点表:采用顺序存储,每个数组元素存放顶点的数据和边表的头指针- 边表(出边表):采用链式存储,单链表中存放与一个顶点相邻的所有边,一个链表结点表示一条从该顶点到链表结点顶点的边

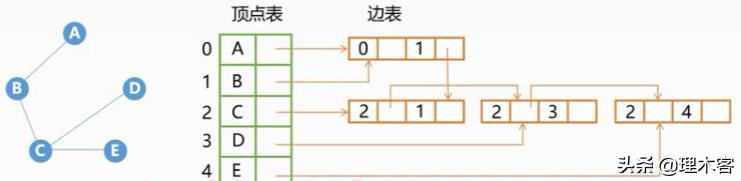
3.邻接表法
有向图:
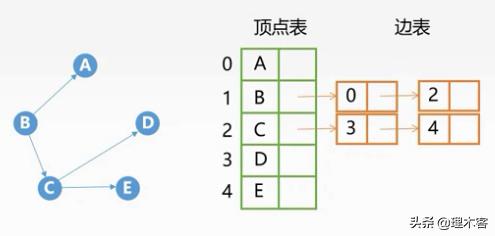
无向图:
代码实现
#define MaxVertexNum 100 //边表typedef struct ArcNode{ int adjvex; //下一个结点的下标 struct ArcNode *next;//指针指向下一个边表结点 //InfoType info; //表的权重}ArcNode;//顶点表typedef struct VNode{ VertexType data;//数据 ArcNode *first //指向属于它的边表的头指针}VNOode,AdjList [MaxVertexNum];//数组类型//邻接表typedef struct{ AdjList vetices;//顶点表 int vexnum,arcnum;//顶点数量和边的数量}ALGraph;‘邻接表特点
V表示顶点数量、E表示边的数量
- 若G为无向图,存储空间为O(V+2E)
- 若G为有向图,存储空间为O(V+E)
- 邻接表更加适用于稀疏图
- 若G为无向图,则结点的度为该结点边表的长度
- 若G为有向图,则结点的出度为该结点边表的长度,计算入度则要遍历整个邻接表
- 邻接表不唯一,边表结点的顺序根据算法和输入的不同可以能会不同
4.邻接矩阵VS邻接表

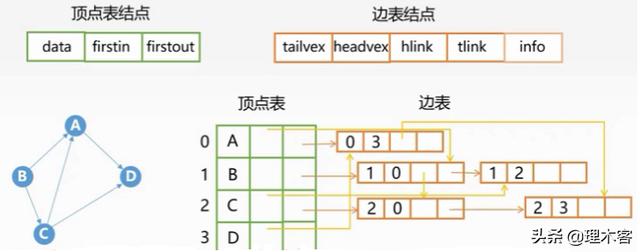
5.十字链表
·十字链表:有向图 的一种链式存储结构
我们在邻接表中可以发现,如果寻找一个结点的出度,非常方便,直接遍历该节点的边表即可,但是如果想找一个结点的入度则需要遍历整个邻接表比较复杂,所以我们引入了十字链表,它无论是查询结点的出度和入度都比较简单。
顶点表结点
data:数据域
firstin:入边单链表的头指针
firstout:出边单链表的头指针
边表结点
tailvex:该弧弧尾端点
headvex:该弧弧头端点
hlink:下一个弧弧头的指针
tlink:下一个弧弧尾的指针
info:边的权重
代码实现
#define MaxVertexNum 100 typedef struct ArcNode{ int tailvex,headvex; struct ArcNode *hlink,*tlink; //InfoType info: }ArcNode; typedef struct VNode{ VertexType data; ArcNode *firstin,*firstout; }VNode;typedef struct{ VNode xlist[MaxVertexNum]; int vexnum, arcnum; }GLGraph;6.邻接多重表
上面讲的·十字链表是 有向图 的一种链式存储结构,而邻接多重表则是针对无向图的一种链式存储结构。
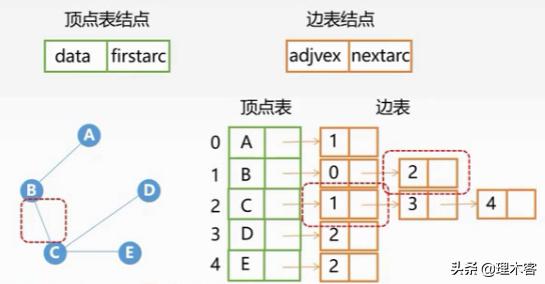
我们在邻接表中如果想要删除一条无向边,我们需要找到对应的结点,然后遍历其边表,找到对应的边表结点并把它删除,这样操作的效率比较低。由此引出邻接多重表
ivex:该边的第一个端点ilink:与第一个端点相邻的下一个边的边表结点的指针jvex:该边的第二个端点jlink:与第二个端点相邻的下一个边的边表结点的指针info:权重(不必要)mark:标记(不必要)
#define MaxVertexNum 100 typedef struct ArcNode{ int ivex, jvex; struct ArcNode *ilink, *jlink; //InfoType info; //bool mark: }ArcNode;typedef struct VNode{ VertexType data; ArcNode *firstedge; )VNode;typedef struct{ VNode adjmulist[MaxVertexNum]; int vexnum, arcnum; }AMLGraph;7.理木客
数据结构相关知识,公众号理木客同步更新中,欢迎关注



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









